OpenStack数据库服务Trove解析与实践
对于公有云计算平台来说,只有计算、网络与存储这三大服务往往是不太够的,在目前互联网应用百花齐放的背景下,几乎所有应用都使用到数据库,而数据库承载的往往是应用最核心的数据。此外,在大数据分析越来越盛行的背景下,对数据库的可靠便捷管理也变得更为重要。因此,DBase as a Service(DBaaS,数据库服务)也就顺理成章地成为了云计算平台为用户创造价值的一个重要服务。
对比Amazon AWS中各种关于数据的服务,其中最著名的是RDS(SQL-base)和DynamoDB(NoSQL),除了实现了基本的数据管理能力,还具备良好的伸缩能力、容灾能力和不同规格的性能表现。因此,对于最炙手可热的开源云计算平台Openstack来说,也从Icehouse版加入了DBaaS服务,代号Trove。直到去年底发布的Openstack Liberty版本,Trove已经经过了4个版本的迭代发布,目前已经成为Openstack官方可选的核心服务之一。本文将深入介绍Trove的原理、架构与功能,并通过实践来展示Trove的应用。
Trove的设计目标
“Trove is Database as a Service for OpenStack. It’s designed to run entirely on OpenStack, with the goal of allowing users to quickly and easily utilize the features of a relational or non-relational database without the burden of handling complex administrative tasks. ”这是Trove在官方首页上对这个项目的说明,有两个关键点。一个是从产品设计上说,它定位不仅仅是关系型数据库,而且还涵盖非关系数据库的服务。另一个是从产品实现上说,它是完全基于Openstack的。
从第一点可以看出Trove解决问题的高度已经超越了同类产品。因为我们从其他云计算平台对比去看,关系型和非关系型数据库都是由不同的服务去提供(比如AWS的RDS和DynamoDB),而且实现上也往往互相独立的系统,不仅UI不同,API也不一样。而Trove的目标是抽象尽可能多的东西,对外提供统一的UI和API,尽量减少冗余实现,提升平台内聚。只要具备了实例、数据库、用户、配置、备份、集群、主从复制这些概念,不管是关系型还是非关系型数据库,都能统一管理起来。从最新的Liberty版本发布的情况下,目前开源的主流关系型和非关系型数据库也得到了支持,比如Mysql(包括Percona和MariaDB分支)、Postgresql、Redis、MongoDB、CouchDB、Cassandra等等。不过根据官方的介绍,目前只有Mysql是得到了充分的生产性测试,其他的还处于实验性阶段。
而第二点完全基于Openstack的,可以说是一个较大的创新。试想,假设你是一个云计算服务商,如果现在要提供数据库服务,只需要在原有平台软件上升级与配置一下就行,其他什么都不需要,不需要采购数据库服务器硬件,不需要规划网络,不需要规划IDC,这是一种什么样的感觉?Trove完全构建于Openstack原有的几大基础服务之上。打个比喻类似于Google著名的Bigtable服务是构建于GFS、Borg、Chubby等几个基础服务之上。所以,Trove实际上拥有了云平台的一些基础特性,比如容灾隔离、动态调度、快速响应等能力,而且从研发的角度看,也大大减少了重复造轮子的现象。

Trove的架构介绍
实际上Trove的架构(最新版本)与Openstack Nova项目的架构是如出一辙,可以说是Nova的一个简化版。也是典型的Openstack项目架构风格。Trove所管理的各个数据库引擎的差异性主要体现在trove-guestagent的具体manager和strategies代码实现上。架构如图所示:
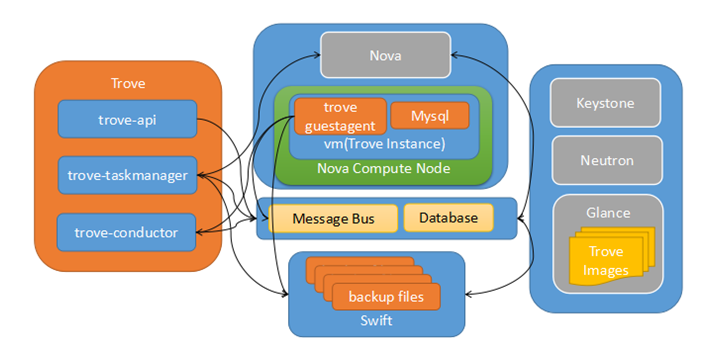
trove-api是接入层,轻量级请求通过在接入层直接处理或者通过直接访问guestagent处理,比如获取实例列表、获取实例规格列表等;而比较重的请求则通过message bus(Openstack默认实现是Rabbitmq)中转给trove-taskmanager进行调度处理。trove-taskmanager是调度处理层,主要是处理较重的请求,比如创建实例、实例resize等。
taskmanager会通过Nova、Swift的API访问Openstack基础的服务,而且是有状态的,是整个系统的核心。trove-conductor是guestagent访问数据库的代理层,主要是为了屏蔽掉guestagent直接对数据库的访问。
在Trove目前的实现中,一个数据库实例一一对映到一个vm,而guestagent也是运行在vm里面。vm镜像包含了经过裁剪的操作系统、数据库引擎和guestagent(镜像具体实现没有标准,数据库引擎和guestagent也都可以在vm启动时通过网络动态装载)。而实例所在分区的硬盘是通过Cinder提供的云硬盘。每个vm都会关联一个安全组防火墙,只允许数据库服务的端口通过(比如Mysql,默认是TCP 3306端口)。从这里可以看出,Trove创建数据库实例是非常灵活的,后期的调度也非常方便,这些都得益于Nova和Cinder。
Trove功能介绍
正如前面说的,实际上Trove是在主流的关系和非关系型数据库的一些核心概念基础上抽象出的一个系统框架,所以其实现的功能也是围绕着这些核心概念的。Trove的概念关系图:
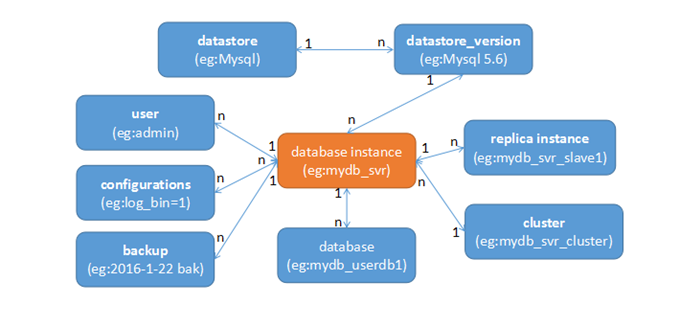
因此Trove的主要功能也是围绕这几个概念实现的。datastore管理,Instance管理,configuration管理,database管理,user管理,replication管理,backup管理,cluster管理等等。
从最新的Liberty版本看,目前Trove的功能还是比较多的,而且扩展性很强。可惜的是实例统计监控功能却没有看到,而统计监控功能的缺失,应该也是导致了实例容灾的自动切换还没有实现,相信这些都会在不久的新版本中逐渐完善。不过从另外一个角度看,由于数据库对用户来说是非常关键的服务,涉及到核心数据的数据一致性问题,目前交由用户上层去确认和切换实例也不失一个明智的选择。下面以Mysql数据库作为例子,对Trove的一些重要功能进行分析。
1、动态resize能力
分为instance-resize和volume-resize,前者主要是实例运行的内存大小和cpu核数,后者主要是指数据库分区对应的硬盘卷的大小。由于实例是跑在vm上的,而vm的cpu和memory的规格可以通过Nova来进行动态调整,所以调整是非常方便快捷的。另外硬盘卷也是由Cinder提供的动态扩展功能来实现resize。resize过程中服务会有短暂的中断,是由于mysqld重启导致的。
2、全量与增量备份
目前mysql的实现中,备份是由实例vm上的guestagent运行xtrabackup工具进行备份,且备份后的文件会存储在Swift对象存储中。从备份创建实例的过程则相反。由于xtrabackup强大的备份功能,所以Trove要做的只是做一些粘胶水的工作。
3、动态配置更新
目前支持实例的自定义配置,可以创建配置组应该到一组实例上,且动态attach到运行中的实例中生效。
4、一主多从的一键创建
在创建数据库实例的API中,支持批量创建多个从实例,并以指定的实例做主进行同步复制。这样就方便了从一个已有实例创建多个从实例的操作。而且mysql5.6版本之后的同步复制支持GTID二进制日志,使得主从实例之间关系的建立更加可靠和灵活,在failover处理上也更加快速。
5、集群创建与管理(percona/mariadb支持)
Cluster功能目前在mysql原生版本暂时不支持,但是其两个分支版本percona和mariadb基于Galera库实现的集群复制技术是支持的。另外Liberty版本的Trove也提供了对mongodb的集群支持。
Trove还提供了以其他一些许多功能,使用troveclient可以有详细的帮助信息输出。对于一个要求不是很高的云数据库管理平台,Trove目前这些功能已经够用,而且能够搭配好Openstack其他服务无缝运行起来。
Trove实践例子
在Openstack上启用Trove服务有两个要点。一个是要制作Trove的数据库实例运行的vm镜像,因为要把troveguestagent和相关的数据库引擎(比如mysql)打包进镜像,而且需要精简OS。另外,就是要有一个包含Trove服务的Openstack环境。幸好Trove项目有个子项目trove-integration,把这些工作都打包了,方便了开发者使用。本文实践的例子是在一个虚拟机上利用trove-integration建立带Trove的Openstack的运行环境,并且制作Trove实例运行的vm镜像(mysql镜像),并在上面搭建mysql一主二从实例集群运行起来。
1、准备一个运行ubuntu的虚拟机(trove-integration建议用ubuntu),内存至少8G以上,CPU最少2核以上,否则跑起整个环境来会比较吃力,用libvirt快速创建一个。
2、用Git下载trove-integration(https://github.com/openstack/trove-integration.git)。仔细查看目录可以看到其实是利用了devstack去安装整个Openstack环境,而且里面还带了diskimage-builder工具,专门制作Openstack的各种vm镜像(利用diskimage-builder创建Trove镜像在Openstack官方也给了专门的讲解《Building Guest Images for OpenStack Trove》http://docs.openstack.org/developer/trove/dev/building_guest_images.html)。
3、安装带Trove的Openstack环境。进入trove-integration目录trove-integration/scripts下,运行./redstack install,这个过程会比较长,视乎网络速度和运行的机器的速度,在我的虚拟机上运行大概1个小时多一点。redstack是一个入口程序,里面有很多功能,可以单独运行有详细的帮助信息。
4、制作mysql的实例运行镜像,并把镜像导入Glance,在Trove中建立datastore(比如mysql)和version(比如5.6版本)信息,运行./redstack kick-start mysql。(其中version信息是包含存放在Glance中的vm镜像信息)这个过程也有点长,因为是使用diskimage-builder根据定义好的element去动态下载打包并配置镜像的。
实际上利用trove-instegration项目建立的实例运行的vm镜像,并没有把guestagent打包进去,而是通过vm文件系统中/etc/init/troveguestagent脚本,在vm启动的时候从宿主机上把guestagent拷贝过去,这个过程其实是很快的,因为程序比较小。
以上过程可以参考https://wiki.openstack.org/wiki/Trove/trove-integration,由于实际运行可能会由于环境问题导致出错需要重试或者具体问题具体分析。
5、利用Openstack提供的Trove客户端工具troveclient创建mysql实例并搭建集群。运行trove -h会有详细的帮助信息。
1)创建主实例
trove create my_inst_master 8 --size 10 --database my_inst_db --users admin:admin123 --datastore mysql --datastore_version 5.6
实例名字为my_inst_master,实例规格ID是8(512MB内存),硬盘卷大小是10GB,并且创建数据库my_inst_db和用户admin(密码是admin123),数据库引擎类型是mysql,版本是5.6版本。
2)创建主实例的备份(先随便在创建的数据库实例里创建表和插入一些数据)
trove backup-create my_inst_master my_bak.0001
创建数据库实例my_inst_master的当前的备份,备份名字为my_bak.0001。
3)从主实例的备份创建两个从实例,并且建立主从关系
trove create my_inst_slave 8 --size 10 --backup my_bak.0001 --replica_of my_inst_master --replica_count 2
创建两个数据库实例,名字以mysql_inst_slave开头,实例规格ID为8,硬盘卷大小是10GB,并且用备份名为my_bak.0001的备份导入数据,且建立到实例my_inst_master的主从复制关系。
4)动态Resize主实例规格
trove resize-instance my_inst_master 2
动态调整实例my_inst_master的instance规格为2(内存2GB大小)
trove resize-volume my_inst_master 20
动态调整实例my_inst_master的硬盘卷大小为20GB
对比与总结
从以上的介绍可以知道,Openstack的DBaaS服务Trove确实有所创新,不同与业界的类似产品实现。在这样的设计目标与实现机制下,可以说有优点也有缺点,通过与典型的云数据库平台进行对别,稍微总结如下:
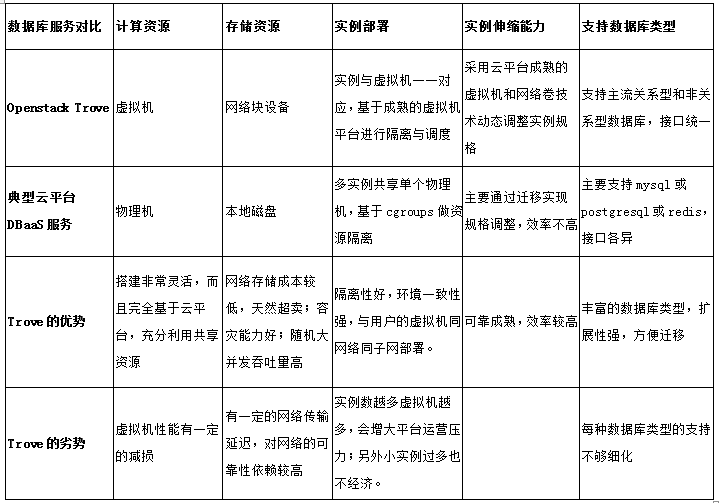

目前大规模使用Trove做云数据库平台有ebay、Rackspace、HP等公司。近来也得益于Openstack的版本迭代速度较快,从Juno版本开始每个版本Trove都会带来不少新特性,项目本身也越来越受社区重视,相信在后续版本中,Trove会补足已有的一些缺点,充分利用Openstack平台的优势,在稳定性和可运营性方面做得更好,特别是在实例创建与调度上提升容灾级别,增加taskmanager这个中心点的容灾能力,增加数据库实例的监控信息、自动透明切换实例的能力,所以Trove的下两个版本应该是非常值得期待。

