Python入门之数据处理——12种有用的Pandas技巧
引言
Python正迅速成为数据科学家偏爱的语言——这合情合理。它作为一种编程语言提供了更广阔的生态系统和深度的优秀科学计算库。
在科学计算库中,我发现Pandas对数据科学操作最为有用。Pandas,加上Scikit-learn提供了数据科学家所需的几乎全部的工具。本文旨在提供在Python中处理数据的12种方法。此外,我还分享了一些让你工作更便捷的技巧。
在继续学习之前,我会建议你阅读一下数据挖掘(data exploration)的代码。为了帮助你更好地理解,我使用了一个数据集来执行这些数据操作和处理。
数据集:我使用了贷款预测(Loan Prediction)问题的数据集。请先下载数据集(如果你需要这个数据集,请在评论区联系我们并请留下电子邮件地址——编者注),然后就可以开始了。
我们开始吧
从导入模块和加载数据集到Python环境这一步开始:

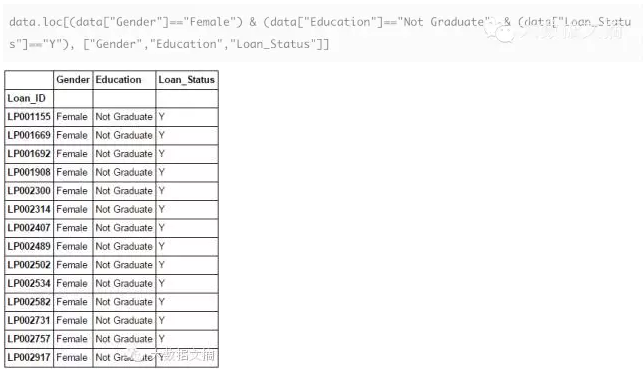
# 1?布尔索引
如果你想根据另一列的条件来筛选某一列的值,你会怎么做?例如,我们想获得一份完整的没有毕业并获得贷款的女性名单。这里可以使用布尔索引实现。你可以使用以下代码:
# 2?Apply函数
Apply是一个常用函数,用于处理数据和创建新变量。在利用某些函数传递一个数据帧的每一行或列之后,Apply函数返回相应的值。该函数可以是系统自带的,也可以是用户定义的。举个例子,它可以用来找到任一行或者列的缺失值。

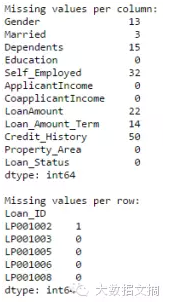
由此我们得到了需要的结果。
注:第二个输出中使用了head()函数,因为结果中包含很多行。
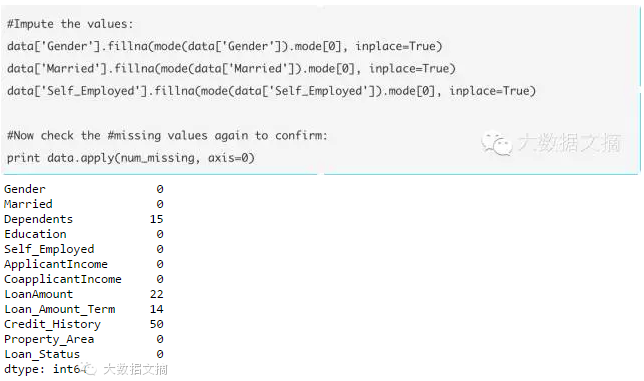
# 3?填补缺失值
‘fillna()’可以一次性解决:以整列的平均数或众数或中位数来替换缺失值。让我们基于其各自的众数填补出“性别”、“婚姻”和“自由职业”列的缺失值。
#首先导入函数来判断众数

结果返回众数和其出现频次。请注意,众数可以是一个数组,因为高频的值可能有多个。我们通常默认使用第一个:

现在,我们可以填补缺失值并用# 2中提到的方法来检查。
#填补缺失值并再次检查缺失值以确认
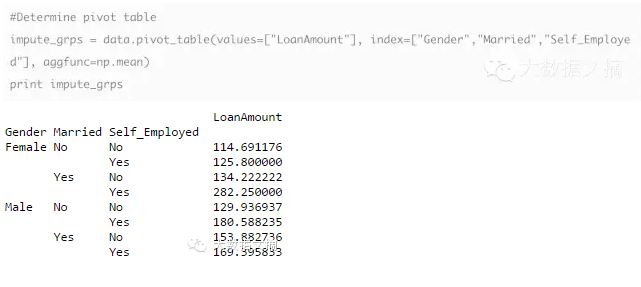
# 4?透视表
Pandas可以用来创建MS Excel风格的透视表。例如,在本例中一个关键列是“贷款数额”有缺失值。我们可以根据“性别”,“婚姻状况”和“自由职业”分组后的平均金额来替换。 “贷款数额”的各组均值可以以如下方式确定:
# 5?多索引
如果你注意到#3的输出,它有一个奇怪的特性。每一个索引都是由3个值组合构成的。这就是所谓的多索引。它有助于快速执行运算。
从# 3的例子继续开始,我们有每个组的均值,但还没有被填补。
这可以使用到目前为止学习到的各种技巧来解决。
#只在有缺失贷款值的行中进行迭代并再次检查确认

注意:
1. 多索引需要在loc中声明的定义分组的索引元组。这个元组会在函数中用到。
2. .values[0]后缀是必需的,因为默认情况下元素返回的索引与原数据框的索引不匹配。在这种情况下,直接赋值会出错。
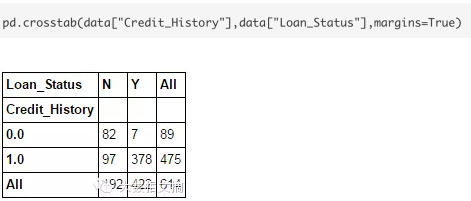
# 6. 交叉表
此函数用于获取数据的一个初始“感觉”(视图)。在这里,我们可以验证一些基本假设。例如,在本例中,“信用记录”被认为显著影响贷款状况。这可以使用交叉表验证,如下图所示:
这些是绝对值。但是,要获得快速的见解,用百分比更直观。我们可以使用apply 函数来实现:
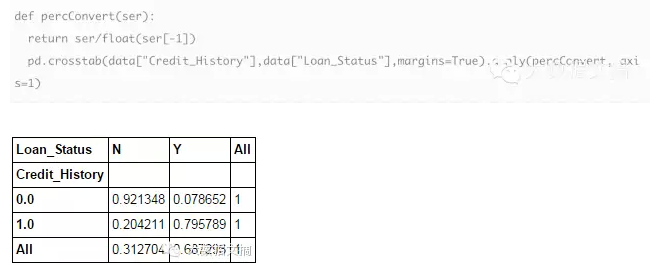
现在,很明显,有信用记录的人得到一笔贷款的可能性更高:与没有信用记录的人只有8%得到贷款相比,80%的有信用记录的人获得了一笔贷款。
然而不仅如此。其中包含了更有趣的信息。由于我已经知道有一次信用记录是非常重要的,如果我预测拥有信用记录的人贷款状态是Y(贷款成功),而没有的人为N(贷款失败)。令人惊讶的是,我们在614个例子中会有82+378=460次的正确。这个比例高达75%!
如果你仍纳闷为何我们还需要统计模型,我不会怪你。但是相信我,即使在目前这个精准度上再提高哪怕0.001%的精度仍会是一项充满挑战性的任务。你会接受这个挑战吗?
注:这个75%是基于训练集的。测试集会略有不同,但接近。另外,我希望这能提供一些直觉,即到底为什么哪怕0.05%的精度提升,可造成Kaggle排行榜(数据分析竞赛网站——译者注)上的名次上升500位。
# 7?合并数据帧
当我们需要对不同来源的信息进行合并时,合并数据帧变得很重要。假设对于不同物业类型,有不同的房屋均价(INR/平方米)。让我们定义这样一个数据帧:
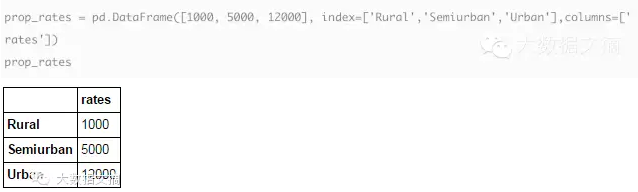
现在,我们可以将原始数据帧和这些信息合并:
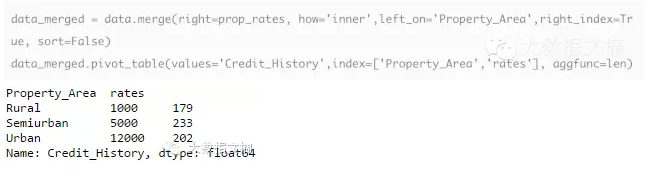
透视表验证了成功的合并操作。请注意,“value”在这里是无关紧要的,因为在这里我们只简单计数。
# 8?数据帧排序
Pandas允许在多列之上轻松排序。可以这样做:

注:Pandas的“排序”功能现在已不再推荐。我们用“sort_values”代替。
# 9?绘图(箱线图和柱状图)
很多人可能没意识到,箱线图和柱状图可以直接在Pandas中绘制,不必另外调用matplotlib。这只需要一行命令。例如,如果我们想通过贷款状况来比较申请人收入的分布,我们可以这样做:


可见收入本身并不是一个决定性因素, 因为获得/未获得贷款的人没有明显的收入差异。
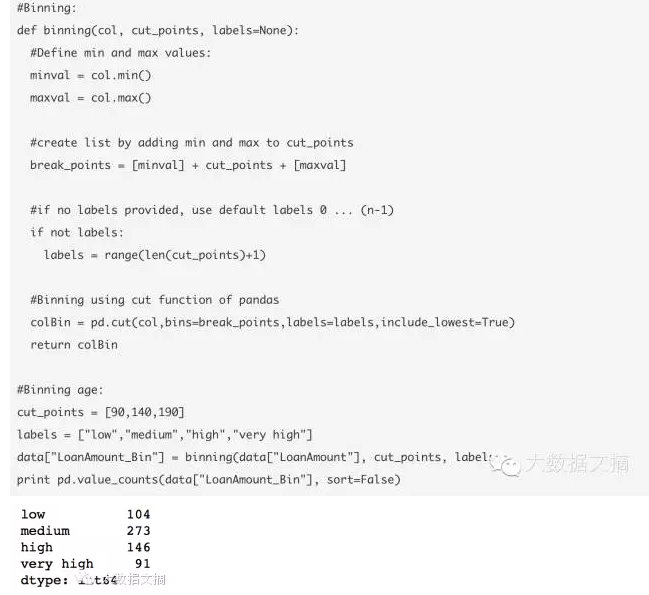
# 10?Cut函数用于分箱
有时如果数值聚类会更有意义。例如,如果我们试图用时间(分钟)对交通状况(路上的车流量)建模。相比于如“早晨”“下午”“傍晚”“晚上”“深夜”这样的时段,具体分钟数可能对预测交通量不那么相关。如此对交通建模会更直观,也避免过度拟合。
在这里,我们定义了一个简单可复用的函数,可以轻松地用于对任何变量的分箱。
# 11?编码名义变量
有时,我们会遇到必须修改名义变量的类别的情况。这可能是由于以下各种原因:
1. 一些算法(如逻辑回归)要求所有的输入都是数值型,因此名义变量常被编码为0, 1…(n-1)
2. 有时同一个类别可以用两种方式来表示。如温度可能被记录为“High(高)”“Medium(中)”“Low(低)”“H(高)”“low(低)”。在这里,无论是“High(高)”还是“H(高)”是指同一类。同理,“Low(低)”和“low(低)”也是同一类。但是,Python会将它们视为不同分类。
3. 有些类别的频率可能非常低,把它们归为一类一般会是个好主意。
在这里,我定义了一个通用的函数,以字典的方式输入值,使用Pandas中“replace”函数来重新对值进行编码。
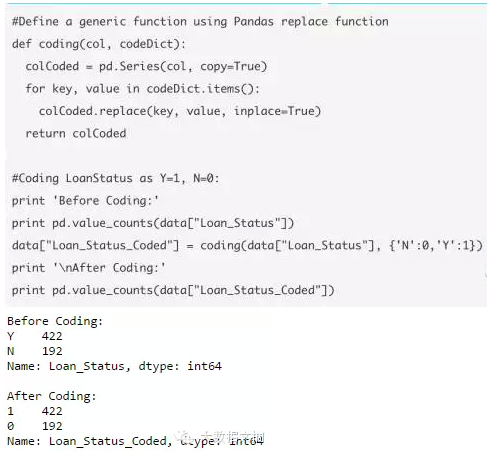
编码前后计数不变,证明编码成功。。
# 12?在一个数据帧的行上进行迭代
这不是一个常用的操作。毕竟你不想卡在这里,是吧?有时你可能需要用for循环迭代所有的行。例如,我们面临的一个常见问题是在Python中对变量的不正确处理。这通常在以下两种情况下发生:
1. 数值类型的名义变量被视为数值
2. 带字符的数值变量(由于数据错误)被认为是分类变量。
所以手动定义变量类型是一个好主意。如果我们检查所有列的数据类型:
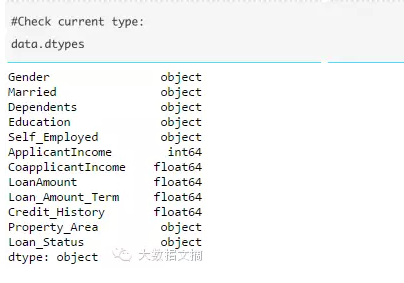
在这里,我们看到名义变量“Credit_History(信用记录)”被当做浮点数类型。解决这些问题的一个好方法是创建一个包括列名和类型的CSV文件。这样,我们就可以定义一个函数来读取文件,并指定每一列的数据类型。例如,我在这里已经创建了一个CSV文件datatypes.csv,如下所示:

加载这个文件后,我们可以在每一行上进行迭代,以列类型指派数据类型给定义在“type(特征)”列的变量名。
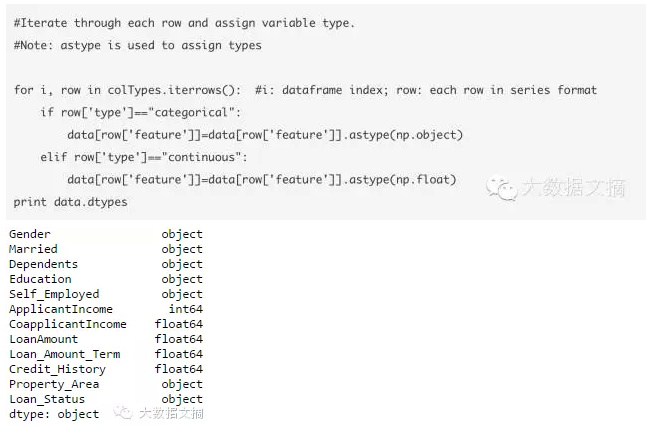
现在的信用记录列被修改为“object”类型,这在Pandas中表示名义变量。
结语
本文中,我们涉及了Pandas的不同函数,那是一些能让我们在探索数据和功能设计上更轻松的函数。同时,我们定义了一些通用函数,可以重复使用以在不同的数据集上达到类似的目的。
欢迎加入本站公开兴趣群
软件开发技术群
兴趣范围包括:Java,C/C++,Python,PHP,Ruby,shell等各种语言开发经验交流,各种框架使用,外包项目机会,学习、培训、跳槽等交流
QQ群:26931708
Hadoop源代码研究群
兴趣范围包括:Hadoop源代码解读,改进,优化,分布式系统场景定制,与Hadoop有关的各种开源项目,总之就是玩转Hadoop
QQ群:288410967
