Kafka在大数据生态系统中的价值
作者 Jun Rao 为ODBMS撰写文章的转载。译者 Brian Ling,专注于三高(高性能,高稳定性,高可用性)的码农。
近几年, Apache Kafka的应用有了显著的增长。Kafka最新的客户包括Uber, Twitter, Netflix, LinkedIn, Yahoo, Cisco, Goldman Sachs 等。Kafka是个高可扩展的生产消费者系统。利用Kafka系统,用户可以发布大量的消息, 同时也能实时订阅消费消息。本文旨在说明Kafka如何在大数据生态系统中扮演越来越重要的角色。
以不变应万变模式的短板
长期以来,数据库成为人们存放和处理感兴趣数据的首选。数据库厂商不断发布新功能 (例如 搜索,流式处理和分析),以确保在数据库内能完成更多有意思的工作。然而,基于以下2点原因,数据库模式不再是理想的方案。
原因一:当人们试图采集其他类型的数据集(例如用户行为跟踪记录,运营性能指标,应用日志等), 数据库变的越来越昂贵。相比于交易数据,这些数据集同等重要,因为利用它们能更深入地理解业务,然而它们的数据量会大到2-3倍的规模。由于传统数据库通常依赖于昂贵又高端的存储系统(例如SAN), 因而数据库存储所有数据集的开销变的极其昂贵。
其次,随着越来越多的功能堆砌,数据库变的过于复杂,在维护之前遗留版本的同时,很难增加新的功能。数据库厂商跨多年的发布变的越来越普遍。
专用分布式系统的涌现
在近10年, 为了克服这些短板,人们开始构建专用系统。这些系统生而为了单一的目标,但能够非常好地完成。因为他们的简单性,在商业硬件上构建类似的分布式系统逐渐可行。因而,相比 以SAN为存储基础的数据库,这些专用系统性价比更高。通常,类似系统是构建在开源项目上,进而降低了所有权的成本。而且,由于这些专用系统只关注单一目标,相比于大而全的系统,他们可以发展和改进得更快。Hadoop引领了这个风潮。它专注于离线数据处理,通过提供分布式文件系统(HDFS)和计算引擎(MapReduce)来批量存储和处理数据。相比于数据库存储,利用HDFS,企业能够支持低廉地采集存储更多有价值的数据集。利用MapReduce,大家能以低廉的代价来针对新数据集 提供报告和分析。在其他很多领域,类似的模式在不断上演。
键/值对存储:Cassandra,MongoDB,HBase等
搜索:ElasticSearch, Solr 等
流式处理:Storm, Spark Streaming,Samza等
图:GraphLab,FlockDB 等
时序数据库:OpenTSDB等
类似专用系统能帮助公司提供更深入地见解, 构建前所未有的新应用。
专用系统数据导入
当这些专用系统变革IT技术栈,它也会引发新挑战:如何导入数据到这些系统中。首先,要注意的是从交易型数据到用户跟踪数据,运营指标,服务日志等,会有很多有趣的数据类型。通常,同一份数据集需要被注入到多个专用系统内。例如,当应用日志用于离线日志分析,它和搜索单个日志记录的作用同等重要。这使得构建各自独立的工作流来采集每种类型的数据,直接导入到每个相关的专用系统中 变的不切实际。
其次,当Hadoop常常保存所有类型数据的副本,这导致导入数据到所有其他Hadoop以外的系统 无法实行 因为大部分系统要求数据实时导入 这是Hadoop所无法保证的。这也是为什么Kafka能出现并参与大数据生态系统。Kafka有以下不错的特性:
为了能在商业硬件上,存储高容量的数据而设计的分布式系统。
设计成能支持多订阅的系统,同份发布的数据集能被消费多次。
天生保存数据到磁盘,在没有性能损耗的条件下,能同时传送消息到实时和批处理消费者。
内置的数据冗余,因而可以保障高可用性,以用于关键任务的数据发布消费。
大部分被提及的公司在最初阶段总是集成多个专用系统。他们利用Kafka作为数据中转枢纽来实时消费所有类型的数据。同份Kafka数据可以被导入到不同专用系统中。如下图所示,我们参考这样的构架作为流式数据平台。由于新系统能通过订阅Kafka,轻易地获取它想要的数据,我们可以轻松地引入额外的专用系统,进入到这系统构架中。
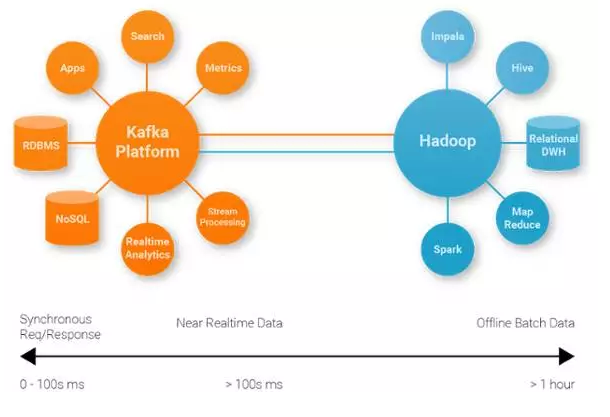
未来展望
业界趋势是多个专用系统能在大数据生态圈内共存。当更多的公司开始推进实时处理时,由分布式生产/消费系统(例如:Kafka)驱动的流式数据平台 在这生态系统中扮演愈加重要的角色。由此产生的一个影响是人们开始重新思考数据策管流程。目前,很多数据策管例如模式化数据和数据模式的演化将被延迟到 数据加载到Hadoop系统内的阶段。由于统一数据管理的流程会在其他专用系统重复执行,这对于流式数据平台并不理想。更好的方案是当数据消化处理,进入Kafka时,早期就开始设计数据策管。这也是我们Confluent目前做的部分工作,更多细节可以参考我们的网站。
欢迎加入本站公开兴趣群
软件开发技术群
兴趣范围包括:Java,C/C++,Python,PHP,Ruby,shell等各种语言开发经验交流,各种框架使用,外包项目机会,学习、培训、跳槽等交流
QQ群:26931708
Hadoop源代码研究群
兴趣范围包括:Hadoop源代码解读,改进,优化,分布式系统场景定制,与Hadoop有关的各种开源项目,总之就是玩转Hadoop
QQ群:288410967
