大数据:Hadoop族群介绍
大数据是支持一系列技术(如各种Hadoop项目、NoSQL产品,甚至MPP数据库系统)的术语,它通过驱动更好的分析和从数据中获得有价值的信息为世界各地的组织机构极大地降低了成本,同时提供了新的见解和产品。在经济衰退时期,企业更希望从己有资产中获得更大的价值,而不是投资新的资产。大数据,特别是Hadoop,就是实现这个目标的理想手段。
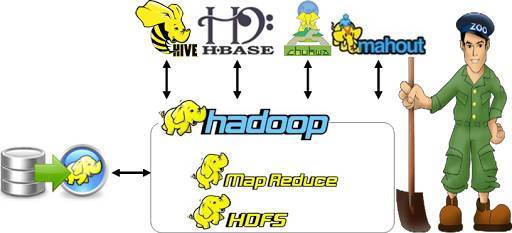
什么是Hadoop?
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
2006年Hadoop项目诞生。Hadoop其最初只是雅虎公司用来解决网页搜索问题的一个项目,后来因其技术的高效性,被ApacheSoftware Foundation公司引入并成为开源应用。Hadoop本身不是一个产品,而是由多个软件产品组成的一个生态系统,这些软件产品共同实现全面功能和灵活的大数据分析。Hadoop为用户提供了一个可靠的共享存储和分析系统。从技术上看,Hadoop由两项关键服务构成:采用Hadoop分布式文件系统(HDFS)的可靠数据存储服务,以及利用一种叫做MapReduce技术的高性能并行数据处理服务。这两项服务的共同目标是,提供一个使对结构化和复杂数据的快速、可靠分析变为现实的基础。
为什么要用Hadoop?
关系型数据库(RDBMS)大部分价格高昂,要用RDBMS存储不停增长的大数据,就必须无限量的扩充存储容量。相比之下,Hadoop是开源软件,无需license,只要是X86 CPU linux操作系统的话,都可以安装Hadoop。现在的RDBMS采取的是在储存数据的服务器中集中处理数据的方式;而Hadoop是将数据储存在多台的服务器中,在存储数据的多台服务器中同时处理数据。
九十年代的硬盘拥有1370MB的存储空间和4.4MB/s的传送速度,读取整个硬盘数据需要的时间为五分钟;现在的硬盘拥有1TB的存储和100MB/s左右的传输速度,读取整个硬盘数据的时间需要两个半小时以上。
硬盘的容量增长迅速,但是access数据库管理系统的发展却跟不上。读取花费时间长,使用时速度慢。为了克服这样的问题,就有了现在的多台服务器中分布式存储数据然后以并行的方式处理。例如美国时代杂志在2008年度利用Amazon的EC2、S2以及Hadoop仅在一天之内,用了1万美元就将130年间1100万张新闻成功地转换成了PDF文件。
Hadoop族群有哪些?

MapReduce:分布式处理和资源管理。
Hadoop MapReduce是一个用于编写并行处理大数据集的应用程序的软件框架。MapReduce作业将分割大型数据集并将数据组织成键值对进行处理。
为了充分利用Hadoop提供的并行处理优势,我们需要将数据的查询表示成 MapReduce 作业,它是客户端需要执行的一个工作单元:它包括数据的输入、MapReduce程序和配置信息。Hadoop将作业分成若干个小任务来执行,其中包括两类任务:map任务和reduce任务。
有两类节点控制着作业执行过程:—个jobtracker及一系列tasktracker。jobtracker 通过调度tasktracker上运行的任务,来协调所有运行在系统上的作业。tasktracker在运行任务的同时将运行进度报告发送给jobtracker,jobtracker由此记录毎项作业任务的整体进度情况。如果其中一个任务失败,jobtracker可以在另外一个 tasktracker节点上重新调度该任务。
Hadoop将MapReduce的输入数据划分成等长的小数据块,称为输入分片(inputsplit) 或简称分片。Hadoop为每个分片构建一个map任务,并由该任务来运行用户自定义的map函数从而处理分片中的毎条记录。
拥有许多分片,意味着处理每个分片所需要的时间少于处理整个输入数据所花的时间。因此,如果我们并行处理每个分片,且每个分片数据比较小,那么整个处理过程将获得更好的负载平衡,因为一台较快的计算机能够处理的数据分片比一台较慢的计算机更多,且成一定的比例。即使使用相同的机器,处理失败的作业或其他同时运行的作业也能够实现负载平衡,并且如果分片被切分得更细,负载平衡的质量会更好。
另一方面,如果分片切分得太小,那么管理分片的总时间和构建map任务的总时间将决定着作业的整个执行时间。对于大多数作业来说,一个合理的分片大小趋向于HDFS的一个块的大小,默认是64 MB,不过可以针对集群调整这个默认值。

HDFS(Hadoop Distributed FileSystem)
Hadoop分布式文件系统(HDFS)是一种分布式文件系统,采用MapReduce,是 Hadoop 生态系统的核心。HDFS是HDInsight上Hadoop群集的标准文件系统。
HDFS以流式数据访问模式来存储超大文件,运行于商用硬件集群上。它的构建思路是这样的:一次写入、多次读取是最髙效的访问模式。数据集通常由数据源生成或从数据源复制而来,接着长时间在此数据集上进行各类分析。每次分析都将涉及该数据集的大部分数据甚至全部,因此读取整个数据集的时间延迟比读取第一条记录的时间延迟更重要。当数据集的大小超过一台独立物理计算机的存储能力时,就有必要对它进行分区(partition)并存储到若干台单独的计算机上。管理网络中跨多台计算机存储的文件系统称为分布式文件系统(distributedfilesystem)。该系统架构于网络之上,势必会引入网络编程的复杂性,因此分布式文件系统比普通磁盘文件系统更为复杂。例如,使文件系统能够容忍节点故障且不丢失任何数据,就是一个极大的挑战。
Hadoop在存储有输入数据(HDFS中的数据)的节点上运行map任务,可以获得最佳性能。这就是所谓的数据本地化优化(datalocality optimization)。现在我们应该清楚为什么最佳分片的大小应该与块大小相同:因为它是确保可以存储在单个节点上的最大输入块的大小。如果分片跨越两个数据块,那么对于任何一个HDFS节点,基本上都不可能同时存储这两个数据块,因此分片中的部分数据需要通过网络传输到map任务节点,与使用本地数据运行整个map任务相比,这种方法显然效率更低。
map任务将其输出写入本地硬盘,而非HDFS。这是为什么?因为map的输出是中间结果:该中间结果由reduce任务处理后才产生最终输出结果,而且一旦作业完成,map的输出结果可以被删除。因此,如果把它存储在HDFS中并实现备份,难免有些小题大做。如果该节点上运行的map任务在将map中间结果传送给reduce 任务之前失败,Hadoop将在另一个节点上重新运行这个map任务以再次构建map 中间结果。
HBase:一个分布式、按列存储数据库。
HBase是一个在HDFS上开发的面向列的分布式数据库。如果需要实时地随机访问超大规模数据集,就可以使用HBase应用。
虽然数据库存储和检索的实现可以选择很多不同的策略,但是绝大多数解决办法,特别是关系数据库技术的变种,不是为大规模可伸缩的分布式处理而设计的。很多厂商提供了复制(replication)和分区(partitioning)解决方案。让数据库能够从单个节点上扩展出去,但是这些附加的技术大都属于“事后”的解决办法,而且非常难以安装和维护。并且这些解决办法常常要牺牲一些重要的RDBMS的特性。在一个“扩展的”RDBMS上,链接、复杂查询、触发器、视图以及外键约束这些功能要么运行开销大,要么根本无法用。
HBase从另一个方向来解决可伸缩性的问题。它自底向上地进行构建,能够简单地通过增加节点来达到线性扩展。HBase并不是关系型数据库,它不支持SQL,但是在特定的问题空间里,它能够做到RDBMS不能做的事:在廉价硬件构成的集群上管理超大规模的稀疏表。
Pig:更简单的MapReduce 转换脚本。
Apache Pig是一个高级平台,允许你使用一种简单脚本语言(称为PigLatin)对超大型数据集执行复杂的MapReduce转换。Pig转换PigLatin脚本,使其可以在Hadoop内运行。可以创建用户定义的函数(UDF)来扩充Pig Latin。
Pig为大型数据集的处理提供了更高层次的抽象。MapReduuce使程序员能够自己定义一个map函数和一个紧跟其后的reduce函数。但是,你必须使你的数据处理过程与这一连续的map和reduce模式向匹配。很多时候,数据处理需要多个MapReduce过程才能实现。而使得数据处理过程与该模式匹配可能很困难。有了pig,就能使用更为丰富的数据结构。这些数据结构往往都是多值和嵌套的。Pig还提供了一套更强大的数据交换操作,包括在MapReduce中被忽略的链接操作。
Pig包括两部分:
1、 用于描述数据流的语言,称为Pig Latin。
2、 用于运行Pig Latin程序的执行环境。当前有两个换进:单JVM中的本地执行环境和Hadoop集群中的分布式执行环境。
Pig Latin程序由一系列的“操作”(operation)或“变换”(transformation)组成。每个操作或变换对输入进行数据处理,并产生输出结果。从整体上看,这些操作描述了一个数据流。Pig执行环境把数据流翻译为可执行的内部表示并运行它。在Pig内部,这些变换操作被转换成一系列MapReduce作业,在多数情况下并不需要知道这些转换是如何进行的。这样一来,便可以将精力集中在数据上,而非执行细节上。
Pig是一种探索大规模数据集的脚本语言。MapReduce的一个缺点是开发周期太长,写mapper和reduce,对代码进行编译和打包,提交作业,获取结果,这整个过程非常耗时。即使使用streaming能在这一过程中去除代码的编译和打包步骤,仍不能改善这一情况。Pig的诱人之处在于仅用控制台上的五六行Pig Latin代码就能够处理TB级的数据。
然而,Pig并不适用所欲的数据处理任务。和MapReduce一样。它是为数据批处理而设计的。如果想执行的查询只涉及一个大型数据中心的一小部分数据,Pig的表现并不会很好。这是因为它要扫描整个数据集或其中的很大一部分。
Avro (Microsoft .NET Libraryfor Avro):Microsoft.NET 环境的数据序列化。
Microsoft .NET Library for Avro针对 Microsoft.NET 环境序列化实现了ApacheAvro紧凑的二进制数据交换格式。它使用JavaScript对象表示法(JSON)定义与语言无关的架构,以支持语言互操作性,这意味着以一种语言序列化的 数据 可以用另一种语言读取。有关格式的详细信息可以在ApacheAvro规范中找到。Avro文件格式支持分布式MapReduce编程模型。文件是“可拆分的”,也就是说,你可以在文件中任意设置一个点,然后即可从某一特定块开始读取。
Hive和HCatalog:与结构化查询语言(SQL) 类似的查询,以及表和存储管理层。
Apache Hive是构建于Hadoop上的一个数据仓库软件,允许使用类似于 SQL 的语言(称为 HiveQL)来查询和管理分布式存储中的大型数据集。Hive(类似于Pig)是一种基于 MapReduce的抽象。在运行时,Hive会将查询转换为一系列MapReduce作业。Hive比Pig在概念上更接近于关系数据库管理系统,因此适用于结构化程度更高的数据。对于非结构化数据,Pig是更佳的选择。
Hive的设计目的是为了让精通SQL技能(但java编程技能相对较弱)的分析师能够对Facebook存放在HDFS中的大规模数据集执行查询。今天Hive已经是一个成功的Apache项目,很多组织把它用作一个通用的,可伸缩的数据处理平台。
Apache HCatalog是Hadoop的表和存储管理层,为用户提供数据的关系视图。在HCatalog 中,你可以读取和写入采用可以写入HiveSerDe(序列化程序-反序列化程序)的任何格式的文件。
Mahout:机器学习。
Apache Mahout是在Hadoop上运行的一种可扩展的计算机学习算法库。计算机学习应用程序采用统计学原理,使系统学习数据并使用以往的结果来确定将来的行为。
Oozie:工作流管理。
Apache Oozie是一个管理Hadoop作业的工作流协调系统。它与Hadoop堆栈集成,支持 MapReduce、Pig、Hive和Sqoop的Hadoop作业。它也能用于安排特定于某系统的作业,例如Java程序或shell脚本。
Phoenix:基于HBase 的关系数据库层。
Apache Phoenix是基于HBase的关系数据库层。Phoenix提供JDBC驱动程序以允许用户直接查询和管理SQL表。Phoenix将查询和其他语句转换为本机NoSQLAPI调用(而不是使用MapReduce),因此可以在NoSQL存储之上实现更快的应用程序。
Sqoop:数据导入和导出。
Apache Sqoop是一种用于在Hadoop和关系数据库(如SQL)或其他结构化数据存储之间尽可能高效地传输批量数据的工具。
ZooKeeper:协调分布式系统中的进程。
Apache ZooKeeper通过数据寄存器的共享层次结构命名空间(znode)协调大型分布式系统中的进程。Znode包含协调流程所需的少量元数据信息:状态、位置、配置,等等。
摘自丨云角

