从数据仓库到大数据,数据平台这25年是怎样进化的?
我是从2000年开始接触数据仓库,大约08年开始进入互联网行业。很多从传统企业数据平台转到互联网同学是否有感觉:非互联网企业、互联网企业的数据平台所面向用户群体是不同的。
那么,这两类的数据平台的建设、使用用户又有变化?数据模型设计又有什么不同呢?
我们先从两张图来看用户群体的区别。
用户群体之非互联网数据平台用户
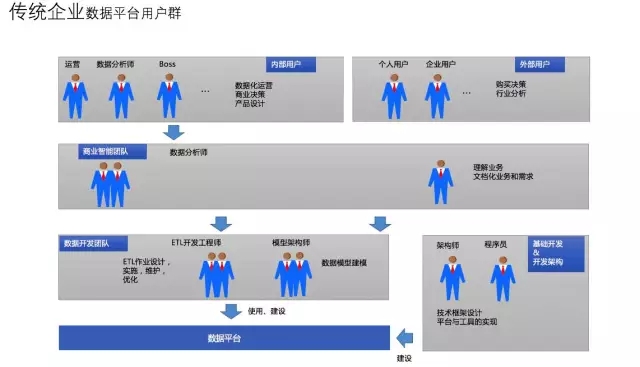
企业的boss、运营的需求主要是依赖于报表、商业智能团队的数据分析师去各种分析与挖掘探索;
支撑这些人是ETL开发工程师、数据模型建模、数据架构师、报表设计人员 ,同时这些角色又是数据平台数据建设与使用方。
数据平台的技术框架与工具实现主要有技术架构师、JAVA 开发等。
用户面对是结构化生产系统数据源。
用户群体之互联网数据平台用户
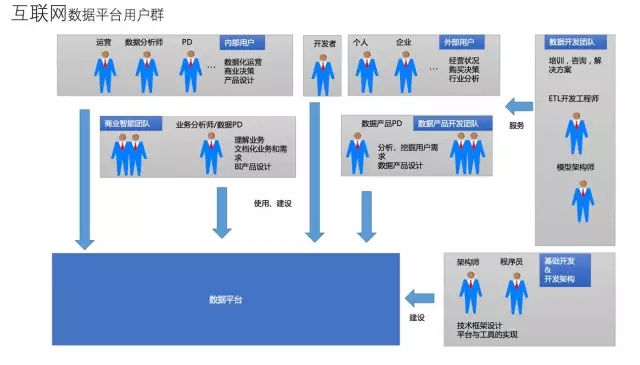
互联网企业中员工年龄比非互联网企业的要年轻、受教育程度、对计算机的焦虑程度明显比传统企业要低、还偶遇其它各方面的缘故,导致了数据平台所面对用户群体与非互联网数据平台有所差异化;
互联网数据平台的使用与建设方是来自各方面的人,数据平台又是技术、数据产品推进建设的。
分析师参与数据平台直接建设比重增加。
原有的数据仓库开发与模型架构师的职能也从建设平台转为服务与咨询.
用户面对是数据源多样化,比如日志、生产数据库的数据、视频、音频等非结构化数据 。
从这用户群体角度来说这非互联网、互联网的数据平台用户差异性是非常明显,互联网数据平台中很多理论与名词都是从传统数据平台传递过来的,本文将会分别阐述非互联网、互联网数据平台区别。

非互联网时代
自从数据仓库发展起来到现在,基本上可以分为五个时代、四种架构
约在1991年前的全企业集成
1991年后的企业数据集成EDW时代
1994年-1996年的数据集市
1996-1997年左右的两个架构吵架
1998年-2001年左右的合并年代
数据仓库第一代架构
(开发时间2001-2002年)
海尔集团的一个BI项目,架构的ETL 使用的是 微软的数据抽取加工工具 DTS,老人使用过微软的DTS 知道有哪些弊端,后便给出了几个DTS的截图。
功能:进销存分析、闭环控制分析、工贸分析等
硬件环境:
业务系统数据库:DB2 for Windows,SQL SERVER2000,ORACLE8I
中央数据库服务器:4*EXON,2G,4*80GSCSI
OLAP 服务器:2*PIV1GHZ,2G,2*40GSCSI
开发环境:VISUAL BASIC,ASP,SQL SERVER 2000

数据仓库第二代架构

这是上海通用汽车的一个数据平台,别看复杂,严格意义上来讲这是一套EDW的架构、在EDS数据仓库中采用的是准三范式的建模方式去构建的、大约涉及到十几种数据源,建模中按照某一条主线把数据都集成起来。
这个数据仓库平台计划三年的时间构建完毕,第一阶段计划构建统统一生性周期视图、客户统一视图的数据,完成对数据质量的摸底与部分实施为业务分析与信息共享提供基础平台。第二阶段是完成主要业务数据集成与视图统一,初步实现企业绩效管理。第三阶段全面完善企业级数据仓库,实现核心业务的数据统一。
数据集市架构
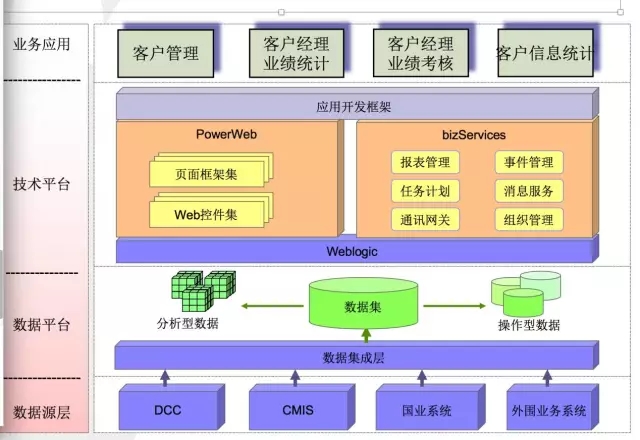
这个是国内某银行的一套数据集市,这是一个典型数据集市的架构模式、面向客户经理部门的考虑分析。
数据仓库混合性架构(Cif)

这是太平洋保险的数据平台,目前为止我认识的很多人都在该项目中呆过,当然是保险类的项目。
回过头来看该平台架构显然是一个混合型的数据仓库架构。它有混合数据仓库的经典结构,每一个层次功能定义的非常明确。
新一代架构OPDM 操作型数据集市(仓库)
OPDM大约是在2011年提出来的,严格上来说,OPDM 操作型数据集市(仓库)是实时数据仓库的一种,他更多的是面向操作型数据而非历史数据查询与分析。
数据模型
”数据模型“ 这个词只要是跟数据沾边就会出现的一个词。
在构建过程中,有一个角色理解业务并探索分散在各系统间的数据,并通过某条业务主线把这些分散在各角落的数据串联并存储同时让业务使用,在设计时苦逼的地方除了考虑业务数据结构要素外,还得考虑可操作性、约束性(备注 约束性是完成数据质量提升的一个关键要素,未来新话题主题会讨论这些),这个既要顾业务、数据源、合理的整合的角色是数据模型设计师,又叫数据模型师。
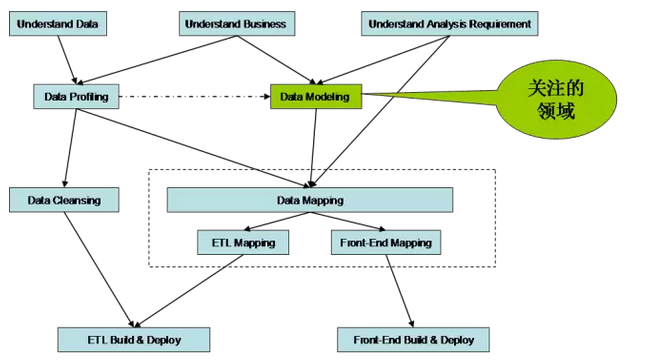
平台中模型设计所关注的是企业分散在各角落数据、未知的商业模式与未知的分析报表,通过模型的步骤,理解业务并结合数据整合分析,建立数据模型为Data cleaning 指定清洗规则、为源数据与目标提供ETL mapping (备注:ETL 代指数据从不同源到数据平台的整个过程,ETL Mapping 可理解为 数据加工算法,给数码看的,互联网与非互联网此处差异性也较为明显,非互联网数据平台对ETL定义与架构较为复杂)支持、 理清数据与数据之间的关系。
(备注:Data cleaning 是指的数据清洗 数据质量相关不管是在哪个行业,是最令人头痛的问题,分业务域、技术域的数据质量问题,需要通过事前盘点、事中监控、事后调养,有机会在阐述)。
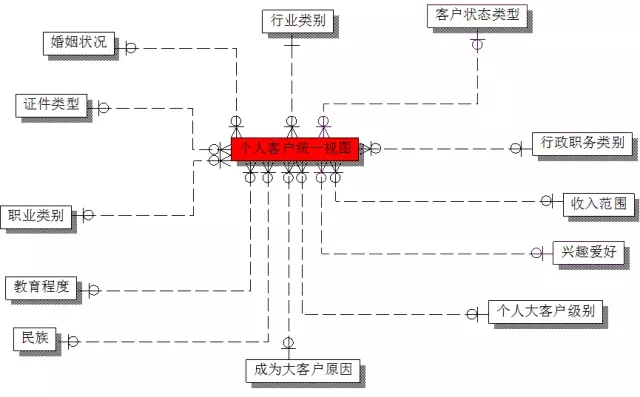
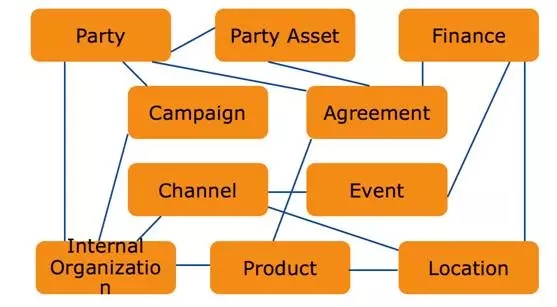
大家来看一张较为严谨的数据模型关系图:
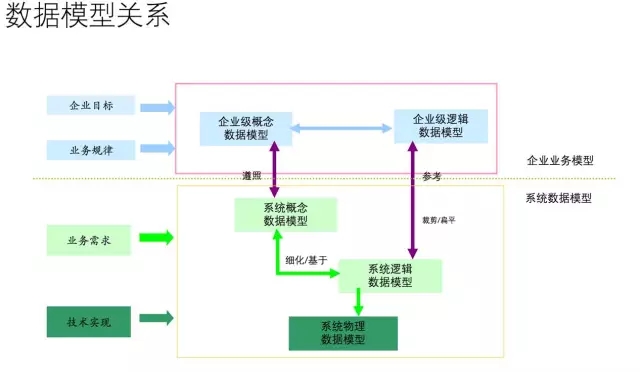
数据模型是整个数据平台的数据建设过程的导航图。
有利于数据的整合。数据模型是整合各种数据源指导图,对现有业务与数据从逻辑层角度进行了全面描述,通过数据模型,可以建立业务系统与数据之间的映射与转换关系。排除数据描述的不一致性。如:同名异义、同物异名..。
减少多余冗余数据,因为了解数据之间的关系,以及数据的作用。在数据平台中根据需求采集那些用于分析的数据,而不需要那些纯粹用于操作的数据。
数据模型在数据平台的数据仓库中是一个统称,严格上来讲分为概念模型、逻辑模型、物理模型。(备注:四类模型如何去详细构建文本不深讲,关于非互联网企业的数据模型网上非常多)

Bill Inmon对EDW 的定义是面向事物处理、面向数据管理,从数据的特征上需要坚持维护最细粒度的数据、维护最微观层次的数据关系、保存数据历史。所以在构建完毕的数据平台中可以从中映射并检查业务信息的完整性(同时也是养数据过程中的重要反馈点),这种方式还可以找出多个系统相关和重合的信息,减少多个系统之间数据的重复定义和不一致性,减小了应用集成的难度。
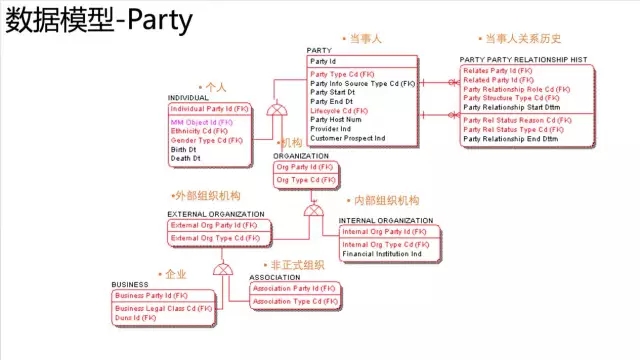
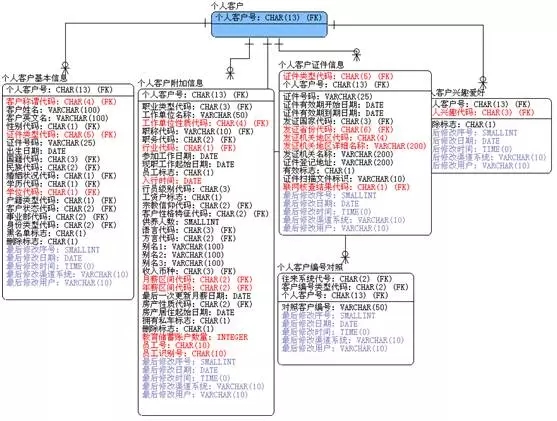
Ralph kilmball 对DM(备注:数据集市,非挖掘模型)的定义是面向分析过程的(Analytical Process oriented),因为这个模型对业务用户非常容易理解,同时为了查询也是做了专门的性能优化。所以星型、雪花模型很直观比较高性能为用户提供查询分析。
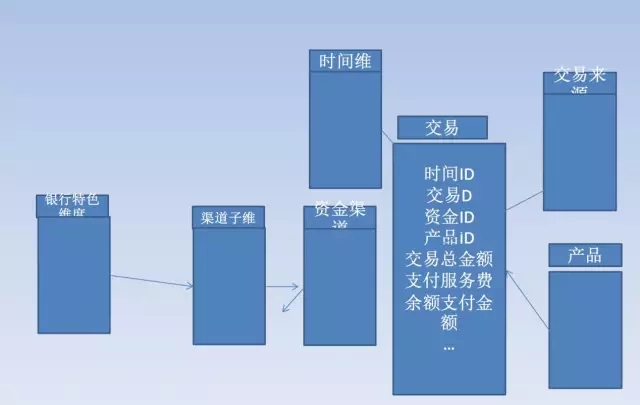
该方式的建模首先确定用户需求问题与业务需求数据粒度,构建分析所需要的维度、与度量值形成星型模型;(备注 涉及的复杂维度、退化维度等不在这个讨论范围)。
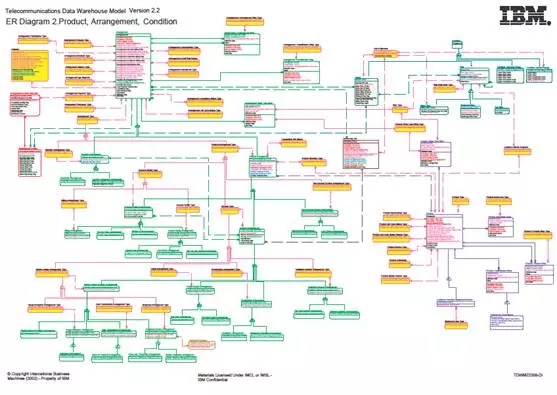
数据模型的业务建模阶段、领域概念模型阶段、逻辑模型阶段、物理模型阶段是超级学术与复杂的话题,而且在模型领域根据特点又分主数据(MDM)、CIF(企业级统一视图) 、通用模型(IBM 的金融、保险行业通用模型、 Terdata的 金融通用模型、 电信移动通用模型等),锁涉及到术语”扩展“、”扁平化“、”裁剪“等眼花缭乱的建模手法,数据模型不同层次ODS、DWD
DWD、DW、ST的分层目的不同导致模型设计方法又不同。相信业界有很多大牛能讲的清楚的,以后有机会再交流。

互联网时代
数据源
做数据的人,从非互联网进入到互联网最显著的特点是面对的数据源类型忽然多了起来,在传统企业数据人员面对的是结构化存储数据,基本来自excel、表格、DB系统等,在数据的处理技术上与架构上是非常容易总结的,但是在互联网因为业务独特性导致了所接触到的数据源特性多样化,网站点击日志、视频、音频、图片数据等很多非结构化快速产生与保存,在这样的数据源的多样化与容量下采用传统数据平台技术来处理当然是有些力不从心了
(备注:IBM的科学家分析员道格.莱尼的一份数据增长报告基础上提出了大数据的4V特性 大数据4v特性网上概念很多大家可以问度娘)。
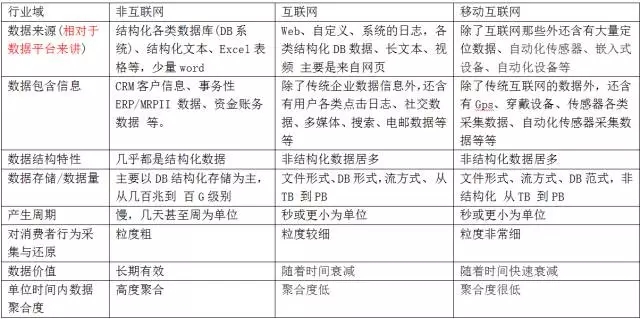
我在这里整理一个表格不同时代数据源的差异性(备注可能整理的有点不全):
数据平台的用户:
总结下来互联网的数据平台“服务”方式迭代演进大约可以分为三个阶段。
阶段一 :
约在2008年-2011年初的互联网数据平台,那时建设与使用上与非互联网数据平台有这蛮大的相似性,主要相似点在数据平台的建设角色、与使用到的技术上。
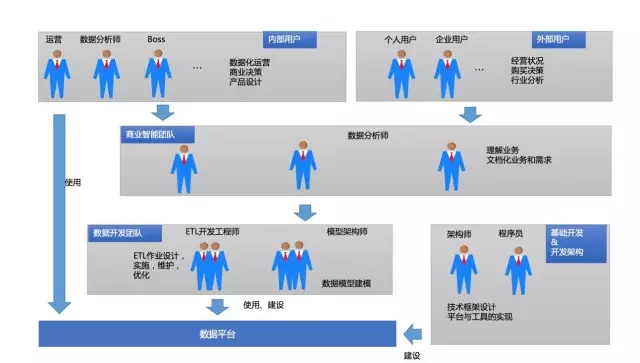
老板们、运营的需求主要是依赖于报表、分析报告、临时需求、商业智能团队的数据分析师去各种分析、临时需求、挖掘,这些角色是数据平台的适用方。
ETL开发工程师、数据模型建模、数据架构师、报表设计人员 ,同时这些角色又是数据平台数据建设与使用方。
数据平台的技术框架与工具实现主要有技术架构师、JAVA开发等。
用户面对是结构化的生产数据、PC端非结构化log等 数据。
ELT的数据处理方式(备注在数据处理的方式上,由传统企业的ETL 基本进化为ELT)。
现在的淘宝是从2004年开始构建自己的数据仓库,2004年是采用DELL 的6650单节点、到2005年更换为 IBM 的P550 再到2008年的12节点 Rac 环境。在这段时间的在IBM、EMC、Oracle 身上的投入巨大(备注:对这段历史有兴趣可以去度娘 :“【深度】解密阿里巴巴的技术发展路径“),同时淘宝的数据集群也变为国内最大的数据仓库集群。
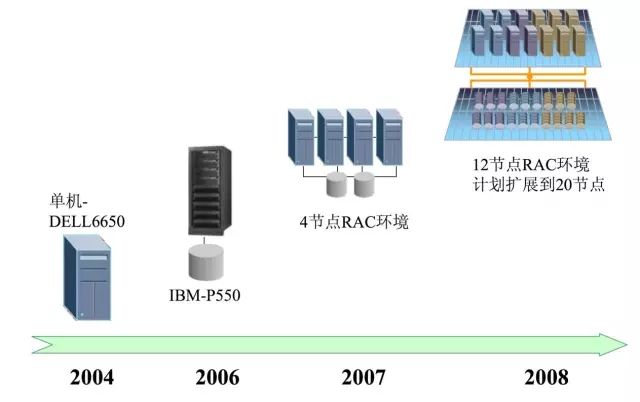
随着2010年引入了hadoop&hive平台进行新一代的数据平台的构建,此时的Greenplum 因为优秀的IO吞吐量以及有限的任务并发安排到了网站日志的处理以及给分析师提供的数据分析服务。
该阶段的数据模型是根据业务的特性采用退化、扁平化的模型设计方式去构建的。
阶段二:
互联网的数据平台除了受到技术、数据量的驱动外,同时还来自数据产品经理梳理用户的需求按照产品的思维去构建并部署在了数据的平台上。互联网是一个擅长制造流程新概念的行业。
约在2011年到2014 年左右,随着数据平台的建设逐渐的进入快速迭代期,数据产品、数据产品经理这两个词逐渐的升温以及被广泛得到认可(备注:数据产品相关内容个人会在数据产品系列中做深入分享),同时数据产品也随着需求、平台特性分为面向用户级数据产品、面向平台工具型产品两个维度分别去建设数据平台。
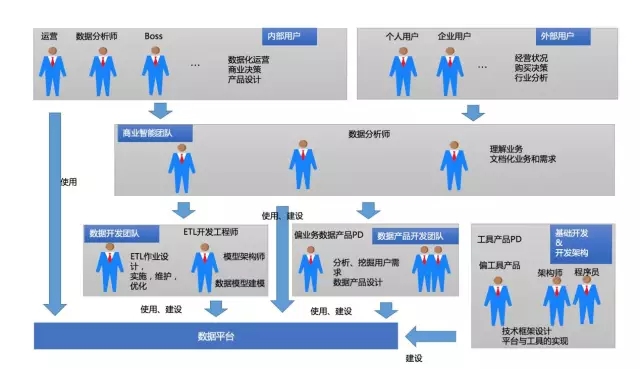
企业各个主要角色都是数据平台用户。
各类数据产品经理(偏业务数据产品、偏工具平台数据产品)推进数据平台的建设。
分析师参与数据平台直接建设比重增加。
数据开发、数据模型角色都是数据平台的建设者与使用者(备注:相对与传统数据平台的数据开发来说,逐渐忽略了数据质量的关注度,数据模型设计角色逐渐被弱化)。
用户面对是数据源多样化,比如日志、生产数据库的数据、视频、音频等非结构化数据 。
原有ETL中部分数据转换功能逐渐前置化,放到业务系统端进行(备注:部分原有在ETL阶段需要数据标准化一些过程前置在业务系统数据产生阶段进行,比如Log 日志。 移动互联网的日志标准化。
互联网企业随着数据更加逐渐被重视,分析师、数据开发在面对大量的数据需求、海量的临时需求疲惫不堪,变成了资源的瓶颈,在当时的状态传统的各类的Report、Olap 工具都无法满足互联网行业个性化的数据需求。开始考虑把需求固定化变为一个面向最终用户自助式、半自助的产品来满足快速获取数据&分析的结果,当总结出的指标、分析方法(模型)、使用流程与工具有机的结合在一起时数据产品就诞生了(备注:当时为了设计一个数据产品曾经阅读了某个部门的2000多个临时需求与相关SQL)。
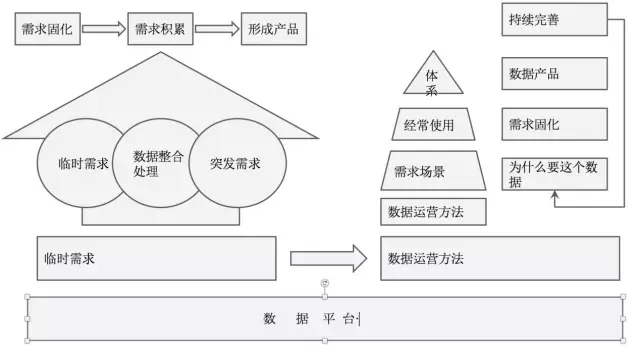
数据产品按照面向的功能与业务可以划分为面向平台级别的工具型产品、面向用户端的业务级数据产品。按照用户分类可以分为面向内部用户数据产品,面向外部用户个人数据产品、商户(企业)数据产品。
面向平台级别有数据质量、元数据、调度、资管配置、数据同步分发等等。
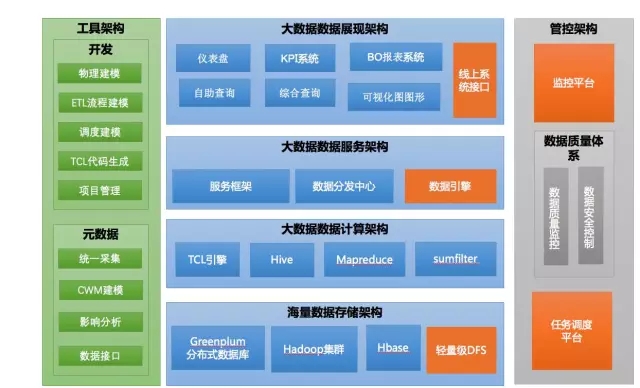
约2010-2012年的平台结构

约2012-2013年的平台结构
阶段三:
用数据的一些角色(分析师、运营或产品)会自己参与到从数据整理、加工、分析阶段。当数据平台变为自由全开放,使用数据的人也参与到数据的体系建设时,基本会因为不专业型,导致数据质量问题、重复对分数据浪费存储与资源、口径多样化等等原因。此时原有建设数据平台的多个角色可能转为对其它非专业做数据人员的培训、咨询与落地写更加适合当前企业数据应用的一些方案等。
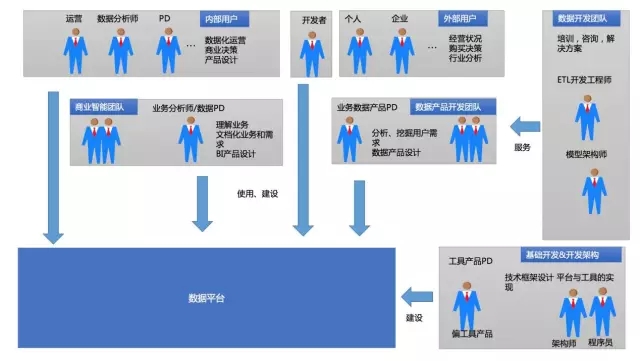
给用户提供的各类丰富的分析、取数的产品,简单上手的可以使用。
原有ETL、数据模型角色转为给用户提供平台、产品、数据培训与使用咨询。
数据分析师直接参与到数据平台过程、数据产品的建设中去。
用户面对是数据源多样化,比如日志、生产数据库的数据、视频、音频等非结构化数据 。
在互联网这个大数据浪潮下,2016年以后数据平台是如何去建设?如何服务业务?
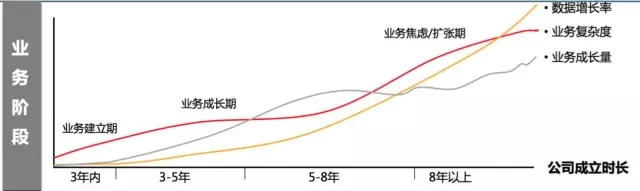
企业的不同发展阶段数据平台该如何去建设的?这个大家是可以思考的。但是我相信互联网企业是非常务实的,基本不会采用传统企业的自上而下的建设方式,互联网企业的业务快速变与迭代要求快速分析到数据,必须新业务数据迭代,老业务数据快速去杂。敏捷数据平台或许是种不错的选择方法之一吧!
欢迎加入本站公开兴趣群
软件开发技术群
兴趣范围包括:Java,C/C++,Python,PHP,Ruby,shell等各种语言开发经验交流,各种框架使用,外包项目机会,学习、培训、跳槽等交流
QQ群:26931708
Hadoop源代码研究群
兴趣范围包括:Hadoop源代码解读,改进,优化,分布式系统场景定制,与Hadoop有关的各种开源项目,总之就是玩转Hadoop
QQ群:288410967
