大数据时代之hadoop:了解hadoop数据流
了解hadoop,首先就需要先了解hadoop的数据流,就像了解servlet的生命周期似的。hadoop是一个分布式存储(hdfs)和分布式计算框架(mapreduce),但是hadoop也有一个很重要的特性:hadoop会将mapreduce计算移动到存储有部分数据的各台机器上。
术语
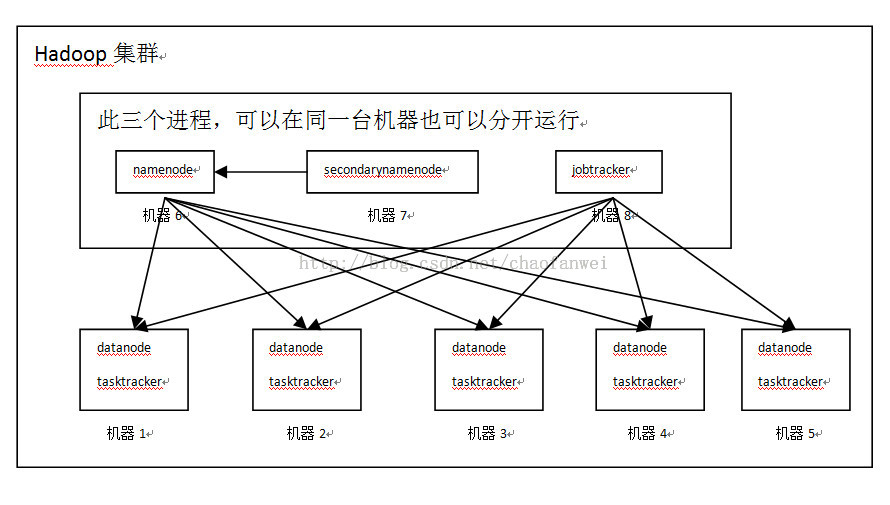
MapReduce 作业(job)是客户端需要执行的一个工作单元:它包括输入数据、mapreduce程序和配置信息。hadoop将作业分成若干个小任务(task)来执行,其中包括两类任务:map任务和reduce任务。
有两类节点控制着作业执行过程:一个jobtracker及一系列tasktracker。 jobtracker通过调度tasktracker上运行的任务,来协调所有运行在系统上的作业。tasktracker在运行任务的同时将运行进度报 告发送给jobtracker,jobtracker由此记录每项作业任务的整体进度情况。如果其中一个任务失败,jobtracker可以在另外一个 tasktracker节点上重新调度该任务。
输入
hadoop将mapreduce的输入数据划分成等长的小数据块,称为输入分片(input split)或简称分片。hadoop为每个分片构建一个map任务,并由该任务来运行用户自定义的map函数从而处理分片中的每条记录。 对于大多数作业来说,一个合理的分片大小趋向于HDFS的一个块的大小,默认是64M,不过可以针对集群调整这个默认值。分片的大小一定要根据运行的任务来定,如果分片过小,那么管理分片的总时间和构建map任务的总时间将决定着作业的整个执行时间。
hadoop在存储有输入数据的节点上运行map任务,可以获得最佳性能,这就是所谓的数据本地化优化。 因为块是hdfs存储数据的最小单元,每个块可以在多个节点上同时存在(备份),一个文件被分成的各个块被随机分部在多个节点上,因此如果一个map任务 的输入分片跨越多个数据块,那么基本上没有一个节点能够恰好同时存在这几个连续的数据块,那么map任务就需要首先通过网络将不存在于此节点上的数据块远 程复制到本节点上再运行map函数,那么这种任务显然效率非常低。
输出
map任务将其输出写入到本地磁盘,而非HDFS。这是因为map的输出是中间结果:该中间结果有reduce任务处理后才产生最终结果(保存在hdfs中)。而一旦作业完成,map的输出结果可以被删除。
reduce任务并不具备数据本地化优势:单个reduce任务的输入通常来自于所有的mapper任务的输出。reduce任务的输出通常存储于HDFS中以实现可靠存储。
数据流
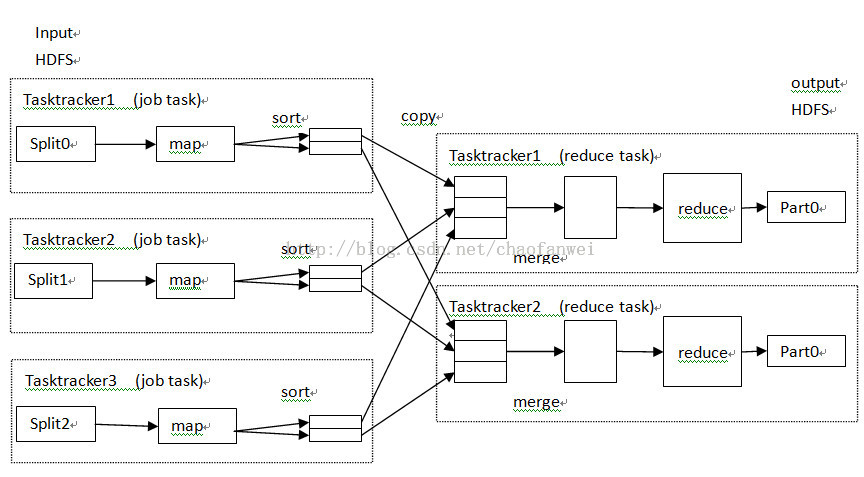
作业根据设置的reduce任务的个数不同,数据流也不同,但大同小异。reduce任务的数量并非由输入数据的大小决定的,而是可以通过手动配置指定的。
单个reduce任务

多个reduce任务
如果是多个reduce任务的话,则每个map任务都会对其输出进行分区(partition),即为每个reduce任务创建一个分区。分区有用户定义的分区函数控制,默认的分区器(partitioner) 通过哈希函数来分区。
map任务和reduce任务之间的数据流称为shuffle(混洗)。
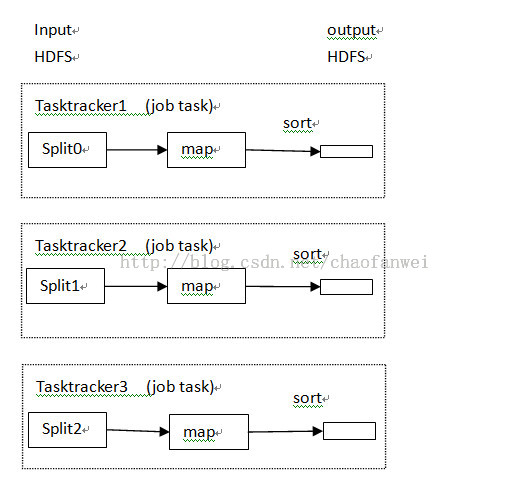
没有reduce任务
当然也可能出现不需要执行reduce任务的情况,即数据可以完全的并行。
combiner(合并函数)
顺便在这说下combiner吧,hadoop运行用户针对map任务的输出指定一个合并函数,合并函数的输出作为reduce函数的输入。其实合并函数 就是一个优化方案,说白了就是在map任务执行后在本机先执行合并函数(通常就是reduce函数的拷贝),减少网络传输量。
原文出自:http://blog.csdn.net/chaofanwei/article/details/39695743

