自动洞察:大数据的下一个重大转折
为了跟随大数据的发展以及提高我们对信息的使用,我们需要具有洞察力的应用,可以在连接洞察与操作的时候快速且低廉地提取相关性。
我坚持认为具有洞察力的应用是帮助企业高效探究大数据的关键,可以提高决策效率和解决重大问题。为了更好的理解和重视我们开发该应用的重要性,有两件事是很重要的,一是了解大数据大体上发生了什么,二是评估我们使用商业智能系统的经验如何促进我们思考这个应用。
因为我认为具有洞察力的应用是大数据的下一个变化(可以看看最近IBM沃森平台使用的一些应用),我会发表系列博客进一步探究这个问题。在第一篇博客里,我将通过我的观察展示25年来数据分析是怎样发展的,特别是到了大数据阶段,发展具有洞察力的应用是必须的。第二篇,我会更加详细的描述这些应用,并给出早期的一些例子。第三篇和最后一篇,我会讨论投资者对这些应用的兴趣,还有讲下我最近对相关创新企业的投资。在这些文章中,我作为两家分析应用创新企业的创办人,我将提到我如何将过去30年的工作经验和15年风险投资经验运用到这些企业中。
数据分析25年来的发展
数据量在过去25年一直在增长,用于决策的数据完整性促进了两个步骤的行程,即创建数据仓库和了解数据仓库的容量。
数据仓库及其他特殊变形?企业数据仓库,数据集市等等-,是精选数据的基础。
数据可能来自单独的数据源(如:一个CRM应用的数据库)或者由许多数据源整合而来(如:一个CRM应用的数据库整合,数据库内含有CRM数据库里的每位客户的社交媒体互动)。
数据可能是结构化的(如:描述客户支付金额的数据),也可能是非结构化的(如:自由文本里客户与工作人员的互动备注),也可能是半结构化的(如:网络路由器生成的日志文件数据)。被捕捉到的精选数据都是已经自动被清洗干净,被标签和分析好了的,减少了人们的人工思考的时间。
这些年,随着开源软件,云计算和商用服务器硬件的使用,我们减少了数据仓库的费用,也提高了我们管理更多不同高速产生的数据的能力。我们的收支状态已经发生改变,从为数据仓库花费几千万美元,转变为最大的公司并开始盈利,如金融服务组织花旗银行Citibank和大型零售商沃尔玛Walmart,从仓库到中小型企业皆可支付的状态。最近,低成本服务提供商,如亚马逊 Redshift, 谷歌 BigQuery以及微软Auzre,已经将数据仓库转移到云。最终,数据仓库能被大众公司接受。
随着数据仓管的增加,数据报告的发表形式从打印到数字化。
数据完整性的第二步包括通过数据分析,理解数据仓库的内容。在商业环境中,通常是通过报告和相关联的可视化实现数据的完整性,有时也使用更多定制的可视化和机器学习算法,比如人造神经网络。(机器学习不是新的内容,但是大家认为,它从数据仓库出现就一直被使用,作为数据储存和管理的工具。)
随着数据仓库被不同行业的大量企业采用,我们看到了报告形式的转变,它是可以被创造的,媒体可以提供分析学者和决策者报告,或者员工自己准备这些报告。早期(80年代晚期,90年代初期),商业智能报告是由指定的IT职员负责的,在报告中对数据仓库的必要查询是有相关标准和主题的。这些报告通过电脑用纸保存(如:报告可以被修改,但是只能由那位负责该报告的职员完成)和展示。后来,报告仍然可以保存,同时这些报告可通过指定的报告项目展示在PC上,再后来,Web浏览器可运行在不同的设备上,包括智能手机和平板,所以报告也能在这些设备上展示。这些年来,创建查询和撰写报告的任务已经从IT员工转移到企业用户。但是,当这些查询和相关报告可以更快的生成,更加灵活和广泛的使用时,这些报告的主要使用者-企业分析师-他们仍然在不断的,尝试在报告中得出信息的最简单的模式。更重要是,这些用户在尝试基于这些信息采取相应的操作(图1)。

图1:复杂的数据模型和可视化的一些例子,图片授权自Evangelos Simoudis
随着更多的数据生成,我们已经可以更好更有效的管理它的费用,但是要想对数据进项有效分析,仍然不是件容易的事。
受网络全球广泛使用,以及网络支付的连接,还有如物联网等新领域得出大量我们从未见过的数据的驱使,发现我们的周围充斥着数据。快数据和慢数据,简单数据和复杂数据,以及全部一起出现的前所未有的海量数据。数据量可以有多大?
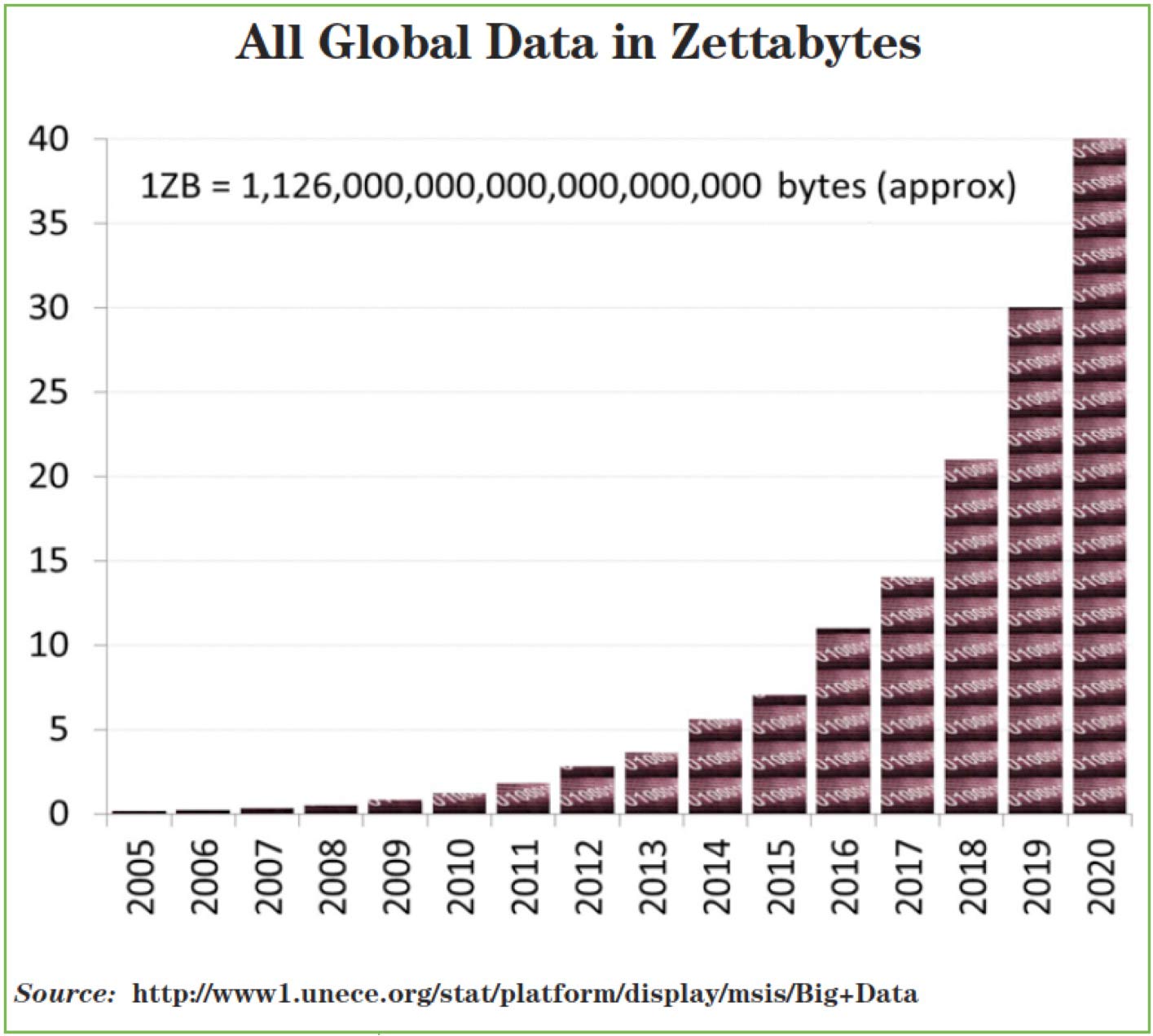
图表2:展示了生成非结构化数据从2005年到预计2020年的增长情况,图表授权来自互联网数据中心IDC,图表未经许可,不可使用。
在过去10年,数据变得更大,同时企业IT战略的核心实现了“事半功倍”。企业现在面临着数据仓库系统的两个难题。第一,有些系统不能有效管理捕捉到的大数据,导致不能有效使用那些应用。第二,费用高的离谱,对于系统而言可能会成为数据管理的挑战。
关于这些问题,出现了部分解决方案,是由科技巨头公司(如谷歌,雅虎等)开发的数据管理软件,去得到新的数据生成,如Hadoop。一开始,这个软件是运行在商用服务器硬件,它是快速开源的,因此可以帮助一些企业用低廉的成本解决一些大数据的问题。比如像Cloudera, Hortonworks和一些其他提供开源软件服务的公司已经成为大数据非结构化领域的主要成员。我之所以说只是出现了部分解决方案,是因为,在管理数据的时候,一些系统不具备解决复杂性问题的功能,专属的数据仓库管理系统只有一些企业拥有。这些新的系统擅长建立数据湖,通过低成本选择的方式替代和扩展数据仓库,它是适应大数据环境的设施。
虽然我们提高了有效管理数据费用的能力,但是我们分析数据的能力和费用没有改善。
虽然大众媒体都宣布来自数据的洞察力将是“新石油”(“黄金”),但是市场研究公司互联网数据中心IDC则预测到了2020年,只有一小部分数据可以被收集和分析。我们需要分析更多捕捉到的数据和提取其中包含的信息。
我们在努力提高分析数据的能力,但是面临数据专业人员的短缺。
为了收集和分析更多的数据,包括报告里面的数据,我们开始通过机器学习和其他基于AI的数据分析技术,来广泛地使用自动信息提取方法。但是这些方法只能由数据科学家使用,这是一种新的职业。虽然我们看到一大批数据科学家的涌现,但是我们需要更多。目前无法做到培养出满足需求数量的数据科学家,以及提供我们生成足够的数据。McKinsey预计到了2018年,美国将将面临人才短缺,大概缺14到19万名掌握深入分析技巧,能够从收集的数据里提取洞察的专业人才。
我们也面领着人才短缺,缺少大概15万名经理人,他们掌握着必要的定量技能,能基于数据科学家的大数据分析结果做出重要的商业决策。
机器学习提升了我们找到数据相关性的能力,恰好节省了决策时间,增加了数据效率。
商业智能作为一个领域已经发展了40年。统计分析和机器学习科技则使用了更久。这段时期,我们已经提高了确认数据集相关性的能力,这恰好减少了用在决策上的时间和增加了数据的效率。比如,公司的财务官需要一个月才能做出财务预测,然而一个自动线上广告平台只需要10毫秒就能决定将他们的数字广告投放给哪一位客户(图3)。还有,当财务官在根据几兆数据做出决策时,线上广告系统已经在利用TB级数据在工作,大部分数据是实时生成的。

图3:图表显示不同行业做出决策的平均时间。图表授权来自Evangelos Simoudis.
在某些应用领域,简单的确认数据集之间的关联性就足以做出决策。这其中又有一些领域可以实现高回报,这通常会让他们决定是否需要数据科学家或者其他特定专业人才,从现有数据中提取信息。计算机安全威胁检测和信用卡盗刷侦测领域就是其中两个。在这些领域里,作出决策的时间非常短,“错误”决策的成本(通常是保密的),但是至少一开始不是很高。而减少处理环节就跟安全侵入一样是诈骗行为(如:信用卡持卡人遇到了麻烦,那么系统管理者就应该要进行网络取证)。但是,在一个已经建立好的行为模式里发现异常现象失败,造成的成本可能更高。
为了跟随大数据的发展以及提高我们对数据的使用,我们需要能够快速且廉价的提取相关性的应用,将洞察与操作联系起来。
预计将短缺大量掌握定量技能的数据科学家和商业用户,我们渴望能继续探究大量已经收集和管理起来的数据,我们会开发更好的分析应用,能生成洞察力和联系操作。这些应用,我称它们为具有洞察力的应用,远不止从数据里提取相关性那么简单。
就数据的完整性方面我们已经取得了不错的成绩。一方面我们减少了管理大数据的费用,另一方面,我们提高了分析和提取关键信息的能力。但是,大数据的增长量太大了,以至于没办法跟得上大数据快速灵活的查询和报告。通过使用具有洞察力的应用,能低成本且快速地创造具有操作性的洞察。我将会在下一篇报道中更深入的探讨这个问题。
欢迎加入本站公开兴趣群
软件开发技术群
兴趣范围包括:Java,C/C++,Python,PHP,Ruby,shell等各种语言开发经验交流,各种框架使用,外包项目机会,学习、培训、跳槽等交流
QQ群:26931708
Hadoop源代码研究群
兴趣范围包括:Hadoop源代码解读,改进,优化,分布式系统场景定制,与Hadoop有关的各种开源项目,总之就是玩转Hadoop
QQ群:288410967
