如何用数据驱动产品和运营
作者简介
桑文锋,Sensors Data创始人&CEO,前百度大数据部技术经理。2007毕业于浙江大学计算机系,毕业后加入百度并负责组建并带领团队,从零实现了百度用户日志的大数据平台。2015年4月从百度离职创业,目前做一款针对互联网创业公司的数据分析产品Sensors Analytics(神策分析),致立于通过大数据技术助力客户成为数据驱动的公司。
一、大数据思维
在2011年、2012年大数据概念火了之后,可以说这几年许多传统企业也好,互联网企业也好,都把自己的业务给大数据靠一靠,并且提的比较多的大数据思维。
那么大数据思维是怎么回事?我们来看两个例子:
案例1:输入法
首先,我们来看一下输入法的例子.我2001年上大学,那时用的输入法比较多的是智能ABC,还有微软拼音,还有五笔.那时候的输入法比现在来说要慢的很多,许多时候输一个词都要选好几次,去选词还是调整才能把这个字打出来,效率是非常低的。
到了2002年,2003年出了一种新的输出法——紫光拼音,感觉真的很快,键盘没有按下去字就已经跳出来了。但是,后来很快发现紫光拼音输入法也有它的问题,比如当时互联网发展已经比较快了,会经常出现一些新的词汇,这些词汇在它的词库里没有的话,就很难敲出来这个词。
在2006年左右,搜狗输入法出现了。搜狗输入法基于搜狗本身是一个搜索,它积累了一些用户输入的检索词这些数据,用户用输入法时候产生的这些词的信息,将它们进行统计分析,把一些新的词汇逐步添加到词库里去,通过云的方式进行管理。

比如,去年流行一个词叫“然并卵”,这样的一个词如果用传统的方式,因为它是一个重新构造的词,在输入法是没办法通过拼音“ran bing luan”直接把它找出来的。然而,在大数据思维下那就不一样了,换句话说,我们先不知道有这么一个词汇,但是我们发现有许多人在输入了这个词汇,于是,我们可以通过统计发现最近新出现的一个高频词汇,把它加到司库里面并更新给所有人,大家在使用的时候可以直接找到这个词了。
案例2:地图

再来看一个地图的案例,在这种电脑地图、手机地图出现之前,我们都是用纸质的地图。这种地图差不多就是一年要换一版,因为许多地址可能变了,并且在纸质地图上肯定是看不出来,从一个地方到另外一个地方怎么走是最好的?中间是不是堵车?这些都是有需要有经验的各种司机才能判断出来。
在有了百度地图这样的产品就要好很多,比如:它能告诉你这条路当前是不是堵的?或者说能告诉你半个小时之后它是不是堵的?它是不是可以预测路况情况?
此外,你去一个地方它可以给你规划另一条路线,这些就是因为它采集到许多数据。比如:大家在用百度地图的时候,有GPS地位信息,基于你这个位置的移动信息,就可以知道路的拥堵情况。另外,他可以收集到很多用户使用的情况,可以跟交管局或者其他部门来采集一些其他摄像头、地面的传感器采集的车辆的数量的数据,就可以做这样的判断了。

这里,我们来看一看纸质的地图跟新的手机地图之间,智能ABC输入法跟搜狗输入法都有什么区别?
这里面最大的差异就是有没有用上新的数据。这里就引来了一个概念——数据驱动。有了这些数据,基于数据上统计也好,做其他挖掘也好,把一个产品做的更加智能,变得更加好,这个跟它对应的就是之前可能没有数据的情况,可能是拍脑袋的方式,或者说我们用过去的,我们想清楚为什么然后再去做这个事情。这些相比之下数据驱动这种方式效率就要高很多,并且有许多以前解决不了的问题它就能解决的非常好。
二、数据驱动
对于数据驱动这一点,可能有些人从没有看数的习惯到了看数的习惯那是一大进步,是不是能看几个数这就叫数据驱动了呢?这还远远不够,这里来说一下什么是数据驱动?或者现有的创业公司在进行数据驱动这件事情上存在的一些问题。

一种情况大家在公司里面有一个数据工程师,他的工作职责就是跑数据。

不管是市场也好,产品也好,运营也好,老板也好,大家都会有各种各样的数据需求,但都会提给他。然而,这个资源也是有限的,他的工作时间也是有限的,只能一个一个需求去处理,他本身工作很忙,大家提的需求之后可能并不会马上就处理,可能需要等待一段时间。即使处理了这个需求,一方面他可能数据准备的不全,他需要去采集一些数据,或做一些升级,他要把数据拿过来。拿过来之后又在这个数据上进行一些分析,这个过程本身可能两三天时间就过去了,如果加上等待的时间更长。
对于有些人来说,这个等待周期太长,整个时机可能就错过了。比如,你重要的就是考察一个节日或者一个开学这样一个时间点,然后想搞一些运营相关的事情,这个时机可能就错过去了,许多人等不到了,有些同学可能就干脆还是拍脑袋,就不等待这个数据了。这个过程其实就是说效率是非常低的,并不是说拿不到这个数据,而是说效率低的情况下我们错过了很多机会。

对于还有一些公司来说,之前可能连个数都没有,现在有了一个仪表盘,有了仪表盘可以看到公司上个季度、昨天总体的这些数据,还是很不错的。

对老板来说肯定还是比较高兴,但是,对于市场、运营这些同学来说可能就还不够。
比如,我们发现某一天的用户量跌了20%,这个时候肯定不能放着不管,需要查一查这个问题出在哪。这个时候,只看一个宏观的数那是远远不够的,我们一般要对这个数据进行切分,按地域、按渠道,按不同的方式去追查,看到底是哪少了,是整体少了,还是某一个特殊的渠道独特的地方它这个数据少了,这个时候单单靠一个仪表盘是不够的。

理想状态的数据驱动应该是怎么样的?就是一个自助式的数据分析,让业务人员每一个人都能自己去进行数据分析,掌握这个数据。
前面我讲到一个模式,我们源头是一堆杂乱的数据,中间有一个工程师用来跑这个数据,然后右边是接各种业务同学提了需求,然后排队等待被处理,这种方式效率是非常低的。理想状态来说,我们现象大数据源本身整好,整全整细了,中间提供强大的分析工具,让每一个业务员都能直接进行操作,大家并发的去做一些业务上的数据需求,这个效率就要高非常多。
三、数据处理的流程

大数据分析这件事用一种非技术的角度来看的话,就可以分成金字塔,自底向上的是三个部分,第一个部分是数据采集,第二个部分是数据建模,第三个部分是数据分析,我们来分别看一下。
数据采集

首先来说一下数据采集,我在百度干了有七年是数据相关的事情。我最大的心得——数据这个事情如果想要更好,最重要的就是数据源,数据源这个整好了之后,后面的事情都很轻松。
用一个好的查询引擎、一个慢的查询引擎无非是时间上可能消耗不大一样,但是数据源如果是差的话,后面用再复杂的算法可能都解决不了这个问题,可能都是很难得到正确的结论。
我觉得好的数据处理流程有两个基本的原则,一个是全,一个是细。
全:就是说我们要拿多种数据源,不能说只拿一个客户端的数据源,服务端的数据源没有拿,数据库的数据源没有拿,做分析的时候没有这些数据你可能是搞歪了。另外,大数据里面讲的是全量,而不是抽样。不能说只抽了某些省的数据,然后就开始说全国是怎么样。可能有些省非常特殊,比如新疆、西藏这些地方它客户端跟内地可能有很大差异的。
细:其实就是强调多维度,在采集数据的时候尽量把每一个的维度、属性、字段都给它采集过来。比如:像where、who、how这些东西给它替补下来,后面分析的时候就跳不出这些能够所选的这个维度,而不是说开始的时候也围着需求。根据这个需求确定了产生某些数据,到了后面真正有一个新的需求来的时候,又要采集新的数据,这个时候整个迭代周期就会慢很多,效率就会差很多,尽量从源头抓的数据去做好采集。
数据建模
有了数据之后,就要对数据进行加工,不能把原始的数据直接报告给上面的业务分析人员,它可能本身是杂乱的,没有经过很好的逻辑的。
这里就牵扯到数据建框,首先,提一个概念就是数据模型。许多人可能对数据模型这个词产生一种畏惧感,觉得模型这个东西是什么高深的东西,很复杂,但其实这个事情非常简单。

我春节期间在家干过一件事情,我自己家里面家谱在文革的时候被烧教了,后来家里的长辈说一定要把家谱这些东西给存档一下,因为我会电脑,就帮着用电脑去理了一下这些家族的数据这些关系,整个族谱这个信息。
我们现实是一个个的人,家谱里面的人,通过一个树型的结构,还有它们之间数据关系,就能把现实实体的东西用几个简单图给表示出来,这里就是一个数据模型。
数据模型就是对现实世界的一个抽象化的数据的表示。我们这些创业公司经常是这么一个情况,我们现在这种业务,一般前端做一个请求,然后对请求经过处理,再更新到数据库里面去,数据库里面建了一系列的数据表,数据表之间都是很多的依赖关系。

比如,就像我图片里面展示的这样,这些表一个业务项发展差不多一年以上它可能就牵扯到几十张甚至上百张数据表,然后把这个表直接提供给业务分析人员去使用,理解起来难度是非常大的。
这个数据模型是用于满足你正常的业务运转,为产品正常的运行而建的一个数据模型。但是,它并不是一个针对分析人员使用的模型。如果,非要把它用于数据分析那就带来了很多问题。比如:它理解起来非常麻烦。
另外,数据分析很依赖表之间的这种格子,比如:某一天我们为了提升性能,对某一表进行了拆分,或者加了字段、删了某个字短,这个调整都会影响到你分析的逻辑。

这里,最好要针对分析的需求对数据重新进行解码,它内容可能是一致的,但是我们的组织方式改变了一下。就拿用户行为这块数据来说,就可以对它进行一个抽象,然后重新把它作为一个判断表。
用户在产品上进行的一系列的操作,比如浏览一个商品,然后谁浏览的,什么时间浏览的,他用的什么操作系统,用的什么浏览器版本,还有他这个操作看了什么商品,这个商品的一些属性是什么,这个东西都给它进行了一个很好的抽象。这种抽样的很大的好处很容易理解,看过去一眼就知道这表是什么,对分析来说也更加方便。

在数据分析方,特别是针对用户行为分析方面,目前比较有效的一个模型就是多维数据模型,在线分析处理这个模型,它里面有这个关键的概念,一个是维度,一个是指标。
维度比如城市,然后北京、上海这些一个维度,维度西面一些属性,然后操作系统,还有IOS、安卓这些就是一些维度,然后维度里面的属性。
通过维度交叉,就可以看一些指标问题,比如用户量、销售额,这些就是指标。比如,通过这个模型就可以看来自北京,使用IOS的,他们的整体销售额是怎么样的。
这里只是举了两个维度,可能还有很多个维度。总之,通过维度组合就可以看一些指标的数,大家可以回忆一下,大家常用的这些业务的数据分析需求是不是许多都能通过这种简单的模式给抽样出来。
四、数据分析方法
接下来看一下互联网产品采用的数据分析方法。

对于互联网产品常用的用户消费分析来说,有四种:
(1)第一种是多维事件的分析,分析维度之间的组合、关系。
(2)第二种是漏斗分析,对于电商、订单相关的这种行为的产品来说非常重要,要看不同的渠道转化这些东西。
(3)第三种留存分析,用户来了之后我们希望他不断的来,不断的进行购买,这就是留存。
(4)第四种回访,回访是留存的一种特别的形式,可以看他一段时间内访问的频次,或者访问的时间段的情况
方法1:多维事件分析法
首先来看多维事件的分析,这块常见的运营、产品改进这种效果分析。其实,大部分情况都是能用多维事件分析,然后对它进行一个数据上的统计。
1. 三个关键概念

这里面其实就是由三个关键的概念,一个就是事件,一个是维度,一个是指标组成。
事件就是说任何一个互联网产品,都可以把它抽象成一系列事件,比如针对电商产品来说,可抽象到提交、订单、注册、收到商品一系列事件用户行为。
每一个事件里面都包括一系列属性。比如,他用操作系统版本是否连wifi;比如,订单相关的运费,订单总价这些东西,或者用户的一些职能属性,这些就是一系列维度。
基于这些维度看一些指标的情况。比如,对于提交订单来说,可能是他总提交订单的次数做成一个指标,提交订单的人数是一个指标,平均的人均次数这也是一个指标;订单的总和、总价这些也是一个指标,运费这也是一个指标,统计一个数后就能把它抽样成一个指标。
2. 多维分析的价值
来看一个例子,看看多维分析它的价值。
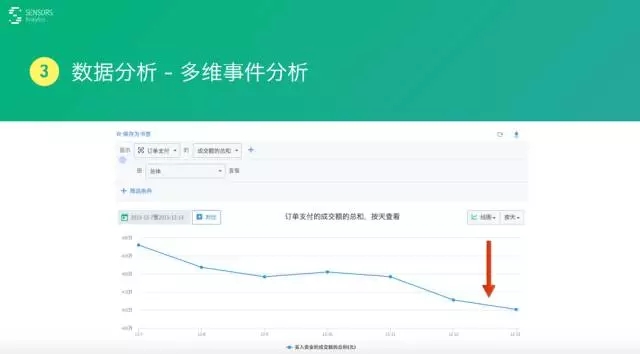
比如,对于订单支付这个事件来说,针对整个总的成交额这条曲线,按照时间的曲线会发现它一路在下跌。但下跌的时候,不能眼睁睁的看着它,一定要分析原因。
怎么分析这个原因呢?常用的方式就是对维度进行一个拆解,可以按照某些维度进行拆分,比如我们按照地域,或者按照渠道,或者按照其他一些方式去拆开,按照年龄段、按照性别去拆开,看这些数据到底是不是整体在下跌,还是说某一类数据在下跌。

这是一个假想的例子——按照支付方式进行拆开之后,支付方式有三种,有用支付宝、阿里PAY,或者用微信支付,或者用银行看内的支付这三种方式。
通过数据可以看到支付宝、银行支付基本上是一个沉稳的一个状态。但是,如果看微信支付,会发现从最开始最多,一路下跌到非常少,通过这个分析就知道微信这种支付方式,肯定存在某些问题。
比如:是不是升级了这个接口或者微信本身出了什么问题,导致了它量下降下去了?
方法2:漏斗分析
漏斗分析会看,因为数据,一个用户从做第一步操作到后面每一步操作,可能是一个杂的过程。

比如,一批用户先浏览了你的首页,浏览首页之后可能一部分人就直接跑了,还有一部分人可能去点击到一个商品里面去,点击到商品可能又有很多人跑了,接下来可能有一部分人就真的购买了,这其实就是一个漏斗。

通过这个漏斗,就能分析一步步的转化情况,然后每一步都有流失,可以分析不同的渠道其转化情况如何。比如,打广告的时候发现来自百度的用户漏斗转化效果好,就可能在广告投放上就在百度上多投一些。
方法3:留存分析

比如,搞一个地推活动,然后来了一批注册用户,接下来看它的关键行为上面操作的特征,比如当天它有操作,第二天有多少人会关键操作,第N天有多少操作,这就是看它留下来这个情况。
方法4:回访分析

回访就是看进行某个行为的一些中度特征,如对于购买黄金这个行为来说,在一周之内至少有一天购买黄金的人有多少人,至少有两天的有多少人,至少有7天的有多少人,或者说购买多少次数这么一个分布,就是回访回购这方面的分析。
上面说的四种分析结合起来去使用,对一个产品的数据支撑、数据驱动的这种深度就要比只是看一个宏观的访问量或者活跃用户数就要深入很多。
五、运营分析实践
下面结合个人在运营和分析方面的实践,给大家分享一下。
案例1:UGC产品

首先,来看UGC产品的数据分析的例子。可能会分析它的访问量是多少,新增用户数是多少,获得用户数多少,发帖量、减少量。
诸如贴吧、百度知道,还有知乎都属于这一类的产品。对于这样一个产品,会有很多数据指标,可以从某一个角度去观察这个产品的情况。那么,问题就来了——这么多的指标,到底要关注什么?不同的阶段应该关注什么指标?这里,就牵扯到一个本身指标的处理,还有关键指标的问题。
案例2:百度知道

2007年我加入百度知道之后,开始刚进去就写东西了。作为RB,我每天也收到一系列报表邮件,这些报表里面有很多统计的一些数据。比如,百度知道的访问量、减少量、IP数、申请数、提问量、回答量,设置追加答案,答案的数量,这一系列指标。当时,看的其实感觉很反感。
我在思考:这么多的指标,不能说这也提高,那也提高吧?每个阶段肯定要思考哪个事最关键的,重点要提高哪些指标。开始的时候其实是没有任何区分的,不知道什么是重要、什么是不重要。
后来,慢慢有一些感触和认识,就发现其实对于访问量、减少量这些相关的。因为百度知道需要流量都是来自于大搜索,把它展现做一下调整或者引导,对量的影响非常大。虽然,跟百度知道本身做的好坏也有直接关系,但是它很受渠道的影响——大搜索这个渠道的影响。
提问量开始的时候,我认为非常重要,怎么提升提问量,那么整个百度知道平台的这个问题就多了。提升回答量,让这些问题得到回答,高质量的内容就非常多了,又提升提问量,而后再提升回答量——其实等于是两类人了。而怎么把它做上去,我当时有一些困惑,有一些矛盾,到底什么东西是最关键的。
有一次产品会,每一个季度都有一个产品会。那个时候,整个部门的产品负责人是孙云丰,可能在百度待过的或者说对百度产品体系有了解的都会知道这么一个人,非常厉害的一个产品经理。我当时就问了他这个问题,我对提问量、回答量都要提升这个困惑。

他就说了一点,其实提问量不是一个关键的问题,为什么?我们可以通过大搜索去找,如果一个用户在大搜索里面进行搜索,发现这个搜索没有一个好的答案,那就可以引导他进行一个提问,这样其实这个提问量就可以迅速提升上去。
我一听一下就解决了这个困惑,最关键的就是一个回答量,我所做的事情其实怎么去提升回答量就可以了。

这里面把百度知道这个产品抽样成了最关键的一个提升——那就是如何提升回答量,在这个问题上当时做了一个事情就是进行问题推荐。
百度知道有一批活跃用户,这些用户就喜欢回答问题。于是,我们思考:能不能把一些他们可以回答问题推荐给他们,让他们回答各种各样的问题——这个怎么去做呢?
这个思路也很简单,现在个性化推荐都是比较正常的,大家默认知道这么一回事。但是,2008年做推荐这个事情其实还是比较领先的,从我了解的情况来看,国内的是2010年个性化推荐引擎这块技术火了,但后来有些公司做这方面后来都倒掉了。

实现策略是非常简单的,我们就看一个用户历史的回答记录,看他回答的这些问题开头是什么、内容是什么。
由于百度很擅长做自然语言的处理,基于这些,通过这里面的抽取用户的兴趣词,感兴趣的话题,然后把待解的问题,与该问题相关话题的相关用户进行一个匹配,匹配上了就把这个问题推荐给这个用户。
当时,我们做的一个事情就是:把推荐几个月有过回答量比较高的用户进行一个抽取,对他们训练一个模式——就是对每个用户有一系列的话题兴趣点,然后每个点都有一个程度,这就是一个用户的模型项量,就是一个兴趣项量,当时抽了35万个用户。
这个效果是这样的,现在我已经找了我们当年做的图片,整个样式其实这是我前一段时间截的图,大体类似。比如,我对数据分析相关的问题回答了不少,它就会给我推荐数据分析相关的问题。
我们这个功能差不多做了有三个月,把它推上线我们其实是满怀期待的,结果效果如何呢?

上线之后很悲剧,我们发现总的回答量没有变化。于是,我们又进一步分析了一下原因。当时,最开始这些核心用户在回答问题的时候都是找分类页。比如:电脑这个分类,然后看电脑相关的问题,有兴趣的就回答。
后来,我们做了一个体验:在个人中心里面加了一个猜他喜欢的那个问题,然后推给他,结果用户从分类页回答这个问题转到了个人中心。但是,平均一个人回答量并没有变化,当时做的这些统计,这些核心用户就回答六个问题,超过六个他就没动力回答了。
我们事后分析原因,有一个原因他可能本身的回答量就是这么一条线,谁能天天在哪里源源不断的回复问题。还有一个同事就分析当时让他一个痛苦的地方,因为我们是源源不断地推荐,然后他就发现回答几个之后还有几个,回答了几次就感觉要崩溃了,就不想再这么回答下去了。
其实,年前时知乎在问题推荐上也做了不少功夫,做了许多测试。年前有一段时间,它天天给我推一些新的问题,然后我去回答。后来,发现推的太多了,就没回答的动力了。
针对这些核心用户会发现从他们上面榨取不了新的价值了。于是,我们调转了矛头,从另一个角度——能不能去广撒网,吸引更多的用户来回答问题,这个做的就是一个库里推荐。

访问百度的时候,百度不管用户是否登录,会在用户的库里面去设置一个用户标识。通过这个标识能够对这个用户进行一个跟踪,虽然不知道用户是谁,但是,起码能把同一个用户这个行为给它检起来。这样,就可以基于他历史的检索,各种搜索词,还有他流量的各种页面的记录,然后去提取一些证据,然后给这些库题建一个模型。
这样有一个好处,能够覆盖的用户量非常大,前面讲的核心用户推荐只覆盖了只有35万的核心用户,但是通过这种方式可以覆盖几亿百度用户,每一次用户登录之后或者访问百度知道之后我们就基于他本身兴趣然后走一次检索,在解决问题里面检索一下跟他匹配的就给他推荐出来。

比如前一段,我自己在没有登录的时候,其实我是会看马尔克斯。我比较喜欢马尔克斯的作品,我当时搜了马尔克斯的一些相关的内容。它就抽取出来我对马尔克斯什么感兴趣,就给我推荐了马尔克斯相关的问题,可能我知道我不可能就会点进去回答。
这个功能上了之后效果还是很不错的,让整体的回答量提升了7.5%。要知道,百度知道产品从2005年开始做,做到2007年、2008年的时间这个产品已经很成熟了。在一些关键指标进行大的提升还是非常有挑战的,这种情况下我们通过这种方式提升了7.5%的回答量,感觉还是比较有成就感,我当时也因为这个事情得了季度之星。
案例3:流失用户召回
这种形式可能对其他产品就很有效,但是对我们这个产品来说,因为我们这是一个相对来说目标比较明确并且比较小众一点的差别,所以这个投放的效果可能就没那么明显。
在今年元旦的时候,因为之前申请试用我们那个产品已经有很多人,但是这里面有一万人我们给他发了帐号他也并没有回来,我们过年给大家拜拜年,然后去汇报一下进展看能不能把他们捞过来一部分。

这是元旦的时候我们产品的整体用户情况,到了元旦为止,9月25号发布差不多两三个月时间,那个时候差不多有1490个人申请试用了我们这个产品。但是,真正试用的有724个,差不多有一半,另外一半就跑了,就流失了。
我们就想把这部分人抽出来给他们进行一个招回活动,这里面流失用户我们就可以把列表导出来,这是我们自己的产品就有这样的功能。有人可能疑惑我们怎么拿到用户的这些信息呢?

这些不至于添加,因为我们申请试用的时候就让他填一下姓名、联系方式,还有他的公司这些信息。对于填邮箱的我们就给发邮件的,对于发手机号的我们就给他发短信,我们分析这两种渠道带来的效果。
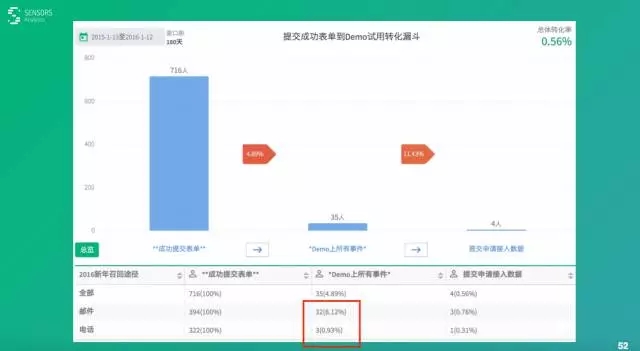
先说总体,总体我们发了716个人,这里面比前面少了一点,我把一些不靠谱的这些信息人工给它干掉了。接下来,看看真正有35个人去体验了这个产品,然后35个人里面有4个人申请接入数据。
因为我们在产品上面做了一个小的改进,在测试环境上面,对于那些测试环境本身是一些数据他玩一玩,玩了可能感兴趣之后就会试一下自己的真实数据。这个时候,我们上来有一个链接引导他们去申请接入自己的数据,走到这一步之后就更可能转化成我们的正式客户。
这两种方式转化效果我们其实也很关心,招回的效果怎么样,我们看下面用红框表示出来,邮件发了394封。最终有32个人真正过来试用了,电话手机号322封,跟邮件差不多,但只有3个过来,也就是说两种效果差了8倍。
这其实也提醒大家,短信这种方式可能许多人看短信的比较少。当然,另一方面跟我们自己产品特征有关系,我们这个产品是一个PC上用起来更方便的一个产品。许多人可能在手机上看到这个链接也不方便点开,点开之后输入帐号也麻烦一点。所以,导致这个效果比较差。
欢迎加入本站公开兴趣群
软件开发技术群
兴趣范围包括:Java,C/C++,Python,PHP,Ruby,shell等各种语言开发经验交流,各种框架使用,外包项目机会,学习、培训、跳槽等交流
QQ群:26931708
Hadoop源代码研究群
兴趣范围包括:Hadoop源代码解读,改进,优化,分布式系统场景定制,与Hadoop有关的各种开源项目,总之就是玩转Hadoop
QQ群:288410967
