大数据如何改善我们周围的生存环境
在正式讲环境大数据之前,我们来讲一个和身边有关的案例。大多数去过星巴克喝咖啡的人都会有这样一个疑惑,“为什么星巴克室内温度比室外温度低呢?”甚至有人开始抱怨说室内温度太低,但是这也不会带来什么改变。因为在冷的环境下,顾客肯定会倾向于买热咖啡,而且是大杯的热咖啡。像温度、水分、声音这些东西跟我们平时生活息息相关,包括购买意愿实际上跟我们周围环境都是直接相关的。
环境数据的特性
前段时间参加了100offer组织的大数据技术沙龙,参讲嘉宾都是来自知名互联网科技界的技术牛人,但是给我影响最深的还是佳格大数据CTO张弓讲的大数据在环境改善方面所做的一些努力,如何通过数据分析来确定一定范围内气候的变化,以及接下来大数据在环境技术方面还需要做那些完善。
张弓说,环境两个字解开了说就是环我之境,周围的环境才是我们所研究的数据核心。所谓环境大数据就是指气象、温度、湿度,包括道路图、建筑图、污染问题,也包括资源性的数据。这些数据有一个特点,具有时空场。
大家现在都讲大数据,大数据就是最核心的三维,人们通过IT技术获得更多的数据。大约15年前,我们就开始通过接触环境数据来做天气预报,因为这是一个处在前端、即时性要求非常高的预报,所以数据的模拟处理都是按照秒级来计算的。所以说数据量是非常大的,包括各种卫星图像所提供的点上数据、面上数据,但是主要以图像或图像流为主。在现在看来,那就是海量数据。
卫星影像到全球原油储量
这里再列举一张Skybox拍摄的储油罐的照片,从这一张照片上能获得哪些有价值的数据呢?当然是可以从中获悉储油海港的大小,运输量的大小。

这些数据都是从储油罐的阴影来计算的,通过太阳高度角和阴影长度来计算储油罐的油量,基本上利用这样的方法能将全球80%以上的原油储量计算出来,而且是完全不可阻止的。这就是黑科技的用途。

大数据就是技术型企业的根本,对数据的分析精度决定了数据的价值大小,张弓说他们以前分析数据的尺度非常粗糙。简单的说,对时间的衡量是以年或月做单位的,这种数据分析的商业价值就会比较低,更多作为策略性使用。
环境数据:大数据时代前的海量数据
现在的原始数据是非常大的,比如一张从卫星里发送出来的图片,是一种描述地面的时空数据,数据量非常大。另外一类是模型数据,对模型进行分析。因为时空是连续的,所以用于模型分析的方法相对较为复杂,例如从内蒙古刮过来的沙尘暴会到它的下风口北京,属于连续时空性动作,很难用数据来描述。十几年前基于数学算法,针对时空图像数据利用MPI+Fortran来处理海量数据,还创造出HDF和NetCDF这些类似于现在Spark或Hadoop的工具。

众所周知,数据最核心的部分就是具有极强的时空连续性,这里就涉及到数据获取和数据融合的问题,因为不同的数据源,不同的数据类型、不同的数据格式,导致每一个时空上面颗粒分辨率是不同的,如何把250米*250米的数据和一个30米*40米的数据进行比较,这里就涉及到比较复杂的时空尺度融合问题。从数据结构上考虑,如果时空数据本身是连续的,可能更便于计算,它的分析工具的内核也是基于Spark为主。
数据可视化就更复杂了,这里面最主要的一个可视化类型就是把数据变成图形来展现,而且让人们更容易的接受这些图片。
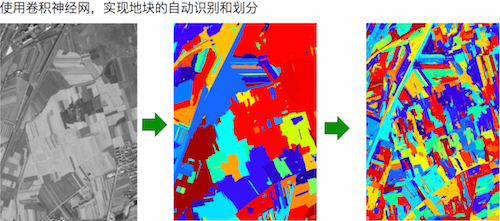
数据分析是针对图像数据化过程的核心内容,就相当于一个分析可视化的过程,从而获得我想要的数据,这是比较困难的。所以这里就用到了能够进行图像识别和模式识别的机器学习和深度学习的概念。比如说如何用不同的颜色把田地里不同作物表示出来,哪怕是作物的方向也要识别出来的话。这里就要分析纹理的朝向和密度。第一步先做深度学习,原始分辨率是半米乘半米,深度学习要有足够的层数,然后对图像进行处理,建立一些窗口,比如建立3乘3、5乘5、9乘9窗口,下图是用了208个方块做出来的深度神经网络结果,识别度超过人眼。这样做的结果就是能够很清晰的知道庄稼的长势如何,如何根据这些数据来安排接下来的土地利用情况,最大化土地利用率。
雾霾预测
这里可以来谈谈之前在网上传播很广的雾霾预警图——佳格“霾图”。这是基于环境大数据,对大气污染进行实时监测预警的工具。“霾图”用地图的形式实时展现我国任一地区的大气污染数据,并预测未来五天的空气质量。其实时数据目前每小时更新一次,空间精度为五公里。用大数据直面雾霾这块“硬骨头”,不仅需要充分准确的数据源、优秀的数据处理,还需要合适的可视化能力。
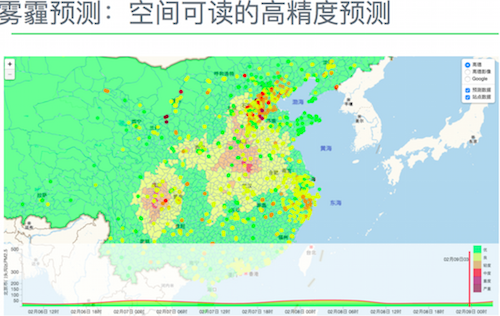
对于采集到的大量数据,需要进行整合处理才能用来生成霾图。霾图的数据算法主要包含两个任务:
数据同化和实时展示任务。获得的卫星数据主要分两种,一种是时间分辨率高的数据,一种是空间分辨率高的数据。这需要把两种数据进行融合;同时卫星并不会直接给出PM2.5的测量数据,而是一类光学指标,其中包括大气气溶胶光学厚度(aerosol optical depth)。利用基于不同城市自主研发的算法将这个变量计算出准确的PM2.5浓度值,并在“霾图”上实时展示。
预测任务。目前国内空气质量预测主要有两种传统方法:第一种是根据大气物理化学(污染物的沉降,运输和扩散以及二次气溶胶反应)的经典算法跟污染物排放清单的集合对未来大气情况进行推测;第二种是基于数理统计模型方法。比如拿到过去十年的数据,通过对时间序列的季节性,趋势性进行分析来做预测,辅以人工判断。这两种方法主要使用的都是地面监测点提供的数据,并没有用到卫星数据。同时国内排放清单数据存在时效性弱的弊端,并且地面监测点分布不均且数据容易受到人为因素的影响。这样所得到的预测结果存在着极大的偏差和局限,准确度较低。
相比这两种传统方法,佳格“霾图”所开发的预测方法和模型具有自己的特点:首先,佳格做预测的数据是更精确均匀的卫星数据。其次,佳格运用模型最优化方法,综合考虑多种国际上最先进的气候预测模型,通过算法选出动态的最合适的预测模型,用于预测未来五天内的空气质量情况。
张弓在最后的演讲中也提到,大数据的潜力还没有被完全挖掘出来,这需要时间和不断的尝试才能发挥它最大的价值,更好的改善我们的日常生活环境。

