2015年人工智能研究进展综述,有五类重要突破
2015年,人工智能和机器学习方面取得的进展着实令人惊艳。尽管现在的发展速度还处在可掌控的范围内,但业内人士都认为相关进展的速度正一年比一年快。近期该领域的大部分成果都建立在2015年初其它团队的早期成果上,而相比之下,大部分其它领域成果的参考资料可以追溯到几十年前。
做一个广泛覆盖该领域发展的总结几乎不可避免地会用到大量听起来拟人化的描述,而本总结也确实如此。但这样的比喻只是用于谈论这些功能的方便的捷径。重要的是要记住,即使许多这些功能听起来都很像是具有(像人类一样的)「思想」,但它们通常和人类认知的工作方式并不十分一样。这些系统全都是功能性和机械化的,而且每一种的应用范围都很狭窄,尽管这种情况正在逐渐减少。警告:阅读本文时,这些功能可能会由稀奇变得平淡。
2015年智能领域最大的进展都可以归入到五个分类中:跨越不同环境的抽象能力(abstracting across environments)、直观概念理解(intuitive concept understanding)、创造性抽象思维(creative abstract thought)、虚构想象(dreaming up visions)和敏捷灵巧的运动能力(dexterous fine motor skills)。在每个方面,我都会举出几个取得突破性进展的案例。
跨越不同环境的抽象能力
人工智能领域长期以来的目标是实现通用人工智能,即能够同时在不同领域内进行学习和行为的单个学习程序,它能够传递一些学到的技能和知识,比如说,学习制作饼干,并将其应用到巧克力蛋糕的制作上,结果甚至比其它方式更好。这种通用性上做出的重大迈进由Parisotto、Ba和Salakhutdinov (http://arxiv.org/abs/1511.06342)提供。他们在DeepMind开创性的DQN(深度Q网络)基础上打造了一个系统,论文于去年年初发表于《自然》 (http://www.nature.com/nature/journal/v518/n7540/full/nature14236.html#videos),该系统学会了玩很多不同的雅达利游戏。
该团队并没有为每个游戏采用不同的网络,通过深度多任务增强学习(deep multitask reinforcement learning)和深度迁移学习(deep-transfer learning)的结合,该团队在不同类型的游戏中使用了同一个深度神经网络。这不仅实现了在多个不同游戏中成功的单个实例,还带来了可根据在其它游戏中习得的知识从而更好更快学习新游戏的实例。比如,它可以更快学会一个新的网球游戏,因为它已经从玩乒乓球中习得了这个概念——利用拍子击打球的有意义的抽象。这还算不上是通用智能,但它解决了实现这一目标的一个障碍。
从不同模式中进行推理是2015年的又一亮点。艾伦人工智能研究所和华盛顿大学一直在进行人工智能考试方面的工作,多年的努力让考试水平从4年级提升到了8年级,而2015年他们宣布开发出了通过SAT几何部分考试的系统 (http://www.washington.edu/news/2015/09/21/ai-system-solves-sat-geometry-questions-as-well-as-average-human-test-taker/),考试包含了图表、补充信息和文字题。在应用相对狭窄的人工智能中,这些不同的模式通常都是作为不同的坏境分开分析的。这一系统结合了计算机视觉和自然语言处理,在同一个结构化的形式中同时将两者作为基础,然后应用几何推理回答多项选择题,使其水平达到了美国11年级学生的平均表现。
直观概念理解
2014年,这一技术帮助实现了自动编写图像标题 (http://googleresearch.blogspot.com/2014/11/a-picture-is-worth-thousand-coherent.html)的功能,而2015年,一个来自斯坦福大学和特拉维夫大学的团队将这一基本概念扩展到了联合嵌入图像和3D形状 (https://shapenet.cs.stanford.edu/projects/JointEmbedding/)上,搭建起了计算机视觉和图形的桥梁。然后Rajendran等人 (http://arxiv.org/abs/1510.03519)将联合嵌入方法进行了扩展以同时支持在不同模式和语言中多个有意义的相关映射的汇合。随着这些嵌入越来越复杂和细致,它们可以成为更复杂人工智能技术的主要推动力。Ramanathan等人 (http://web.eecs.umich.edu/~jiadeng/paper/RamanathanEtAl_CVPR2015.pdf)用它们打造了一个系统,该系统能学习来自照片集和字典的不同类型的行为之间有意义的关系模式。
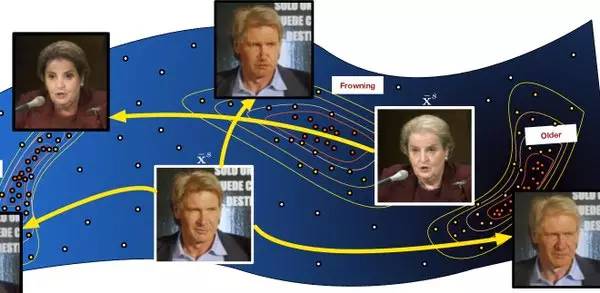
正如深度学习被预测的那样,随着单一系统越来越多地胜任多个任务,数据的特征和所学的概念之间的界限将变得模糊。这种深度功能实现的另一个示范是来自康奈尔大学和圣路易斯华盛顿大学的团队,他们通过对深度网络权重的降维形成了一个覆盖多个卷积特性的面 (http://arxiv.org/pdf/1511.06421v1.pdf),从而可以轻而易举改变照片的面貌,比如,改变人的面部表情或年龄,或给照片上色,等等。
深度学习中的另一个障碍是他们需要大量训练来产出结果。而人类则通常能从一个单一案例中学习。Salakhutdinov、Tenenbaum和Lake通过一种基于单一案例的贝叶斯程序归纳法(Bayesian program induction)达到了人类般的学习能力 (http://www.popsci.com/researchers-step-closer-to-recreating-way-humans-learn)。这一系统能迅速学会写陌生的文字,从某种意义上说明它领悟到了字符的本质特征(也就是字符的总体结构),同时还能识别出非本质特征(也就是那些因书写造成的轻微变异)。
跨越不同环境的抽象能力
在理解简单概念之上还有掌握因果结构——理解如何将想法结合在一起让事情发生或按时间顺序讲一个故事——并根据这些理解创造事物。在DeepMind的神经图灵机和Facebook的记忆网络的基本概念上,深度学习和全新存储架构的结合让2015年这个方向的发展大有希望。这些架构给深度神经网络中的每一个节点都提供一个简单的记忆接口。
Kumar和Socher的动态记忆网络(dynamic memory networks) (http://arxiv.org/pdf/1506.07285v3.pdf)在记忆网络上使用更好的对注意力和序列理解(attention and sequence understanding)的支持获得了提高。和原来一样,这个系统可以阅读故事并回答有关问题,暗含20种推理方法,包括演绎(deduction)、归纳(induction)、时序推理(temporal reasoning)和路径查找(pathfinding)。但它从未有过这些推理模式的编程。然后Weston等人最近的端到端记忆网络(end-to-end memory networks)增加了这种能力,以在每个输出符号中执行多重计算跳数(multiple computational hops),将模型能力和表现度扩展到能捕捉乱序访问(out of order access)、长期依赖(long term dependencies)和无序集合(unordered sets)等事情,进一步提高类似任务的准确性。
当然程序本身也是数据,而且当然它们具有复杂的、有因果的、结构化的、合乎语法的、序列化的性质,所以这种方法也适用于编程。2014年,神经图灵机证明程序的深度学习是可能的。2015年,Grefenstette等人展示了程序是如何被转换的,或者说通过使用一种新型的基于记忆的卷积神经网络从样本输出得到结果,这比神经图灵机高效得多。DeepMind的Reed和de Freitas最近也展示了他们的神经程序转译器(neural programmer-interpreter),它可以代表一种低级程序来控制特定领域内的更加高级的功能。
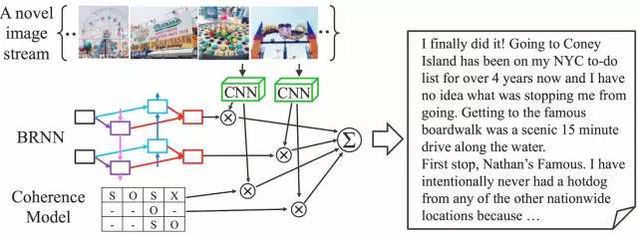
另一个擅长理解连贯时间并应用其来创造新的人工作品的案例是去年开发的一个初级但有创意的视频总结功能。首尔国立大学的Park和Kim开发了一个名叫连贯递归卷积网络(coherent recurrent convolutional network)架构,并将其用于从一系列图像中创造出新颖且流畅的文本故事。
另一个包含了因果理解、假设和创造性抽象思考的模式是关于一项科学假设。塔夫茨大学的一个团队将遗传算法和基因通路模拟(genetic pathway simulation)结合起来创造了一个系统,该系统有史以来第一次用人工智能发现了重要的新科学理论: 扁形虫到底是如何轻松地再生身体的?仅用了几天时间就解决了困扰了科学家一个世纪的问题。这同时也明确证明了为什么目前要对人工智能如此重视。
虚构想象
2015年,人工智能不停地写程序、游记和科学理论。现在还有一些人工智能可以想象,或更技术一点的说法,幻想(hallucinate)出有意义的新图像。深度学习不仅擅长模式识别,还确实能进行模式理解,并继而进行模式创造。
一个来自麻省理工学院和微软研究院的团队开发了一个深度卷积反图形网络(deep convolution inverse graphic network),该系统包含了一种特殊的获取图形代码层中神经元的训练技术,可以对图像进行差异化以得到有意义的变换图。在完成这样的任务时,它们对一个图形引擎进行深度学习,有能力从其接收到的新2D图像中理解3D形状,并能图像式地想象出拍摄角度和光照改变时所出现的结果。
来自纽约大学和Facebook的一个团队设计了一种方法,对其它图像中的元素进行有意义且合理的结合来生成新图片。使用一种pyramid of adversarial networks (http://arxiv.org/abs/1506.05751)——其中一部分尽力产生实际图像而另一部分则评价这些图像看起来有多真实——他们的系统在想象新的图像上越做越好。尽管网上例子的分辨率非常低,但我在闲暇看过一些让人印象深刻的高分辨率成果。
尽管利用场景渲染器处理符号和有限的词汇已经有一段时间的历史了,但2015年我们看到了一种纯神经系统以一种没有直接编程的方式做类似的事 (http://motherboard.vice.com/en_ca/read/computer-draw-an-open-toilet-sitting-in-a-grassy-field)。这个来自多伦多大学的团队应用注意力机制(attention mechanism)来循序渐进的生成图像。现在,机器人可以梦见电子羊了。

2015年甚至在新的动画视频剪辑的计算想象方面也有让人惊叹的进步。一个来自密歇根大学的团队创造了一个深度类比系统(deep analogy system),该系统能够识别出示例中暗含的复杂关系,并能将该关系应用为一种查询实例的生成转换(generative transformation)。他们已经将其应用到了一些合成应用中,但其中最让人印象深刻的是这个演示(如下视频),基于一个从未见过的角色的单个静态图像生成了一段新的这个动画角色的短视频,以及另一个不同角色不同视角下的比较视频。
尽管视频中所使用的图像生成方式是为了便于演示,但他们的计算想象(computational imagination)方面的技术可以跨多种领域和模式得到应用。比如可以想象将其用于声音或音乐等。
敏捷灵巧的运动能力
2015年人工智能领域的进步并不只局限在计算机屏幕上。
2015年初,德国的一个研究灵长类动物的团队 (http://www.sciencefocus.com/news/can-robots-tie-their-shoelaces)记录到了灵长类动物的手部运动与相应的神经活动之间的联系,这让他们可以基于大脑活动来预测出正在发生的精细动作,他们也能将这些相同的精细运动技巧教给机器臂,以期打造神经强化的假肢。
2015年中期,加州大学伯克利分校的团队公布了一种让机器人掌握精细运动技能的更加通用简单的方法 (http://www.nytimes.com/2015/05/22/science/robots-that-can-match-human-dexterity.html)。他们使用基于引导策略搜索(guided policy search)的深度强化学习让机器人学会了拧瓶盖、用锤子移除木板上的钉子以及其它日常工作。
这些工作对人类来说小菜一碟,但对于机器却很困难,该系统在灵活性和速度上可与人类媲美。实际上它通过尝试使用手眼协作完成任务而学习这些行为,并借助练习,在少数几次尝试之后重新修正自己的技术。
其他值得关注的领域
这里没法列出一个2015年人工智能和机器学习领域里精彩成果的完整列表,这一年中还有很多基础的发现和进展,包括我认为的一些比以上任何技术都更有革命性的成果。但它们都还处在早期的发展阶段,所以没有被包含在这里。
2015年确实有一些让人印象深刻的进展。但我们期望能在2016年见到更多。2016年,我期望看到更加先进的深度架构、更好的符号和亚符号的整合、一些亮眼的对话系统、一个最终掌握围棋的人工智能、用于更复杂机器人计划和机动控制的深度学习、高质量的视频总结和更多有创意的高分辨率的虚构;这些应该都会发生。而更让人兴奋的是那些我们无法预料的进展。
欢迎加入本站公开兴趣群
高性能计算群
兴趣范围包括:并行计算,GPU计算,CUDA,MPI,OpenMP等各种流行计算框架,超级计算机,超级计算在气象,军事,航空,汽车设计,科学探索,生物,医药等各个领域里的应用
QQ群:326600878
