Oracle Database 12.2新特性详解
在2015年旧金山的Oracle OpenWorld大会上,Oracle发布了Database 12.2的Beta版本,虽然Beta版本只对部分用户开放,但是大会上已经公布了12.2的很多重要的新特性,云和恩墨是Oracle的Beta用户,已经开始测试这一产品。在刚刚结束的“Oracle技术嘉年华”大会上,更详细的主题分享披露了更多内容。在这篇文章中,我将和大家一一来细数Oracle Database 12.2的新特性。
Oracle Sharding的实现
简单来说,Oracle的Sharding技术就是通过分区(Partioning)技术的扩展来实现的。以前一个表的分区可以存在于不同的表空间,现在可以存在于不同的数据库。
不同分区存在于不同数据库,这就将数据隔离了开来,Sharding就此实现。

Sharding如何实现数据路由?
既然数据被拆分,那么在访问时如何实现数据路由呢?在Sharding的架构里,存在一个“Shard Directories”目录库来管理Sharding的分布,当应用通过Sharding Key来访问数据时,连接池就会给出访问路径,快速指向需要访问的Shard。如果应用不指定分区键访问,则需要通过协调库-Coordinator DB来协助判定。
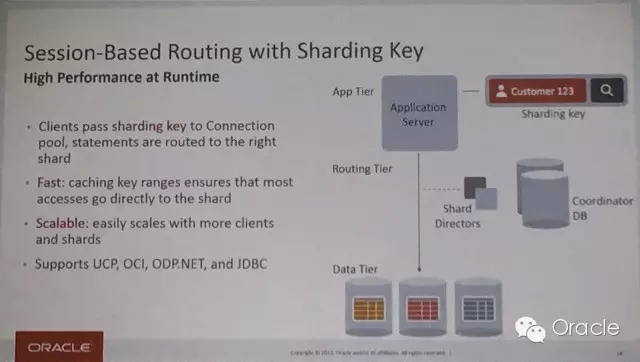
那么这里提到的连接池是什么呢?
可能很少有人注意到,在Oracle 12.1版本中增加的一个新的产品组件 GDS - Global Data Services,通过GDS可以构建一个访问“连接池”,为后端的数据库访问提供代理和路由服务,前面提到的Shard Directories,正是在GDS中配置的。
如何创建Sharding数据表?
在创建Sharding对象之前,需要先创建表空间集合 - Tablespace Set,表空间集合包含在不同数据库中的表空间定义,也就是将以前针对不同分区创建的表空间转移到不同的数据库中。

如何配置连接池?
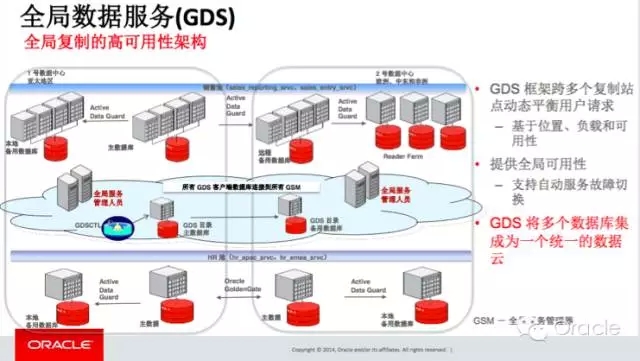
关于连接池的配置,实际上在GDS的文档中,早有描述,以下图中则详细描述了Sharded Database的部署,其中最先创建的是shardcatalog,创建了一个Shard的目录配置数据库,而GSM - Global Service Managment,就是全局的服务管理配置。

关于GDS的配置,以下一图 - 一目了然:
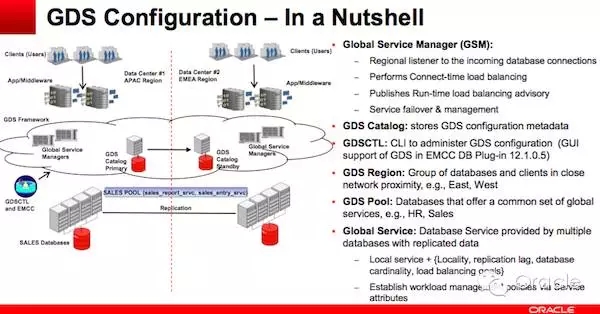
如果在12.1中还看不清楚 GDS的作用,现在12.2中,Sharding中的重要作用就日益凸现出来。
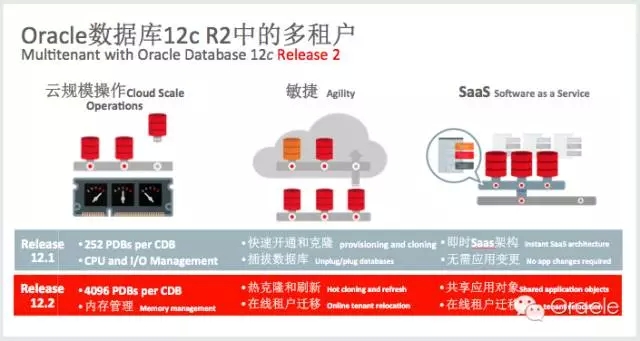
Oracle的多租户与IMO组件更新
多租户选件为云而生,也就不断向着云的便利性、自动化迈进。在12.2中多租户支持更多的PDB共存,从上个版本中的252增加到4096个;在便利性上,支持Hot Clone,支持Refresh,支持在线的Tenent转移。PDB的Hot Clone可以让数据库在业务负载运行时进行Clone拷贝,并且实时同步变化数据,从而使得数据不断追平,进而实现在线切换,这极大的改善了上云的迁移过程。对用户来说是简化,并且在OEM的管理之下,所有工作可以近乎自动的完成。
In-Memory Option在12.2上也获得了增强,这一特性在ADG上的增强使得读写进一步分离,由于ADG的只读属性,备库上的内存数据又可以和主库不同,比如备库在内存中可以存储更广泛的数据,实现实时计算。而在性能和易用性上改进也值得称道,In-Memory在12.2中支持根据热图自动向内存进行数据转移,也可以动态的清除冷数据以释放内存空间,简化用户管理。

那些温暖人心的细节改进
除了以上这些大的改进,Oracle在DataGuard的细节上也不断增强,同样温暖人心。
DBCA备库创建 - 在备库主机安装软件启动监听,则可以通过DBCA来创建备库,指向主库来获取文件;
以前DataGuard的创建已经非常简化,RMAN的操作也很精简,现在DBCA也被利用起来,更方便容易了,够体贴吧?

口令文件维护 - 标题中用了“Headache”,可见以前多头疼
以前大家可能都被口令文件的变更坑过,现在这一切自动维护了,够温暖吧?

AWR支持远程快照 - AWR支持捕获远程数据库的信息,包括ADG
要知道在之前的ADG中,备库只能通过Statspack来进行性能分析和诊断,现在可以支持AWR了,够高级吧?

连接保持 - 在进行DataGuard切换过程中,保持会话连接
对于ADG,终于,Oracle自己人也说“终于”,实现了Failover、SwitchOver中的连接会话保持,这极大的改善了用户体验,够给力吧?

自动块修复增强 - ADG自动块修复自11gR2引入,现在已经非常成熟,修复的类型大大增加;

12.2 DataGuard中并行日志应用
要知道在12.2之前,DG的备库只能由一个实例通过MRP进程进行应用,现在可以在多实例并行进行。
在8节点的RAC环境中,可以实现3500MB+/sec的应用速度,这极大的改善了大数据量备库环境中的同步效率。

多实例应用,可以在所有Mounted或者Open的实例上并行进行,在执行Recover时,类似如下一条命令即可指定并行的恢复实例:
recover managed standby database disconnect using instances 4;
我们可以对比一下单实例应用和多实例应用的架构对比,在常规模式下,多实例的备库,可以有多个Remote File Server (RFS)进程进行Redo Thread的日志接收,但是仅有一个实例进行Managed Recovery Process (MRP)应用恢复:
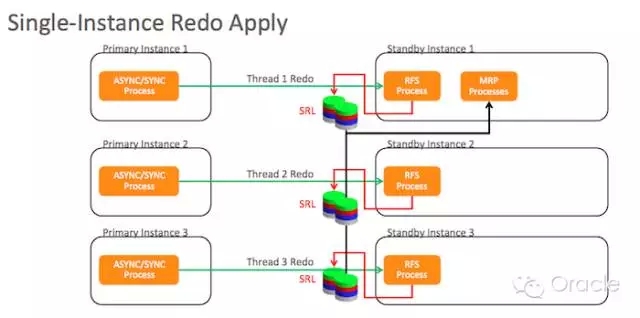
当然,在单个实例上,仍然可以启动多个MRP进程,进行并行的恢复,以下引自官方文档:
The managed recovery process (MRP) applies archived redo log files to the physical standby database, and automatically determines the optimal number of parallel recovery processes at the time it starts. The number of parallel recovery slaves spawned is based on the number of CPUs available on the standby server.
在PayPal的分享的“Internals About DataGuard”中,有一页关于MRP在RAC上的描述可以供参考(关注公众号回复“PayPal”可以获得本文档):

在Oracle 12.2 的版本中,多实例并行MRP恢复被支持,以下架构图详细说明了这一改进。通过一个Coordinator进程进行协同,多个MRP进行可以并行进行Redo Apply。
这一改变将极大的提升DataGuard的效率和可用性:
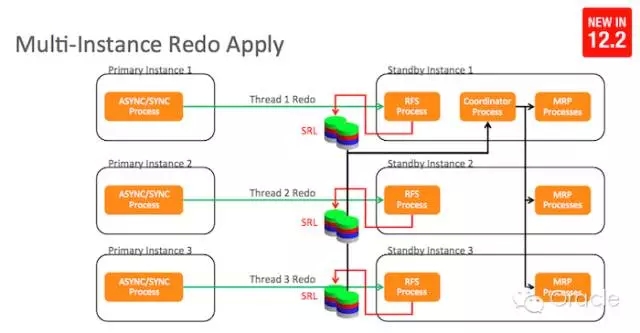
这是否又一温暖人心的特性增强?
在RDBMS数据库中,Oracle无论在大处的张扬,还是小处的体贴,都让人越来越喜爱这个产品。云时代,一起加油吧。
