当今世界最牛的25位顶尖大数据科学家
译者:一只鸟的天空
引言
在大数据技术飞速发展的今天,谁才是我们大数据科研与工业界中最有威望的科学家呢?下面我们来进行梳理,共罗列了25位当今世界,无论是在学术与工业界都产生巨大影响的数据科学家(Data Scientists)。他(她)们推动了整个领域的发展,毫无疑问,无论是在学术界还是还工业界,他(她)们都是一座座山头式的人物。他(她)们是我们这些从事大数据产业发展的榜样。他(她)们便是所谓的大师级人物。
数以万计的数据从业者通过他(她)们的论文、博客、视频、讲义等进行学习与进步,并找到相应的应用场景解决方案。这些大师为人们解开了统计机器学习、神经网络以及深度学习的神秘。
下面从三个类别对这25位大师进行简介,虽然这个分类可能并不那么恰当,但是可以加深读者对他(她)们的了解。
科研学术界大师(Research Oriented Data Scientists)
这些科学家全身心致力于在数据中发明新的算法或者模型,他(她)们更倾向于学术与科研界的创新与创造。
工业界应用大师(Data Scientists Turned Entrepreneurs)
这些科学家致力于将技术转变为生产力,应用数据技术去创造产品和服务。
实践中的大师(Data Scientists in Action)
显然,并不是说上面两类大师不是实践派。只是为了强调这类大师将数据科学引入到实践当中所作的贡献。
为了便于大家去全面深入得了解和学习这些数据大拿,本文所列举的每个大拿都有其链接(LinkedIn/Twitter).
Research Oriented Data Scientists: 科研学术界大师
Geoffrey Hinton

只要是在机器学习届混的或者懂点机器学习的人们,抑或懂点神经网络的人们,相信都知道“Back Propagation“反向传播的鼎鼎大名。Hinton便是将BP算法应用到神经网络与深度学习中人员之一,并且是主导者(co-inventor). Hinton 提出了“Dark Knowledge”黑暗知识概念(“Dark Knowledge”这本书籍已经出版,亚马逊上面有卖,288RMB,可见其nb性),该概念是受小概率比率事件中的“大部分知识”对于训练与测试中的代价函数是没有影响的。Hinton在人工智能领域中无人不知无人不晓是因为其在人工神经网络(Artificial Neural Networks)中所作出的贡献。
早在上世纪60年代,Hinton在高中时期,就有一个朋友告诉他,人脑的工作原理就想全息图一样。创建一个3D全息图,需要大量的记录入射光被物体多次反射的结果,然后将这些信息存储在一个庞大的数据库中。大脑存储信息的方式与全息图类似,大脑并非将记忆存储在一个特定的地方,而是砸整个神经网络里传播。从此,Hinton对神经网络深深得着迷。他在剑桥大学学习心理学期间,发现科学家们并没有真正理解人类大脑,人类大脑有数十亿个神经细胞,它们之间通过神经突触互相影响,形成极其复杂的相互联系,然而科学家们并不能解释这些具体的影响和联系。神经到底是如何进行学习以及计算的,对于Hinton,这些正是他所关心的问题。Hinton在爱丁堡大学获得了人工智能的博士学位,现为多伦多大学的特聘教授。在2012年获得了加拿大2012年基廉奖(Killam Prizes,Killam Prizes是有“加拿大诺贝尔奖”之称的国家最高科学奖)。在2013年,他加入Google,并带领一个AI团队,目前正进行着Google Brain项目。
他和他的团队强力将“神经网络”从垂死边缘一步步带入到当今的研究与应用的热潮,变成了炙手可热的的学术界课题,将“深度学习”从边缘课题变成了Google等互联网巨头仰赖的核心技术。目前神经网络与深度学习已在自然语言处理、语音处理以及计算机视觉等领域中得到了空前广泛与成功地应用。越来越多的科学家从事神经网络与深度学习的研究工作。换句话说,深度学习是目前的主流,我们不再是极端分子了。
Yann Lecun

Lecun在多伦多大学随Hinton读博士后,即他是Hinton的学生。他是另一个神经网络与深度学习大拿。他在皮埃尔玛丽居里大学(又称巴黎第六大学, Université Pierre et Marie Curie (Paris VI))获得了计算机科学博士学位,期间提出后向传播算法。他如今在Facebook带领团队进行人工智能工作,即他是Facebook人工智能实验室的负责人。他在纽约大学任职了12年,是纽约大学的终身教授,是纽约大学数据科学中心的负责人。为了表彰他在深度学习领域里所作出的贡献,IEEE计算机学会颁给他著名的“神经网络先锋奖”,在2014年北京计算智能大会上授予。在加盟Facebook之前,Lecun已在贝尔实验室工作超过20年,期间他开发了一套能够识别手写数字的系统,叫作LeNet,用到了卷积神经网络(Cnvolutional Neural Networks, CNN),已开源。他研发了很多关于深度学习的项目,并且拥有14项相关的美国专利。他甚至开发了一种开源的面向对象编程语言Lush,比Matlab功能还要强大,并且也是一位Lisp高手。他在机器学习、深度学习、计算机视觉、计算神经科学领域进行了深度研究。
Yoshua Bengio

Bengio是另外一位机器学习、深度学习的大拿。他在麦吉尔大学获得博士学位。他是ApSTAT技术的发起人与研发大牛。他也是蒙特利尔大学(Université de Montréal)的终身教授,任教超过22年,是机器学习实验室(MILA)的负责人,是CIFAR项目的负责人之一,负责神经计算和自适应感知器等方面。又是加拿大统计学习算法学会的主席,并且是NSERC-Ubisoft主席以及其它。在蒙特利尔大学任教之前,他是AT&T & MIT的一名机器学习研究员。他的主要贡献在于深度学习与人工智能等领域。
Jurgen Schmidhuber

他致力于构建一个自完善的人工智能机器。他曾任职于南加州大学,现任于卡内基梅隆大学语言技术研究所。他是著名的自然语言处理学者与专家,是国际计算语言协会(ACL)的首批Fellow,曾任ACL2001年主席。他主要的研究工作是机器学习、RNN(Recurrent Neural Networks,递归神经网络)、深度学习、计算机视觉以及自然语言处理等。他早机器翻译、自动文摘、自动问答、文本理解等领域作出了杰出的贡献。他自述目前自己最感兴趣的两个方向是语言计算机理解:计算机对一篇整体的文本而不是对一个个句子进行孤立的理解,这中间需要进行指代消解、实体解析和实体链接等很多工作。另一个是社会媒体,他目的并不是研究连接网络的拓扑结构,而是研究流经网络的海量的实时化的内容,从而发现人的性格、角色和特长等。他的研究已广泛应用于Google、Microsoft、IBM、Baidu、Facebook、Twitter等公司,特别是在递归神经网络中作出的贡献,如广泛使用的LSTM(Long Short-Term Memory,长短时记忆)与最新的据说胜过LSTM的CW-RNN(Clockwork RNN,时钟驱动递归神经网络)。他已经发表了333篇论文,有7篇最佳论文。获得了2013年国际神经网络社会(International Neural Networks Society)的Helmholtz奖(亥姆霍兹奖),并获得2016年该会议的先锋奖。
Alex “Sandy” Pentland

在过去的29年时间中,Perntland都任职于MIT(麻省理工大学)的教授。在这期间,他创建多个公司,如IDcubed.org、Sense Networks、Cogito Health、 Ginger.io等。根据他所取得的成就,福布斯(Forbes)称他是世界上最有力量的数据科学家(the ‘World’s Most Powerful Data Scientist’ )。他也被任命为多个跨国公司(MNCs)的顾问(an advisor),如Nissan、Motorola、HBR、Telefonica等。他的主要兴趣在机器学习、人工智能与人类计算(Human computing)等领域。
Peter Norvig

Norvig目前任职于Google。在此之前,他在NASA工作了六年,担任计算科学部门的负责人,期间获得了NASA杰出贡献奖(Exceptional Achievement Award)。是ACM、AAAI等的Fellow。他在加利福尼亚大学伯克利分校(University of California, Berkeley)获得了计算机科学博士学位。他的兴趣在于人工智能(AI),自然语言处理(NLP)和机器学习等领域。
Corinna Cortes

Cortes目前是google的研究员。她在哥本哈根大学(University of Copenhagen)获得物理学理学硕士,并加入贝尔实验室(AT&T Bell Labs),在此工作超过十年。并在罗切斯特大学(University of Rochester)获得了计算机科学博士学位。她的研究主要在人工智能、机器学习、自然科学通论、算法与理论等方面。并且她是一位拥有两个孩子的妈,可谓是人生赢家。
Micheal I Jordan

Jordan是加利福尼亚大学伯克利分校电子工程系和计算科学系陈丕宏(Pehong Chen)特聘教授(Distinguished Professor)和(UC Berkeley)统计学系的特聘教授。他近些年的研究工作主要集中在无参数贝叶斯分析、概率图模型、谱方法、核方法以及信号处理中的应用等方面。其中,他便是聚类算法中广泛使用的基于规范切(Normalized cut)谱聚类算法提出者之一。他获得了多个举足轻重的奖项,如数理统计学会(Institute of Mathematical Statistics ,IMS)授予的Neyman Lecturer 和Medallion Lecturer。他获得了加利福尼亚大学伯克利分校的认知科学博士学位,并且是麻省理工大学(MIT)的教授。
Data Scientists Turned Entrepreneur 工业界应用大师
Andrew Ng

Andrew Ng中文名为吴恩达,他和Daphne Koller共同创建Coursera(在线教育平台)这一流大学在线课程平台。他2014年5月16日加盟百度,成为百度首席科学家,带领百度大脑计划项目,负责百度研究院,开展深度学习和大数据与人工智能可伸缩性方法。他又是斯坦福大学(Stanford University)的计算机科学系与电子工程系的副教授,人工智能实验室主任。他于1997年获得了卡内基梅隆大学(CMU)的计算机科学学士学位,1998年获得了麻省理工大学(MIT)硕士学位,并于2002年获得加州大学(加利福尼亚大学的简称)伯克利分校(UC Berkeley)的博士学位,并从这一年开始在斯坦福大学任教。
在加盟百度之前,他已经在google工作了几年,在XLab团队开发无人驾驶汽车和谷歌眼镜等项目,并与其他google工程师合作建立了全球最大的人工神经网络,名为Google Brain(Baidu Brain就是模仿它),对于普通数据从业者最熟悉的莫过于斯坦福大学机器学习公开课(该课是多少机器学习从业者入门的课程,其中我也是)以及使用利用团队所开发的人工神经网络通过观看一周YouTube视频,自主学习与自动识别哪些是关于猫的视频。他是人工智能和机器学习领域国际上最权威的学者之一。他2007年获得了斯隆奖(Sloan Fellowship),2008年入选“the MIT Technology Review TR35”,即《麻省理工科技创业》杂志评选出的科技创新35俊杰,以及计算机思维奖(Computers and Thought Award),并在2013年入选《Time》杂志年度全球最有影响力的100人之一,共16位科技界人物。他的主要兴趣领域在机器学习、深度学习、机器人、人工智能、计算机视觉等方面。
ps:为啥看起来像亚洲人,因为他父亲是一名香港医生,即他是华裔。
Daphne Koller

Koller也是在线教育平台Coursera的负责人和共同发起人之一。她在耶路撒冷希伯来大学(The Hebrew University of Jerusalem)攻读学术与硕士学位,在斯坦福大学获得计算机科学博士学位,在加州大学伯克利分校攻读博士后。现为斯坦福大学教授。在攻读博士期间,获得了很多奖项,如杰出青年科学家奖(ONR Young Investigator Award)、ACM Infosys 基金(ACM Infosys由Infosys公司创立于2007年8月。旨在奖励在计算机科学界做出杰出贡献并有深远影响的人才)、2001IJCAI计算机和思维奖(Computers and Thought Award)、麦克阿瑟奖(MacArthur Foundatin Fellowship,俗称“天才奖”,被视为美国跨领域最高奖项之一)。她已在斯坦福大学任职了18年。她的主要兴趣领域是机器学习、人工智能与模式识别等。
Hilary Mason

Mason是快速前进实验室(Fast Forward Labs)的发起人,也是hackNY.org与DataGotham的联合创始人。在此之前,她在Bitly担任首席科学家,和强生威尔士大学(Johnson & Wales University)的助理教授。她在2011年进入Fortune(财富杂志)评出的40岁之下的财富前40(Fortune 40 under 40)与克雷格财富40周岁前40(Craig’s 40 under Fort),并获得2012年TechFellow Engineering Leadership Award。她的主要兴趣领域在机器学习、数据挖掘与Python。
Sebastian Thrun

Thrun是Udacity的创始人与CEO。在此之前,他创建了Google X(Google X秘密实验室是Google最神秘的一个部门,探索前沿科学技术与未来,这里汇聚了其它高科技公司、各大高校和科研院所挖过来的顶级专家,可能是梦想实现之地,但是也有可能会失败)并作为副总裁(Vice President,VP)在Google工作了7年,并在斯坦福大学担任研究教授(Research Professor)。他旨在大众化教育,让每个人都有机会学习世界各地的课程。他的梦想是让世界上每个人接受到更好的教育是这个世界更加美好。他的主要研究领域是机器学习与人工智能。
Jeff Hammerbacher

Hammerbacher追随DJ Patil,并提出数据科学家(Data Scientist)这个词。他是Cloudera项目的创始人以及首席科学家。在此之前,他在Facebook带领数据团队,该团队负责Facebook的统计与机器学习的应用项目。他也是西奈山医学院(Mount Sinai School of Medicine)的助理教授。他在哈佛大学(Harvard University)获得数学学士学位。他的主要兴趣在大数据、机器学习、Hadoop以及数据挖掘等领域。
Jeremy Achin

Achin 是 Data Robot(数据机器人 )的联合创始人。DataRobot 聚集着世界上最好的数据科学家们,已经成为了美国成长最快的数据公司。在此之前,他是Travelers Insurance的研究与建模的领导者。他是 Kaggle竞赛(机器学习领域的一个竞赛) ,他的安全系数模型排名top10%。他的主要兴趣领域是预测模型、数据挖掘与机器学习等。
Carla Gentry

Gentry是Analytical Solution的一名数据科学家和创建者。她在纳西大学(University of Tennessee)获得数学与经济学硕士学位。她已在世界财富500强公司工作超过15年,如Hershey、 Kraft、Johnson & Johnson、Kellogg’s 和 Firestone。她是Twitter上大数据社区的粉最多的大V之一,被信息周刊(Information Week)评为Twitter上的十位最有影响力的IT领导者之一(“10 IT Leaders to Follow on Twitter”)。
Data Scientists in Action 实践中的大师
DJ Patil

Patil现担任白宫首席数据科学家和制定数据策略的副首席技术官,奥巴马亲自招募他的。在此之前,他担任Salesforce.com的RelateIQ产品的副总裁(Vice President,VP),是LindedIn的数据产品负责人和首席科学家,他的父亲是一名风险投资家(venture capitalist ,VC)和Cirrus Logic的创始人。他在多个公司工作过,如LinkedIn、Greylock Partners、Skype、PayPal 和 eBay。他曾一度在美国国防部工作,使用社会网络分析来预测新的威胁。他早年在迪安萨学院( De Anza College)学习,并在加州大学圣地亚哥分校(University of California, San Diego,)获得数学学士以及在马里兰大学帕克学院(University of Maryland College Park)获得应用数学博士学位。他曾使用美国国家海洋和大气管理局(NOAA)公开的数据集来提高天气预测的准确性。他和Thomas H. Davenport一起发表了一篇哈佛商业评论性文章(HBR)– “Data Scientist: The Sexiest Job of 21st Century”。他获得了很多专利。他当选为2014年世界经济论坛全球青年领袖。
Adam Coates

Coates在斯坦福大学获得计算科学博士学位。目前,他被任命为百度硅谷人工智能实验室的高级主管(Senior Director at Baidu Silicon Valley AI Lab)。他的研究兴趣主要是机器学习、深度学习、控制和机器人(Control & Robotics)。
Monica Rogati

Rogati在新墨西哥大学(The University of New Mexico,UNM)获得计算机科学学士学位,在卡内基梅隆大学(Carnegie Mellon University,CMU)获得计算机科学硕士与博士学位。她现为Insight Data Science的数据科学顾问。在此之前,她在LinkedIn工作,担任高级数据科学家。以及在Jaw Bone担任副总裁(VP),并负责多个职位的工作。她的目标是将数据转化为产品以及可行的解决方案(actionable insights)。她的主要兴趣领域在机器学习、文本挖掘(Text Mining)、推荐系统(Recommender Systems)等。
Oliver Grisel

相信大家都听说过 Scikit-learn 这个非常流行与广为人知的基于Python的机器学习开源库,目前最新版本为0.16,该机器学习库包括分类、回归、聚类、降维、模型选择以及数据预处理等模块。(PS:什么,你不知道这个开源库,好吧,回去好好学习吧)。Grisel便是这个开源项目的主要负责人之一。他主要负责该项目的Talk与视频教程(talks and tutorial sessions )和预测模块。他目前任职于Inria Parietal的软件工程师职位,主要负责提升Scikit-learn和其它工具库的效率等方面。他获得伦敦帝国理工学院(Imperial College of London)的先进计算硕士学位。他对将机器学习应用到自然语言处理和知识提取特别感兴趣。
Owen Zhang

Zhang目前担任Data Robot的首席产品官(Chief Product Officer)。他是 Kaggle竞赛 目前世界上排名第一。并多次获得了亚军。在任职Data Robot之前,他在AIG(美国国际集团)担任副总裁,在Travelers Insurance担任科学家和高级主管、分析师和研究员。他在多伦多大学(University of Toronto)获得硕士学位。他的主要兴趣领域是预测模型、数据挖掘等。
Sergey Yurgenson

Yurgenson目前在Data Robot担任数据科学家。在此之前,他是哈佛大学医药学院(Harvard Medical School)的一名研究教授,已在此工作了13年。他开始是一名物理学家,在圣彼得堡国立大学(St. Petersburg State University)获得了物理学博士学位。后来开始对分析学产生浓厚的兴趣,并不断进行数据研究。他是2012年十位数据科学家之一,目前排名世界第16位。到目前为止,Yurgenson以及赢得了几次Kaggle竞赛的冠军。他酷爱去解决具有挑战性的问题,并提出创新与非传统的解决方案。
Stanislav Semenov

Semenov在Kaggle竞赛中排名世界第三。他已经获得了多个比赛的冠军,包括奥拓集团产品分类挑战赛(Otto Group Product Classification Challenge),目前是一名数据科学家顾问。另外,他是Yandex学院的一名数据分析教授。他在俄罗斯国家研究大学(National Research University (Russia))获得了应用数学与信息学的硕士学位。
Gilberto Titericz Jr.

Titericz是一名电子工程师,但是他又是一位数据科学家,并在Kaggle举办的机器学习与数据挖掘竞赛中排名世界第二。目前,他任职于巴西石油公司Petrobras,担任自动化工程师。在此之前,他曾在多个跨国公司(MNCs)内工作,如西门子(Siemens)、诺基亚(Nokia)等。在从事8年电子信息工作后,在2008年,他发现他最大的兴趣是数据科学,从此以后,一直从事数据科学的工作与研究。
Kirk Borne

Borne目前担任博思艾伦(Booz Allen Hamilton)公司的高级数据科学家。他不仅仅是一名数据科学家,而且还是一名天体物理学家和空间科学家(Astrophysicist and Space Scientist)。在2014年被评为IBM大数据与分析英雄。他还在Ted Talk中开设了“大数据,小世界”(Big Data,Small World)课程。除了任职于博思艾伦,他还是很多其它公司的顾问委员会成员。他在加州理工学院(California Institute of Technology)获得了天体物理学博士学位。
Doug Cutting

在大规模计算圈与数据挖掘与机器学习从业者与研究者中,我相信Hadoop是无人不知无人不晓的吧,Doug便是Hadoop之父,也是Apache Lucene、Nutch、Hadoop、Avro等开源项目的发起者与这些项目存在的原因。目前,其在Cloudera担任首席架构师。在加盟Cloudera之前,他在多个跨国公司(MNCs)工作,如Apple、Yahoo等。在过去14年中,他一直在Apache Software Foundation中工作。他是在斯坦福大学获得的学士学位。
总结
到这里,文中已经列举25位从事数据技术的数据科学家,他(她)们都是需要我们去仰慕的大牛级人物。从这些大拿中,可以发现他(她)们的共同特征,便是 他(她)们都是从事着自己的爱好与梦想相关的工作,并一致坚持, 特别是前面几位,像Geoffrey Hinton、Yann Lecun、Yoshua Bengio、Andrew Ng等这些从事神经网络与深度学习的研究和应用的大牛, 他(她)们在以前被认为是一些极端分子,深度学习是边缘科学,在不断批判中与神经网络深度学习,他(她)们一直坚持下来,并最终得到了广泛的应用。
这些大牛在一些顶级会议与期刊发表了大量的论文,如Science、NIPS、ICML、ACL、CVPR、ICLR、IJCAI、ICPR等。
关于神经网络,在50年代末,F·Rosenblatt提出了“感知机”,它是一种多层次的神经网络。该项提出首次把人工神经网络从理论付诸到实践中。任何新生事物向前发展势必会遭到当前势力的打压,更何况,F·Rosenblatt时一个二流水的学者,并且不懂人情事故,到处张扬。那么新事物的出现肯定会挤掉一部分旧的事物,抢到一部分人的饭碗。于是符号逻辑学派的领军人物Minsky(据说是F·Rosenblatt的高中学长)就出来进行打压,在60年代中下发现感知机这玩意对逻辑学里面的一个基本问题XOR却无能无力。于是开始写文炮轰感知机。于是,60年代末开始,人工神经网络进入低潮。
这之后,虽然有提出多层感知器结构(MLP),但是带来的网络的复杂性,从而没有有效的学习方法。80时代末,研究者提出了BP算法,给人工神经网络带来了新的希望,并且该方法在浅层神经网络模型的非常有效。于是掀起了基于统计模型的机器学习热潮,这个热潮一直持续到今天。在90年代,基本上是SVM的天下,而浅层人工神经网络复杂,学习速度慢,容易出错,理论不足的缺点导致其较为沉寂。
2000年以来,随着互联网的高速发展,对大数据的智能化提出了更高的要求。随着大规模存储与计算工具的发明,浅层学习模型在互联网应用中取得了巨大成功,如搜素广告系统(Google的AdWords、百度的凤巢系统)的广告点击率CTR预估、网页搜素排序(如Yahoo、Google、B百度的搜索引擎)、垃圾邮件过滤系统、以及个性化推荐(Amazon等)。并且随着要求的提高,开始由浅层网络向深层网络研究。
在2006年前,所尝试的深度网络架构的学习都失败了,从而导致ANN只有一层或两层隐藏层。2006年,受Hinton的革命性的深度信念网(Deep Belief Networks,DBNs)的引导,Hinton[1]、Bengio[2]、Ranzato与LeCun[3]的三篇文章将深度学习带入热潮,将其从边缘学科变为主流科学与技术。目前深度学习在计算机视觉、语音识别、自然语言处理等领域取得了巨大的成功。
自2006年以来,深度学习在学术界持续升温。斯坦福大学、纽约大学、加拿大蒙特利尔大学等成为研究深度学习的重镇。2010年,美国国防部DARPA计划首次资助深度学习项目,参与方有斯坦福大学、纽约大学和NEC美国研究院。支持深度学习的一个重要依据,就是脑神经系统的确具有丰富的层次结构。一个最著名的例子就是Hubel-Wiesel模型,由于揭示了视觉神经的机理而曾获得诺贝尔医学与生理学奖。除了仿生学的角度,目前深度学习的理论研究还基本处于起步阶段,但在应用领域已显现出巨大能量。2011年以来,微软研究院和Google的语音识别研究人员先后采用DNN技术降低语音识别错误率20%~30%,是语音识别领域十多年来最大的突破性进展。2012年,DNN技术在图像识别领域取得惊人的效果,在ImageNet评测上将错误率从26%降低到15%。在这一年,DNN还被应用于制药公司的DrugeActivity预测问题,并获得世界最好成绩,这一重要成果被《纽约时报》报道。
今天Google、微软、百度、Facebook、Twitter、Alibaba等知名的拥有大数据的高科技公司争相投入资源,占领深度学习的技术制高点,正是因为他们都看到了在大数据时代,更加复杂且更加强大的深度模型能深刻揭示海量数据里所承载的复杂而丰富的信息,并对未来或未知事件做更精准的预测。
如果你热爱数据,你热爱数据科学,那么follow这些大牛。站在巨人的肩膀上学习!!!
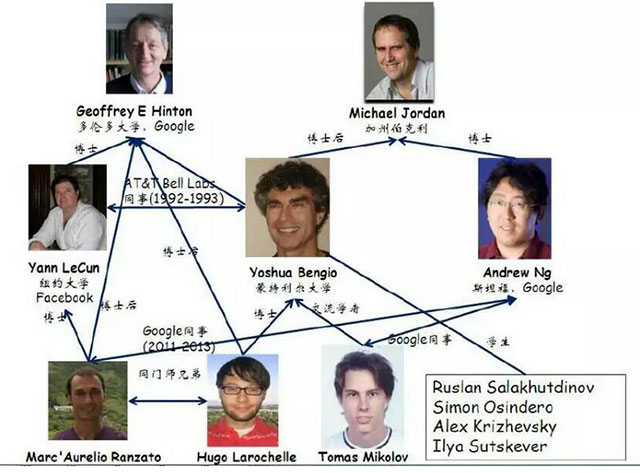
最后贴一张图,你们感受一下(图片中部分人不在文章中,文章中的大部分人也不在图中):