盘点大数据生态圈,那些繁花似锦的开源项目
随着互联网和移动互联网的发展,时下我们正处在一个大数据的时代。在数据金山的诱惑下,各个机构纷纷开始探索从数据中提取洞见并指导实践的可能。而在这个需求的刺激下,在过去数年,大数据开源生态圈得到了长足的发展——在数据的整个生命周期中,从收集到处理,一直到数据可视化和储存,各种开源技术框架林立。
以这些开源技术为基石,业内涌现出一系列令人敬佩的大数据架构实践,而《程序员》电子刊9月B大数据实战与技术专题则摘录了电商、金融、游戏等行业的大数据应用,并覆盖了当下热门的大数据开源技术实践与技术细节,如Hadoop、Spark、Docker等,详情参阅《程序员》电子刊9月B。而在本文中,笔者将带大家一览这些精彩实践赖以成型的根本——繁华的开源大数据生态圈。
资源调度与管理
谈海量数据处理,机构首先面临的就是对系统进行扩展,其中又分为纵向扩展和横向扩展两种方式。首先看纵向扩展,对于大型IT机构来说,抛开成本不谈,用单机去应对海量数据显然已不切实际,因此各个机构不得不在横向扩展上寻找出路,也就是所谓的集群计算方式。聚焦集群计算,资源调度无疑构成了整个计算模式的基础。在这个领域,YARN无疑最为耀眼,被广泛部署于生产环境。然而,受限于资源粒度控制和隔离性等问题,Mesos同样备受瞩目,并在一些拥有深厚技术资本的公司得以使用,比如Apple、Twitter等。
分布式文件系统
在资源调度之外,大数据这一块最主要的基础无疑当属分布式文件系统,而历经数年发展,HDFS显然已独占鳌头,同时也是MapReduce、Spark和Flink等系统的默认文件系统。关于HDFS细节相信已无需详述。
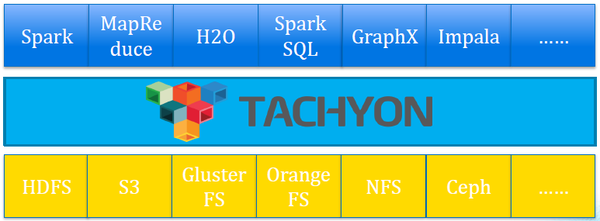
出于业务对速度的追求,在内存速度远高于磁盘价格又逐渐降低的情况下,机构使用内存来缓存大量数据已愈来愈普遍。而基于当下内存计算框架存在的普遍挑战,内存文件系统Tachyon得到了显著地关注,并在大量场景中得以部署,就拿下文提到的Spark来说:可以用作不同计算框架的数据共享,以避免磁盘IO;用以缓存数据,从而避免了JVM崩溃时的数据丢失并缓解GC开销。此外,Tachyon还被用作远程数据缓存,服务于即席查询。在内存为王的时代,Tachyon前景不可小觑。
分布式计算类别
时至今日,随着业务的不断发展,分布式计算可大体分为3个方向——批处理、流计算和即席查询。而针对这3个不同领域,大数据生态圈内同样存在大量值得参考的框架。
1. 批处理
在开源大数据处理上,业内最早接触的无疑就是MapReduce,同时也是当下生产环境部署最多的计算框架。然而正如上文所述,缺乏对内存的有效利用,效率比较低的MapReduce同样面临着大量的竞争者,其中两个备受关注的就是Spark和Flink。
Spark出自伯克利AMPLab之手,基于Scala实现,从开源至今已吸引了越来越多企业的落地使用,仅国内比较知名的大规模部署就有百度、阿里、腾讯等。Spark最主要抽象概念是弹性分布式数据集(RDD),在内存中储存数据,只有在需要时才会访问磁盘,在迭代计算上具有明显优势。同时需要注意的是,Spark并不是一个完全基于内存的计算平台。
Flink于今年跻身Apache顶级开源项目,与HDFS完全兼容。Flink提供了基于Java和Scala的API,是一个高效、分布式的通用大数据分析引擎,其主要借鉴了MPP的思路。更主要的是,Flink支持增量迭代计算,从而系统可以快速地处理数据密集型和迭代任务;同时,即使内存被耗尽,通过内存管理组件、序列化框架和类型推理引擎,Flink也可以正常运行。
2.流计算
当下知名度比较高的开源流式计算框架有Storm/JStorm、Spark Streaming、Flink、S4、Samza。其中S4出现的比较早,但是基于该项目的活跃度,这里不再讨论。
Storm编程模型简单,显著地降低了进行实时处理的难度,也是当下最人气的流计算框架之一。同时,对比其他计算框架,Storm有一个更低的延时(毫秒级)。此外,历经数年发展,Storm也更加成熟,在容错性、扩展性、可靠性上都有不俗的表现。
Samza出自于LinkedIn,构建在Kafka之上的分布式流计算框架,于今年年初跻身于Apache顶级开源项目。与Storm的区别是,Samza可以直接利用YARN。
Spark Streaming。严格来讲,Spark Streaming该归属于批处理,其处理机制是将数据流分解成一系列小的RDD,通过时间窗来控制数据块的大小。 虽然Spark Streaming在实时性上略微逊色,但却拥有更大的吞吐,并且可以轻松的与Spark其它组件结合,发挥更强大的作用。
Flink支持delta-iterations,在迭代中可以显著减少计算。同时,在处理方式中,Flink是一行一行处理,从而能获得与Storm类似的性能。然而,对于SQL支持和社区活跃度上,Flink都稍逊Spark一筹。
3. 即席查询
即席查询当下比较受关注的有Hive、SparkSQL、Presto、Impala、Drill等,其中Hive借助于Hadoop的东风,已然在生产环境得到广泛使用。在Hive之外,关注度最高的无疑是Spark SQL。Impala出自知名大数据创业公司Cloudera,在沉寂了一段时间后,当下亦有了复苏的迹象。Presto来自Facebook,类似于Impala的一个即席查询工具,在该公司内部得到广泛使用,而国内也在一些知名公司得到部署,比如美团。Drill则是Google Dremel的开源实现,于今年5月发布了里程碑版本1.0,稍显年轻。
大数据开源生态繁花似锦
在大数据领域,除下上述几个分布式计算类别之外,在图处理和机器学习领域同样存在许多优秀的开源技术框架,比如:图计算开源技术Spark Graphx、PowerGraph、Giraph、Neo4j等;机器学习开源技术Spark MLlib、Mahout、PredictionIO等。同时,开源技术已经占领了数据从收集到可视化和存储的整个流程,比如:用于数据收集的Flume(NG)和Sqoop,分布式消息队列技术Kafka、RabbitMQ,用于数据可视化的HighCharts、D3.js、Kibana、Echarts等等。此外,加之Cassandra、HBase、MongoDB、Redis等NoSQL,Lucene、Solr、ElasticSearch等搜索技术,Docker等容器技术,ZooKeeper等分布式应用程序协调服务,整个大数据开源生态繁花似锦!
