大数据的10个技术前沿(中)
吴甘沙院长从大数据技术前沿的十个问题入手,对大数据产业进行了深度解析。讲座分为三部分:
大数据的10个技术前沿(上)——数据,12月25日已发
大数据的10个技术前沿(中)——计算,本期
大数据的10个技术前沿(下)——分析,待续
演讲正文:

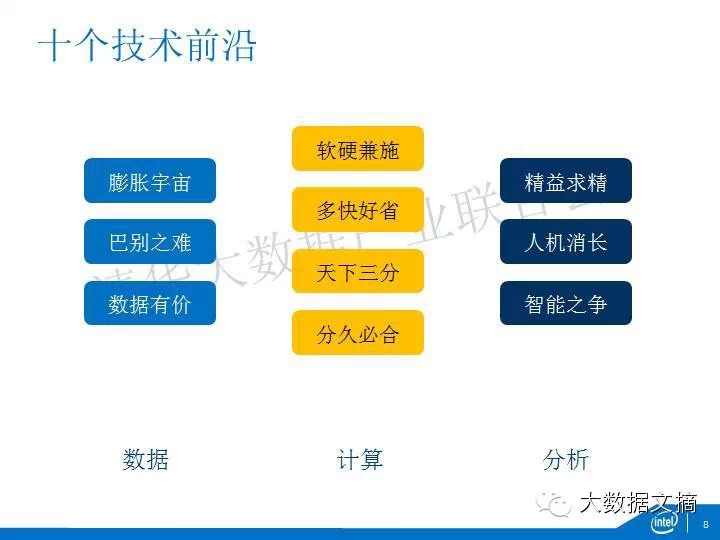
第四,软硬兼施。就是软的硬的两手抓。

首先,对大数据来说,一定要选择更好的硬件架构。体现在:计算、存储、互联。在计算这一块,首先要选择的是大小核,Brawny cores是大核,主要是至强服务器芯片,wimpy cores是小核,主要是ARM服务器芯片。前几年大小核争得很厉害,但最近随着某些ARM服务器芯片厂商破产,大家都比较明白了,对于绝大多数大数据应用,大核肯定优于小核。大家可以关注一下两个人的论述,一个是Urs Holzle,谷歌基础设施的一把手,另一个是James Hamilton,亚马逊AWS的主要架构师。
第二,异构计算。首先是集成异构多核,英特尔有一类服务器芯片,在一个芯片上同时集成了CPU和GPU,现在百度在研究利用这类芯片做深度学习的可能性。第二类是GPGPU,单独的GPU的卡来做,比如大家都在用的深度学习框架Caffe就有针对GPGPU的优化。类似的,英特尔也有Xeon Phi,也就是世界排名第一超级计算机天河2号中用的芯片。目前来说,GPGPU和Phi都是插在PCIe插槽上的加速器,它们的加速性能都受到PCIe带宽的限制。明年Phi的新版本可以独立启动系统,因此PCIe的限制就不存在了,这对GPGPU是一种优势。另外,FPGA是现在用的比较多的一种方法,美国自然科学基金会最近的一个报告说对于深度学习,FPGA比GPGPU还更有效。还有一种是ASIP(ApplicationSpecific Instruction Processor),比如说NPU(Neural Processing Unit),现在很多神经网络的应用希望有专门的神经网络的芯片来做。
第三,大数据跟高性能计算的典型区别是在于,大数据是一个数据密集型的,数据是存在内存里面的。所以一个很重要的架构上的变化就是让内存跟处理器能够更加靠近。比如说利用eDRAM,使得处理器跟内存之间有更大的缓存。或者把内存和处理器堆叠起来,获得更大的带宽。或者把处理器反过来放到内存里面去,叫Computingin Memory。
在存储互联的架构选择上,第一个是大内存的服务器,现在已经是主流。现在大家去做大数据,你买的服务器如果是小于一百GB的内存,基本上是不能用。甚至现在微软的Azure云里面,他提供的虚拟机,不是物理机,最高能够带400多个GB的内存。当然内存计算需要解决容错的问题,比如Spark的lineage,还有传统的checkpoint,多数据冗余,基于日志的容错机制等。

对于存储而言,SSD到PCIe SSD到闪存存储,这一路的发展需要重构系统的软件栈。尤其是对于全闪存存储,文件系统可能不需要了,我可能直接让应用操作在闪存里面的数据。如果不是全闪存的存储,要有智能数据的迁移,哪些数据放到闪存里面,哪些数据放到硬盘。NVRAM是未来,因为数据不会丢失,所以像checkpointing这样的技术就不需要了。另外,数据静态保存和动态使用的状态统一了,所以不需要文件,不需要序列化和反序列化,整个系统栈会更浅更简单。
在互联上,节点和节点之间的互联已经到40Gbps,未来100Gbps甚至更高,现在最新的技术叫Silicon photonics(硅光),可以轻松上到几百个Gbps,基于硅光也好,高速以太网也好,为了发挥内存计算的效用,需要更便宜、更高扩展性的RDMA。

在选择了硬件架构之后,软件跟硬件架构需要做协同的优化。协同优化反映在几个方面:
第一,针对硬件的特点,对软件栈进行优化,这里又有不同的做法。
首先,我们要把硬件暴露给软件栈。大家现在玩Hadoop、Spark的话,都知道它们是跑在JVM上面的,你没有办法针对硬件的架构特征做优化。那你就需要通过一种方式来打破这个界限。比如英特尔尝试的NativeTask,把MapReduce里面排序的那部分通过Java Native Interface转到原生代码里做,针对系统缓存架构做优化,MapReduce的总体系统提升了30-50%。Spark最近创了Terasort的世界纪录,其中网络通讯这块也通过Java Native Interface转到原生的netty来做。还有,现在很多基于JAVA的大数据计算库,它都能够利用底层非常优化的线性代数原生库。
其次,重新设计软件栈,像刚才说过的全闪存存储和NVRAM。甚至硬盘现在也IP化、对象存储化,传统的软件栈需要重新设计。
再者,一体机。我现在卖东西不是只卖给你服务器,或者只卖给你软件,而把软件、硬件打包成一体机来卖。现在最有名的一体机就是HAP的HANA,这个一体机单英特尔就有十几个工程师帮助他进行优化,比如它的B+树是针对高速缓存优化的,它能用SSE对数据进行流式的、在线的压缩和解压缩。
还有一个场景是云化,Hadoop在云化,Spark也有了Databricks Cloud,但一旦云化了以后会带来很多的问题,比如Hadoop、HDFS他对于数据的本地性要求非常高,你一旦虚拟化了以后,数据在虚拟机中迁移,性能影响很大。所以VMWare贡献了HVE,Hadoop Virtual Extensions。云化另外要解决的问题是资源管理,YARN是第一步,但还有很多的研究问题没有解决。另外,把Hadoop和Spark置于Docker中运行是目前的一个热点。
所有这些都能够帮助大数据的软件站针对硬件来优化。
协同设计第二个大的方向是硬件可重构,尤其是英特尔现在推出的Rack Scale Architecture,你能够对一个机架进行重构,重构的基础是资源的池化和disaggregation。我可能是一个抽屉的全部是计算模块,一个抽屉全部是存储模块,一个抽屉是网络,一个抽屉是内存。我把资源池化。通过非常高速的硅光进行互联,可以把这些资源池重新进行划分,把它配置成针对不同应用需求的虚拟的服务器。这是一个非常重要的发展方向。在机架之上,是针对多数据中心的软件定义基础设施。
软硬件架构协同优化的典型体现是大学习系统。它是机器学习算法与底层系统更好的配合。我这里列出了比较有名的学习系统,VW,GraphLab,DistBelief,Project Adam,Petuum。其中VW和ProjectAdam跟微软研究院相关(VW最早在雅虎研究院开始),GraphLab和Petuum是源自英特尔支持的CMU云计算科研中心,DistBelief是谷歌的,他们的特点都是把机器学习的算法和底层架构做更好的协同优化。除了DistBelief,其他都有开源。

第五,多快好省。就是处理数据量多,更快,质量好,成本还省。


实现多快好省的方式,第一个是软硬件的协同设计,刚才说了。
下面说一下内存计算,它不是在技术栈的某一层的技术,在硬件平台层,要大内存,全闪存,用最新的NVRAM、用RDMA。
在数据管理和存储层,要有内存数据库,更好的内存缓存,要有堆外的内存,内存文件系统。
在计算处理层,要用新的内存计算的平台如Spark,或者在传统的数据库上面再堆一层内存计算的新层次,如In memory datagrids。
在数据分析和可视化层,你要重新设计数据结构。
这里面举了几个例子,分析,现在大数据的问题中有很大一部分是图问题,或者是复杂网络问题,这里面选了两个:GraphLab,一个是GraphChi,GraphChi把数据的结构进行了改变,使它能够流处理,最后在一台机器上能够达到十台、几十台集群能够达到的性能。这就是重新设计数据结构带来的好处。这个数据结构是不是能够支持可改性,也是很重要的。现在新的趋势就是在线的机器学习,就是你一边训练,一边做识别。这个过程中涉及到核心模型数据结构的可改变性,GraphChi就能够支持图结构的修改。另一个场景是可视化,Nanocube在16GB内存上能够对TB级的数据进行实时的处理,他采用了一种新的数据结构叫做in—memory data cube。所谓的原位(in-situ)分析和可视化,就是在内存原地进行分析和可视化,而无需做数据的转化和移动。

另外一种实现多快好省的方式就是降低空间和时间的复杂度。
降低空间复杂度就是把大数据变小。变小的方式有很多,比如说压缩(尤其是列式存储),又如缓存和多温度存储,把最重要的大数据找出来放在内存和闪存里面。又比如说采用稀疏的结构。亚马逊在做商品推荐的时候,用户以及他购买的商品矩阵是稀疏的,你通过稀疏的结构能够把空间复杂度下降。把大数据变小太重要了,最近Spark采取了一种Shuffle机制的改变,从基于hash的变成了基于sort的,极大地降低了内存使用,无论是terasort的世界纪录也好,还是在实际的应用场景,如大规模的广告分析logistics regression,都非常有用。
另外一种是时间复杂度降低。比如,使用简单的模型。在机器学习发展中有一度大家觉得复杂的模型更好。随着大数据时代的来临,研究发现用简单的模型就可以了,只要你数据量足够多。这里面有一篇典型的文章,谷歌PeterNorvig他们写的,大概意思是:数据有一种不可名状的魔力,使得一个非常简单的模型(用web文本处理为例是n-gram),大量的数据喂进去以后,针对机器翻译就有了一个很大的质的提升。而这种简单的模型往往它的计算复杂度是比较低的。

第二种是通过简单模型的组合。模型组合(ensemble)是一个机器学习的专业领域。我不想说的特别专业,我只给大家举一个例子,Netflix曾经举办过一个竞赛,你只要把我推荐有效性提升10%,我给你一百万美金。很多团队参加这个竞赛,但是每个团队都没有达到10%,后来团队与团队之间进行组合,最后达到了10%,拿到了一百万美金。IBMWatson事实上是一百多种模型的组合。如果每种模型是O(N2),它们的组合一定比一个O(N3)的复杂模型更快。
还有一种是采样和近似,采样是传统统计方法,但在大数据里面也有用武之地,比如BlinkDB,只要能够容忍百分之几的误差,它在TB级数据上能够实现秒级的延迟。近似也是类似,我用更简单的数据结构来做一些精确度要求不是那么高的判断。比如说在互联网中经常有一个计算叫UV。如果你用近似算法,复杂度一下子就能够下来了。
还有一个是降维和混合建模。数据在高维空间中、但数据点很稀疏,这也催生了一些降低复杂性的方法。比如混合建模,把适用于小数据规模的带参数模型与大数据规模的无参模型结合起来,先用后者在不同的低维空间建模,再由前者把这些模型综合起来,这种方法能够有效地解决稀疏性和计算量的问题。还有一种方法是针对高维数据进行降维,然后再对其施以更快的通用算法。所有这些方法能降低降低学习的复杂性。
关于多快好省我最后要讲的就是分布式和并行化。
典型的分布式优化是ACID到BASE的变化。ACID是传统的数据库里面要获得事务特性必须得做的。但是这个成本非常高。大家就改成了BASE,他只要最终是一致的。这也是蛮有意思的。ACID在英文里面是酸的意思,BASE英文里面是碱的意思,后者实现了并行的可能。
对于迭代计算,有两种方法,Jacobi方法和Gauss-Seidel方法。对于Gauss-Seidel方法,当前迭代可以使用最新的数据,因此收敛一般会快,但需要异步通信,实现复杂。对于Jacobi方法,当前迭代一定是基于上一个迭代的数据,问题是,一旦分布式了以后,上一个迭代的数据是分布在很多不同的节点上。如果说你要完全的获得新的数据的话,你就需要等待所有的节点算完,把这些新的数据拿过来。这是不利于分布式的优化的。因为很多机器学习算法能够容忍模糊性,他能够基于当前节点上过时的数据(而不是要等其他节点最新的数据)进行计算,打破迭代之间数据的依赖。这样使很多节点并行计算,最终他还是能够收敛。这里,谷歌采用了参数服务器的方式,CMU既有参数服务器,也有更通用的SSP,Stale Synchronous Parallel。
机器学习都会碰到几种并行,首先是数据并行,更复杂的是图并行,或者是模型的并行。模型的并行需要基于模型或图的机构做相应的数据划分、任务调度,原来比较火的是GraphLab,最近比较火的是Petuum,都是源自CMU。
总体来说,并行化和分布式的重点就是减少通讯,大家做系统,一定会碰到这些问题,一旦把一个系统分布式化,你要解决缓存的问题、一致性的问题、本地性的问题,划分的问题、调度的问题,同步的问题,同步有BSP的全同步,GraphLab的异步,或SSP的半同步。在状态更新时,可以批量进行更新,或者个别进行更新的问题。通讯是可以传输全部数据,也可以只传输改变的数据。有一个教授叫IonStoica,他有一篇论文,关于Bit Torrent,也就是现在大家下载电影常用的一个协议,他就是传输变量,在Spark中得到使用。

第六,天下三分。


在最早的时候,人们都希望能够用一套架构把所有的问题处理。后面Michael Stonebraker提出我针对不同的计算需求提供不同的引擎,效果更好。所以,出现了数据和计算的分野。
现在主流的数据类型有几种:第一,表,或者是KV。第二种是数组或者是矩阵。第三种是图。他们可以用不同的计算范式处理。表格最适合的是关系的函数。数组和矩阵是以线性代数为代表的复杂的分析。图是需要图计算。
同样,我对计算范式也做了分类。
首先把大的计算范式分成了计算图和图计算。对于计算图,图上每一个节点是一个计算。先完成这个计算,再通过不同的边到下一个阶段的计算。它只有数据依赖,没有计算依赖。而图计算,图上的每一个节点是数据,边代表他们之间计算的依赖。
在计算图里面又分成两类,一类叫做批量的计算,他的典型特征是数据量太大了,数据不动,计算扔过来算。另一类是流式计算,是计算不动,数据恒动,计算分到每一个节点上,源源不断的数据流经这些节点,进行计算。
批量计算里面又分几类,一类是MapReduce,二阶段,BSP(比如Pregel)是三阶段,还有DAG(有向无环图)和多迭代计算,比如Spark、Tez。
流式计算里面也有不同类型,比如一次处理一个记录(record-at-a-time)还是mini-batch,Storm是前者,SparkStreaming是后者。不同的流式计算在容错上有不同实现,尤其是时钟语义和投递保证上。关于投递保证,假设我是一封信的话,最高的保证是一定能够到达接受者有且只有一次,而较低的保证是至少到达一次。另外,流式计算可以是做简单计算,比如基于时间窗的统计,或更复杂的流式在线学习。

编程模型这一块,有数据并行,有流式计算的任务并行,还有图并行。现在往往要求图结构支持关系操作,比如跟一张表来join,这是现在很多图计算编程模型新加入的。还有,最新出来一种概率编程模型,针对概率图的机器学习是更好的编程模型。
在大数据领域最近也在推事件驱动编程模型。一个非常火的范式叫reactive范式。最早在Erlang里,叫Actor模式,现在在Scala Akka语言里面,有更好的实现,他在针对异步的处理逻辑的时候,有更好的可扩展性。

第七,融合。既然分了,就有合。

融合一直在发生。Big Dawg是英特尔在MIT最近支持的研究工作。他提出了普适的编程模型,一种叫做BQL的语言,他支持关系和线性代数、复杂数据模型、迭代计算、并行计算。
Twitter Summingbird是在编程接口层面融合,同时支持批量(MapReduce, Spark)和流式(Storm)的。
Lambda架构则是在应用框架层面的融合,把实时和批量结合起来,两者之间加入增量计算,同时批量那边加入缓存。
Spark则是在实现框架层面的融合。
最后微软的REEF则是通过资源管理层,如YARN,来实现多计算模型的融合。


我拿Spark做为一个案例,它的BDAS软件栈底层是HDFS加上Tachyon内存文件系统,接着是Spark内存计算框架加上Velox的模型管理。在上面支持各种不同的计算范式,如Spark Streaming的流计算,SparkSQL的交互查询,GraphX的图计算,MLlib的机器学习等。由于SparkSQL的核心数据结构SchemaRDD起到基础性的作用,其他几个计算范式可能会建筑在SparkSQL之上。
有了这个BDAS以后,大家可以想像处理不同场景,比如说流查询,我把Spark Stremaing的流式和SparkSQL代表的数据仓库整合在一起;实时加上批量,SparkStreaming是实时,Spark本身是批量,实时加上历史数据分析获得全时洞察;Spark Streaming的流处理加上MLlib的机器学习,实现在线学习。又比如说图流水线,传统上先要对图数据进行处理,进行ETL,中间进行图计算,最后后处理。传统的图计算引起只能做中间这部分,前后还得靠MapReduce去做。而在Spark之上,可以一条流水线做完。最后,SparkSQL和MLlib可以有机结合,把交互分析和机器学习揉在一起。

在其他方面,融合也在发生:
比如数据管理和数据分析的融合,在传统的数据库中,有两类处理:一类叫做OLTP,做数据管理,一类叫做OLAP,做数据分析。两者基于不同的数据格式,之间需要ETL。现在的趋势是两者融合,在一套数据上计算。
MPP和Hadoop各有优势,现在也在融合。
就连高性能计算或超算也在跟大数据融合,前者原来是计算密集的,以模拟为核心的,现在也有很多数据密集的应用,重心也从模拟转移到数据分析,出现了high performance data analysis和data intensivesupercomputing等新的子领域。
本次讲座是清华大数据产业联合会"技术•前沿"系列讲座的第一讲,主讲人为英特尔(中国)研究院院长吴甘沙。
