华大医学执行总裁尹烨:基因大数据分享
来源:华大基因
全世界已经测序完成的高等动植物基因组大概有800个,华大贡献了70%。
主讲嘉宾:尹烨:华大医学执行总裁。1979年生,籍贯山东烟台。2002年毕业于大连理工大学生物工程专业获学士学位, 2013年获华南理工大学生物工程(基因组学)工程硕士学位。2002年加入华大基因,先后从事体外诊断试剂研发、管理及基因组研究行业,曾任华大科技总裁,华大集团首席运营官(COO),现任华大医学总裁,率领团队积极推动前沿生物医学技术和基因组学研究成果的临床应用,降低出生缺陷及其他重大疾病对人类健康的危害。
各位好,华大基因的尹烨。基因这个词一直是我非常喜欢的词,也是英文翻译的最好的词,gene-基因,基因基因,基本之因。
第一个话题,基因,基因组,大数据。对于目前我们已知的生物圈,碳链作为基本骨架的生命,我们都是通过DNA来进行遗传的。基因可以简单的理解成一段有意义的DNA序列,而全部的DNA就成为一个物种的基因组。
地球诞生了46亿年,最早的细胞化石是30亿年,我们从简单到复杂,从水生到陆生,从低等到高等,从无性到有性,从单细胞到多细胞……
我只能说部分同意进化论,但是关于生命的起源,的确是一个争议很大的学科。
但分析现有的物种(包括部分灭绝的),从DNA的角度来看,的确有着极强的进化或演化关系,我们称之为同源性。
最简单的基因组来自于病毒,比如乙型肝炎病毒的DNA总量(基因组大小)只有3.2Kb.然后到了细菌,比如大肠杆菌,基因组就有4Mb,而到了酵母,也就是真菌就有了10Mb。他们的基因组不断的插入外源DNA,越来越大,功能也越来越多。然后高等真菌已经有30Mb-80Mb 的基因组了,到了最简单的植物也只有100Mb左右的基因组,比如拟南芥。再向上,比如梅花200Mb,水稻400Mb,大豆1Gb,两爬类2Gb,哺乳类3Gb。所以人类的基因组也就是3Gb,即30亿个碱基。
然而还有更大的,比如辣椒在3G以上,而大麦要5G-6G,大蒜10G,小麦16G,银杏20G……肺鱼50G-100G。
基因组的大小与物种进化高低并无一致性,我们称为C值悖论,或者说很多物种仍然是处于进化状态的。全世界(范围内),我们基本的预估,所有生命信息只测一次的数据量是 10的60次方,然而现在只有10的21次方-22次方左右。以人类举例,这个群体有70亿数量,如果每人都测一次,则测序的数据量至少就是3Gb*70亿这么大。且受到技术和方法学限制,目前每一个人至少要测100G(大约是基因组的30倍),才能得到相对准确的全基因组信息,所以刚才的数量就达到了100G*70亿人次这么大。
水稻,玉米,小麦……这些都要育种,每一个也都需要按照这样的方式来做,所以这个数据量就变得无可估量了。现在是从每个物种只测一次的角度来讲,而对于活着的生命体,还需要测很多次,比如每个人睡觉、吃饭、思考、生病的基因表达都不一样,这个数据量还会有数量级的增加。
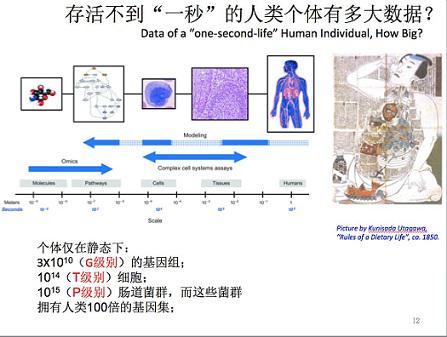
存活不到“一秒”的人类个体有多大数据?这里说的一秒是指把生命出现到现在当作一年时间来看。
所以你会发现,原来我们还有基因组万倍的细胞,还有十万倍的菌群。这些如果都测出来,那是不得了的数据量。
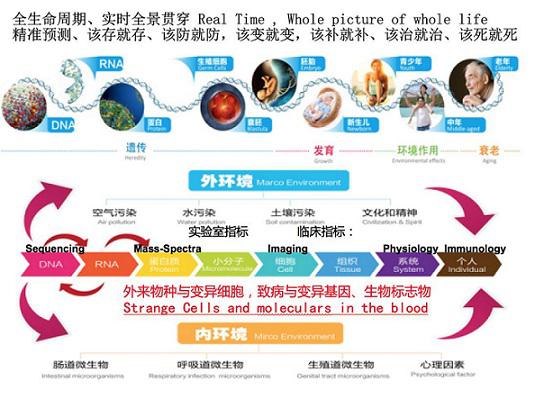
我们计算过,一个人如果从出生下来就开始取样,生化、免疫、影像、基因,表型数据,如果都开始积累,那么一起步就是665个G,一辈子差不多就到了1个P。如果一个人1P,1000人就是1E,1M(Million)人就是1Y,1B(Billion)人就是1个Z,这就是10的24次方。这个数据还只是人类,如果把上千万个物种,都这样来一下,那么可能就达到了N或者D的级别。

大家看这个,如果说20世纪是物理学世纪的话,那么21世纪毫无疑问的就是生命的世纪。物理在有了热力学三大定律特别是熵的概念提出后,开始进入快速发展阶段。生命科学至今还没有一个可以用数学语言可以阐述的定律。
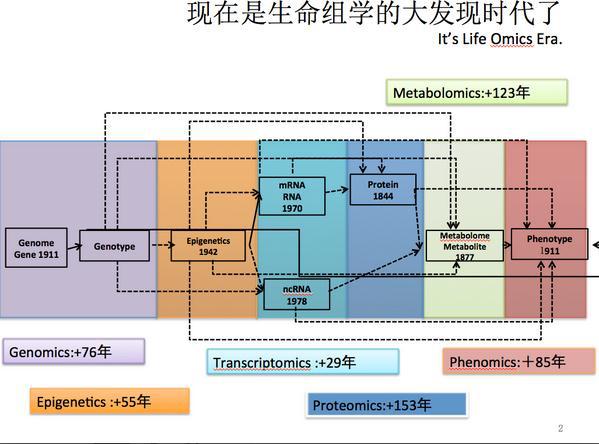
看下这张,生命科学从1859年物种起源来看,不过就是150年的时间。基因也是1911年才出现的提法。迄今为止,全世界已经测序完成的高等动植物基因组大概有800个,华大贡献了70%。
基因数据这对于这个行业来讲就是巨大的油田。
一个行业如果要兴起,需要经过科学发现,技术发明,再到产业发展。比如富兰克林发现了电,爱迪生发明了电灯,而GE把照明做到了全世界。制造业包括IT,一般可以直接从发明到发展,所有学科里面唯独生命不行。这是因为,生命科学直接作用于人体,即使你知道了青蒿素可以治疗疟疾,但一定要从机理上证明,即回归发现,才可以允许你做产业发展。而生命的科学发现,必须依赖于大数据,重视相关关系,而不是因果关系。
美国在1980年启动了肿瘤大战,希望通过蛋白等片段的信息来搞清楚肿瘤,十年后发现失败。所以在1990年正式启动了人类基因组,不去搞明白为什么,而是先把whole picture搞定,即解决是什么的问题。
这就是基因组的起源和生命科学的大发展。一次核磁从几十个G到几百个G都有,看分辨率。
下面进入今天最后一个问题,生物大数据到底能做什么。先说育种。相当程度上,我们现在可以不通过种地,而直接通过运算的方式来进行虚拟育种。
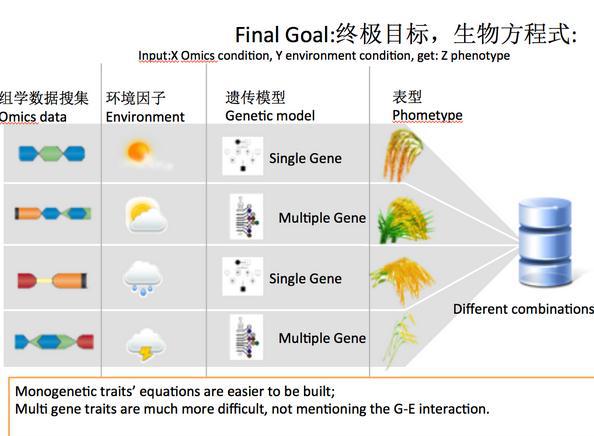

大家可以对比一下。
按目前的算法推测,如果做到相关性90%,对于玉米(基因组大小是2.5Gb),10000株玉米就可能让天河一号全年计算能力饱和。目前最快的测序仪,每一秒的数据产出会达到几十个G,除了用裸光纤,根本没法解决传输问题。如果个人基因组得到普及,以100万人的数据库如果要进行两两比较,那么天河二号也远远不够。这就是生命大数据带来的计算,存储,传输的挑战,瓶颈在IT。再来讲生命科学的应用,比如肿瘤,大家应该知道,肿瘤本身不是均质的,即不是简单的区分为癌症组织和癌旁组织,肿瘤的生长过程本身就是一个动态的进化过程,说的通俗点,最早的肿瘤细胞逃脱了细胞周期,战胜了普通细胞,然后抢到了离血管近的位置,开始快速繁殖,逐渐地,远离血管的就打不过离血管近的了,所以要进一步进化成更“厉害”的癌细胞。所以,所以肿瘤靶向药物,如果是直接针对的匀浆状态的,那很可能是无效的。我们发过几篇高水平文章都是关于单细胞测序的--即我们挑选肿瘤组织中的上百个细胞,一个一个测基因组,然后看他们基因组的进化关系,从而正确判断出这些癌细胞的出场顺序,知道了正在起作用的基因。这个时候的有的放矢就变得很重要了。
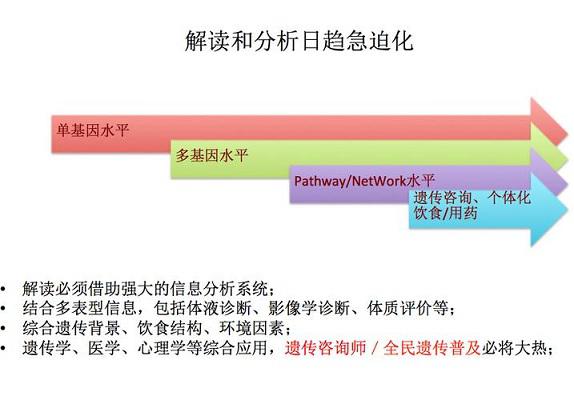
在生命科学里,很多是数十个甚至数千个客观规律在同时作用,所以因果关系本身说不清。
比如血糖和糖尿病真的有必然关系么?在科学上,我们这个领域用相关关系的很多,比如GWAS,全基因组关联分析就是最典型的例子。但是只看静态是不对的。正如看见影片中一个人手里拿着刀,是无法判断他是否杀人的。
我们不能凭借image来说事,而要靠video.所以未来的健康领域,一定是综合了基因,环境,运动,营养,菌群,睡眠,心理共同作用的结果。在这个基础上,会产生全新的行业,即所谓的真正意义上的健康咨询师,目前的遗传咨询也只能解决20%或者更少的问题。比如精子,每次射精有50亿个左右,但任意两个精子的DNA都不一样,这就是进化或演化的根本。
最后一个例子说说菌群,每一个人100斤的人有4斤的细菌。
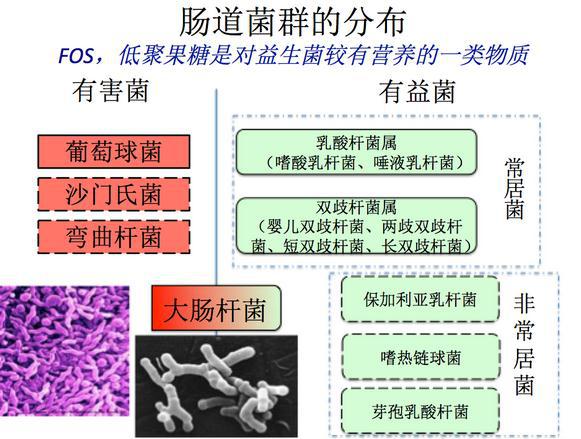
通常认为的菌群是我截图这张,但实际上肿瘤有上千种,但丰度谱是不同的,所以依次可以区分肠道菌群分型,我们称之为“肠型”。这些菌很大程度上决定了你的吸收,可以简单的理解为,它们的次生代谢产物才是我们吸收的营养。我们曾经测过欧洲亚洲不同食谱的人群菌群,在健康的时候是不一致的,但比如罹患了大肠癌,则菌群的多样性下降,到晚期趋同性更有一致的趋势。所以现在通过测粪便就可以分别相当多的疾病状态,包括大肠癌,包括糖尿病,甚至抑郁和很多精神性疾病,都和菌群释放的内毒素有关。
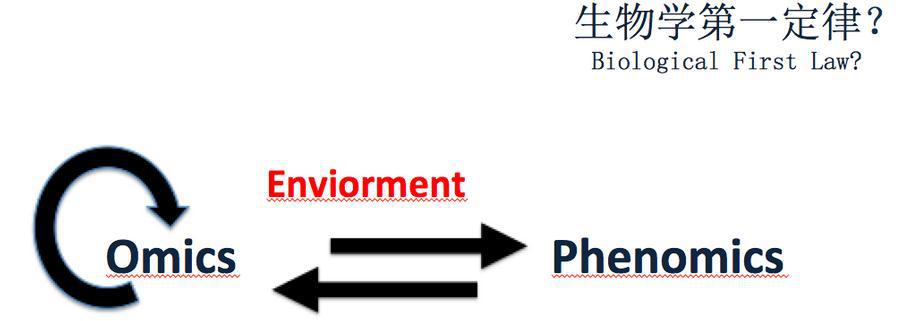
这是华大CEO王俊提出的第一定律。表型组和基因组通过某种环境条件起作用。我们希望能够发现部分数学定律来阐述。

最后一张片子,生命周期表,里面给出了从174噬菌体开始发表的所有顶尖的物种文章。我们希望能够找到生命周期表。
