实验数据处理中的相关和回归分析(3.16修订过)
实验数据处理中的相关和回归分析
(感谢我的助手小陆把三张图片加入文章,便于读者理解文章内容)
三十年前,我就注意到生物学和农业科技界的期刊论文在数据处理和统计方法上经常犯一些共性错误,主要是误用统计术语,滥用公式和概念,或者对统计结果做出错误解释。我搜集了一些文献、资料和案例,写成草稿,但一直没有整理和发表,后来出国就一直搁下了。现在工作忙,更没时间考虑这些“小”事,但厘清统计学概念很重要,针对性强,一直记在我心里。
在国家玉米产业体系2013年的总结汇报中,个别专家讲得天花乱坠,但我要尽可能察看那些数据分析的结果,还要看他如何对结果作出解释。最常见的失误发生在相关分析和回归分析以及对分析结果的解释。如果数据处理错误或解释不当,得出的结论就可能是错误的,但更多的情况是文章写得很肤浅。一些人只会套用统计公式却不懂原理,不知道如何解释结果。尽管有电脑代替人脑进行复杂运算,却仍然出错,错在滥用或误用统计学术语。随着电脑软件的普及,滥用统计学术语和对统计结果作出错误解释的现象将会增加。
中国农科院的李少昆在汇报中强调玉米籽粒含水量与机械收获破损率之间的相关或回归的显著性,而不理会相关程度。按照经验,玉米籽粒含水率高,机械收获时破损率也会高,但如果调查分析后相关性很低,甚至基本无相关,不管显著性程度如何,这个调查结果都值得怀疑。思维逻辑的混乱和本末倒置是中国农业科技期刊论文中常见的错误类型。相关分析首先要关注相关程度,而不是显著程度。前者反映了事物之间的本质关系,后者反映了试验误差或数据的可靠程度。
分析试验结果,经常要考察两个因素之间的相关性,而不能用显著性代替相关程度。回归分析也一样道理。两个因素之间的相关程度取决于因素之间的本质关系,而显著性反映试验设计、执行和数据采集的可靠性,这其中隐藏着看不见的误差。
如果对数据进行检验证明差异不显著,但两个因素之间相关程度很高,我们可以通过控制试验条件和改进技术来提高数据的可靠性,然后重新试验和统计、分析。但如果大量数据证明两因素之间没有本质关系,改进试验设计和田间技术都很难改变数据的分布状态,后续讨论将不能令人信服。
两个因素之间的相关性可分为高度相关、中度相关、低度相关和零相关。李少昆报告中列举的大多数回归分析结果表明是低度相关或零相关。我们评价一个试验结果,首先考察因素之间的真实关系,然后考察试验过程和数据的可靠性。从个别人的试验结果来看,需要检查试验设计到底错在哪里。我估计李少昆在调查数据的时候没有统一标准和控制条件,有隐含的其他因素扩大了误差,却没有被研究者发觉。而他在对结果做解释的时候把不相干的两个因素硬扯在一起,这就属于滥用统计学概念和术语。
李少昆出示了近20幅回归分析图,除一个决定系数0.7,其余的都在0.3以下(弱相关),绝大多数在0.2以下,甚至有一批在0.1以下(零相关)。如果两个因素之间确实有内在关系,这样的统计结果表明在调查过程中可能忽略了重要的影响因素,也可能设计错误,调查时考虑不周(例如2012年玉米产量挖潜的密度试验就属于试验布置有缺陷)、数据采集不准确(2013年的调查可能就错在这里),至于数据分布和模型拟合不当则属于掌握公式和基本原理出现错误。由于他没有出示方差分析参数,所以无法做出更深入判断。如果ANOVA不显著,后面的一切分析和讨论都没有意义。仅从幻灯片给出的简单数据来看,误差过大,方差分析不可能显著。于是决定系数很低,对统计结果不要做后续发挥。
当我们遇到分析结果误差较大时,如果方差分析的F(或t)检验不显著,没必要作相关和回归分析。若方差分析显著,应倒回去检查,如果模型拟合不好,决定系数低,首先考察数据的群体频率分布,然后考察模型。有些数据属于非正态分布,就不适合做简单的线性回归分析。如果模型拟合没有不妥,就要考虑是否数据采集误差太大,无意中引入了第三者、第四者因素,使误差平方和远远大于处理之间的差异平方和。如果试验者没有注意到,这就很麻烦,需要下一年度重新做试验。如果试验数据采集也是严格统一和没有大毛病的,就要考虑试验的布置,最后就是试验设计失误。遇到相关分析或回归分析结果不好的时候,可按这个顺序去检查问题可能出在哪里。
李少昆很可能是忽略了其他因素。这需要其他专家帮助纠正,例如农机专家、育种专家、植保专家或种子专家等。至少有一点被忽略了,即使同一个品种在不同地点甚至不同地块所表现的生育期和含水量以及可能的其他未知因素(例如降雨量、降雨时期,施肥量和施肥时期等),都影响数据的整齐性和回归分析结果。更何况生育期、苞叶、穗轴粗细……不同品种的数据混杂在一起胡乱分析,误差会更大,而且不能控制。(是否需要作非线性回归,则要根据数据性质和科学事实去考虑。如果数据混乱,非线性回归也做不得。)
同样是在国家玉米产业体系,陈捷、陈绍江和肖俊夫专家的数据处理就挑不出毛病,在他们的报告中,大多数回归(线性和非线性)分析的决定系数均高达0.95以上,甚至0.98上下。这说明他们的试验设计和数据采集可靠,模型拟合准确,理论上没有明显可见的毛病,他们抽象出来的结论令人信服,这与0.2,甚至0.05上下的决定系数是不可同日而语的。从幻灯片来看,李少昆的数据质量不适合做回归分析,硬要分析就属于荒谬。若信誓旦旦地下结论,就是瞎忽悠。当然,这需要考察数据的频率分布和ANOVA参数才能找到原因。但有的原因可能找不到。
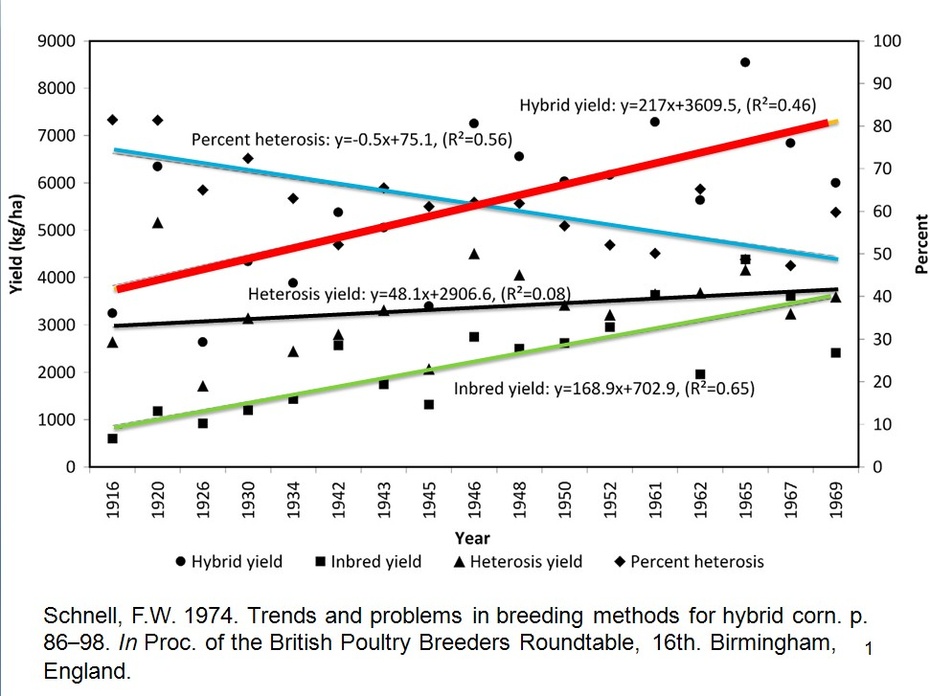
我给大家出示了关于玉米和棉花品种产量持续上升,杂种优势却持续下降的三张幻灯片。第一张是Schnell, F.W. 1974. Trends and problems in breeding methods for hybrid corn. p. 86?98. In Proc. of the British Poultry Breeders Roundtable, 16th. Birmingham, England. 绝对杂种优势对年代回归的决定系数0.08,说明杂种优势与年代之间几乎没有关系。换句话说,几十年来,玉米杂交种的绝对杂种优势没有实质性提高。但相对杂种优势的决定系数0.56,杂交种产量回归的决定系数0.46,说明有中度相关和中度可靠性。但自交系产量回归的决定系数较高(R2=0.64),说明两个因素之件有较高的相关性和中等决定系数。这个试验的误差较大,但远远好于李少昆的数据。
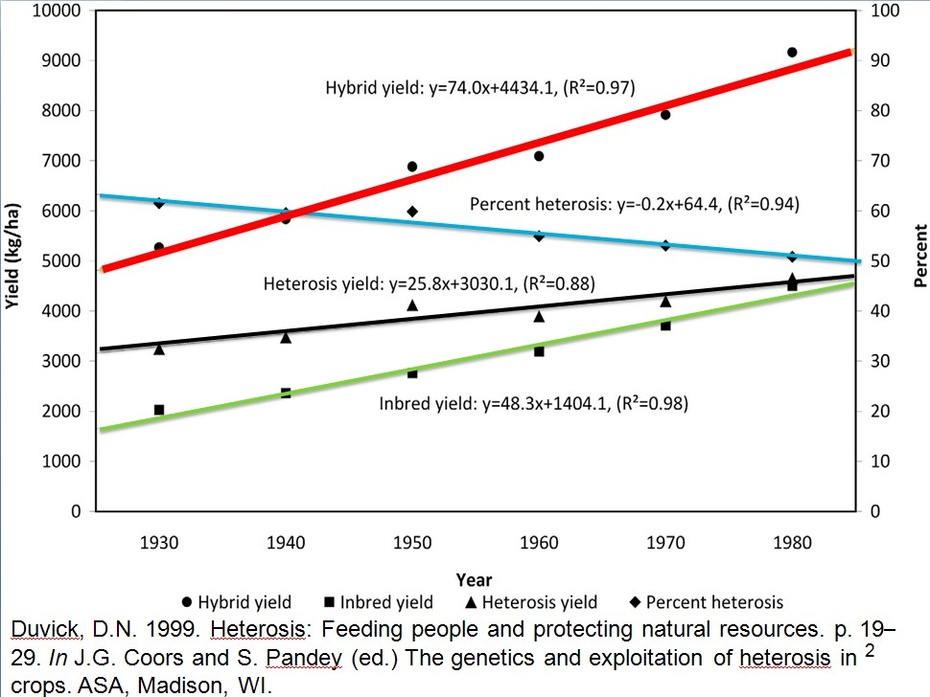
第二张图是先锋公司的数据:Duvick, D.N. 1999. Heterosis: Feeding people and protecting natural resources. p. 19?29. In J.G. Coors and S. Pandey (ed.) The genetics and exploitation of heterosis in crops. ASA, Madison, WI. 杂交种产量和自交系产量对年代回归的决定系数分别是0.97和0.98,不但品种产量对年代的相关系数极高,回归分析可靠,试验误差也很小。相对杂种优势对年代回归的决定系数(0.94)高于绝对杂种优势(0.88)。这是近乎完美的试验结果。
第三张图是棉花的试验数据,也非常可靠。Campbell, B.T., D.T. Bowman, and D.B. Weaver. 2008. Heterotic eff ects in topcrosses of modern and obsolete cotton cultivars. Crop Sci. 48:593?605. 杂交种产量和亲本产量对年代回归分析的决定系数分别是0.75和0.86,而相对杂种优势的决定系数(0.77)也是高于绝对杂种优势(0.66)。棉花这个试验做得不容易,材料不丰富,结果却相当好。

这三个文献虽然作物不同、试验的时间地点不同,但揭示了一个共同现象,相对杂种优势的决定系数高于绝对杂种优势。自交系产量对年代回归分析的决定系数高于杂交种产量。我们不再往深了分析它们的生物学意义和育种学价值,只想说明这三个没有关联的文献揭示了共同规律。这说明,尽管试验的准确性不一样,但是把它们放在一起比较,却揭示了共同趋势。因此,这些试验结果是可信的。
比较而言,李少昆的试验设计和数据来源有问题,属于滥用统计学方法和术语。即用了不该用的统计学方法,或者做了错误解释。年轻人这么做可能是理论疏忽,但也可能是故弄玄虚或忽悠人。尽管每张幻灯片几秒钟就闪过,但仍然有懂行的人盯着看数据的可靠性。
现在,进入分子生物学和电脑操作层面,若忽视基础理论教学,论文中发生统计学疏忽就会更多一些。以前,许多论文有毛病,当时畜牧学科的统计学功底明显好于其他学科。农学方面好于园艺科学。这与我国农业教育受前苏联影响和知识结构的缺陷有关。所以,农业科技论文表现出的统计功底普遍较差。一直到现在也没有根本改变这种状况。(当然,在西方国家,园艺学领域的问题也比农学和畜牧领域的问题更多一些。)
随着国际交往的深入,越来越多的青年科技人员,特别是一些博士硕士研究生的统计学功底明显超过了前几代科技人员。希望最终能体现在高等教育学科结构的改革方面,消除急功近利,加强基础学科的教学。
有一些概念错误,属于几十年前翻译错误,一直沿用至今,它深刻地影响人的思维方式。绕过这类因翻译不准确而导致的思维方式的混乱,最好办法是直接阅读欧美国家的统计学教科书,而不要阅读中文教科书。
国内农业期刊论文中,对试验数据衍生的信息挖掘不深的现象比较多,当时和现在都顾不上讨论这些。先把滥用和误用澄清了才可能讨论信息挖掘肤浅的现象。这可能需要很长时间。
这是什么意思呢?如果把数据重新处理,能够挖掘出更多更深刻的信息。即重新处理数据,并作出合理解释和挖掘深层次信息,能够写出更好的论文。现在,中国是世界SCI论文第三大国,但科技人员的国际地位并不高,原因是许多论文只给出了试验数据和结果,属于知识积累,却抽象不出规律性的科学知识。这样的论文给人虎头蛇尾的感觉。这是青年科技人员今后要注意的。
今后避免犯类似错误或其他各种类型的滥用与误用,最好办法是在实验设计、数据采集、数据分析和撰写论文的过程中,咨询统计学专家或数量遗传学专家。CIMMYT就有这样一位专家(Crossa),几乎所有的试验设计、数据处理和论文初稿都要经他指点和审阅,所以他要在很多论文中署名,这样至少不会犯低级错误。
即使中国农科院的科技人员也要谦虚谨慎,尊重和听取其他领域专家的意见,别自以为是,反而把自己边缘化,长此下去就倒牌子了。
