K8s和YARN都不够好!全面解析Facebook自研流处理服务管理平台
Facebook 在许多使用场景采用了分布式流处理,包括推荐系统、网站内容交互分析等,这些应用的大规模实时运行需要达成严格的 SLO。为此,Facebook 构建了新的流处理服务管理平台 Turbine,并在生产系统中上线运行近三年,部署在由数万台机器构成的集群中,管理着数千条流水线,每秒实时处理数以 TB 的数据。在 Facebook 的生产经验证明,Turbine 很好地平衡了群集间的工作负载波动,可预测计划之外的负载峰值,持续高效地完成大规模处理。
近十年来,大规模分布式流处理得到广泛应用,并形成了多个成熟的生产系统,各自专注于不同领域的挑战,例如故障容忍(Apache Storm)、低延迟(Apache Flink、Storm),可操作性(Twitter Heron)、直观编程模型(Millwheel)、语义处理(Dataflow、Samza、Flink)、弹性伸缩(Millwheel),有效资源管理(Twitter Heron)和状态管理(Spark Streaming)等。
Facebook 也面临着同样的需求。该公司的许多应用采用分布式流处理,包括网站内容的低延迟分析互动、搜索效果分析和推荐系统等应用场景。为了满足这些需求,Facebook 为开发人员构建了 使用类 SQL 声明式流处理开发语言和 C++/Python/PHP 命令式开发 API 的框架,并使用该框架构建了大量无状态和有状态的流处理应用。这些应用需要一个可扩展的流处理服务管理平台实现规划、配置和部署,并确保应用的停机时间和处理延迟等指标,即便在停机和负载波动的情况下也能满足严格的 SLO。FB 的很多流处理应用程序要求 90 秒的端到端延迟阈值。
现有的通用集群管理系统,例如 Aurora、Mesos、Borg、Tupperware 和 Kubernetes 等,虽然可以在一定程度上满足跨多种负载的通用管理要求,但并不适用于 Facebook 的流处理需求。其中,Borg 是由多个异构系统组成的生态,用户必须了解多种各不相同的配置语言和流程,才能配置系统并与其交互。Kubernetes 基于 Borg 的经验,改进了分布式服务部署和管理体验。YARN 资源管理器得到了 Flink、Samza、Spark Streaming 和 Streamscope 等流处理系统的采用。这些管理系统虽然大都实现了有效的资源隔离和执行框架,但是需要提前确定所需的处理资源才能高效运作,这在流处理场景中是很难做到的。此外,这些系统并不能很好地支持资源的自动缩放。
本文阐述了 Turbine 的架构设计考量及实现,内容来自论文“Turbine: Facebook’s Service Management Platform for Stream Processing”。该论文已被 2020 ICDE 会议工业系列(Industry Track)录用,第一作者 Yuan Mei 本科毕业于北京大学,在 MIT 获得博士学位,现任 Flink 架构师。
概述
Turbine 是 Facebook 的可扩展流处理服务服务管理平台,解决了现有通用集群管理框架难以适应 Facebook 流处理需求的问题。Turbine 已上线 Facebook 生产环境近三年,很好地支持了 Facebook 的众多流处理应用。
Turbine 的创新之处在于实现了快速且可扩展的任务计划调度,支持自动缩放的资源有效预测机制,并提供满足容错、原子、一致、隔离和持久性(ACIDF,atomic,consistent,isolated,durable and fault-tolerant)的更新机制。具体而言:
调度机制使用两级调度机制,实现流处理任务的配置和管理。调度器首先使用 Facebook 的通用分片管理器将分片置于指定容器中,然后使用哈希机制将流处理任务分配给分片。每个分片会定期进行负载平衡,并且 Turbine 提供了负载平衡时重新计划流处理任务的安全调度机制。为确保故障不会导致数据损坏、丢失或重复处理,Turbine 实现了容错机制。
自动缩放机制可自动调整 CPU,内存,磁盘等维度上的资源分配。为达成设定的 SLO 目标,自动缩放机制估算指定流处理作业所需的资源,然后按比例放大或缩小流处理任务的数量,以及每个任务所分配的资源。自动缩放机制还可根据这些资源缩放决策和历史工作负载,对原始资源估算情况迭代地做出调整。
提供满足 ACIDF 的应用更新机制。对于流处理服务管理,更新机制非常重要,因为服务提供者、资源自动缩放和人工操作等处理参与者可能会同时更新同一流处理作业。系统必须确保所有更新相互隔离,并满足一致性。为此,Turbine 设计了分层作业配置架构,基于作业优先级对多个参与者的更新操作进行合并。Turbine 通过计划更新与实际更新的分离,提供了支持 ACDIF 的更新机制。更新机制使用状态同步服务,实现预期和运行作业配置间的同步,并支持更新失败时做回滚和重试。
Turbine 采用松耦合的微服务设计,实现作业管理、任务管理和资源管理,架构了一种高度可扩展且具有弹性的管理平台,满足应用的 SLO 需求,支持在无人工监督情况下的海量数据流处理。
Turbine 整体架构
Turbine 的架构如图 1 所示。应用开发人员使用 API 以声明式和命令式编程方式构建数据处理流水线应用,支持下至基本的过滤和投影操作、上至具有多个连接和聚合运算的复杂图关联查询。查询在通过模式检查等合规性检查后,被编译为 Turbine 的内部表示形式,优化后发送给 Turbine 处理引擎。引擎负责生成运行时配置文件,支持以批处理和流处理两种模式执行应用。批处理模式主要适用于从数据仓库处理历史数据的应用场景,本文主要介绍流处理模式。
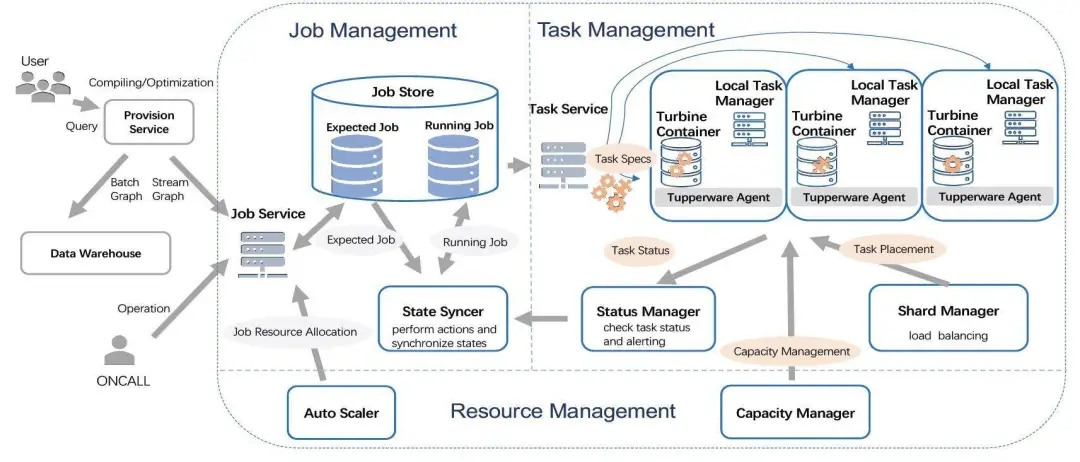
图 1 Turbine 整体架构图
Turbine 流处理系统包括作业管理、任务管理和资源管理三大主要组件。处理流水线由多个作业组成,每个作业具有多个可并行执行的任务,每个任务独立处理部分流数据。作业管理存储作业的配置,并维护作业的更新。任务管理将作业配置分解为独立任务,在集群上调度任务执行并维护负载均衡。资源管理实时分配集群、作业和任务资源。Turbine 在设计上很好地解耦了各组件间的决策关联,任何组件产生的失败均可通过处理降级模式得到解决,不会影响整体操作的继续执行。
在数据模型设计上,Turbine 作业间的通信采用 Facebook 自研的消息持久化总线 Scribe 实现。每个任务从 Scribe 读取一到多个数据独立分区,维护自身的处理状态和检查点,在处理失败时从 Scribe 分区读取数据和检查点信息以恢复任务。这种数据模型设计简化了任务依赖,使得系统在任务调度、负载均衡和资源扩展中无需考虑任务间的依赖关系。
作业管理
流处理中,每个应用都被编译并优化分解为一组独立执行的作业。作业执行所需的所有配置和信息由作业配置维护。作业在执行期间,作业配置会因为用户操作以及内部其它服务的需求而发生变更。因此,作业管理的一个重要挑战,就是如何确保配置变更符合 ACIDF 要求。符合 ACIDF 对于作业变更而言非常重要,因为在运行环境中可同时存在上万个作业,变更可能会导致作业执行失败,甚至是相互冲突。作业管理必须实现作业的自动变更、扩展和溯源。
基于此需求,Turbine 作业管理在设计上包括:实现配置管理的作业存储(Job store)、自动提交配置更改的作业服务(Job servie),以及执行作业配置更改的状态同步(state syncer)。
作业资源配置:出于对作业配置独立性和一致性的考虑,Turbine 采用了一种层次化的作业配置结构。配置管理使用 Thrift 实现编译时类型检查,并由 Thrift JSON 序列化协议将配置转换为 JSON 表示。这样的层次化配置结构设计,支持整合来自不同服务的任意数量的配置需求,并通过 JSON 文件的归并实现统一逻辑的层次化叠加。
具体而言,Turbine 对需执行的作业定义了一个期望配置,基于此在作业执行时生成一个运行配置。在期望配置中,包括了定义作业基本资源的基础配置、定义更新资源的预定配置、定义自动扩展资源的扩增配置,以及定义用户手工操作作业所需资源的待定配置。层次化资源定义实现了上述四类配置的相互隔离,为作业执行提供一致的状态视图。
作业状态同步:为实现作业更新的原子性、持久性和容错性,Turbine 实现了期望配置和运行配置的独立存储,并通过状态同步实现二者间的同步。每一轮作业执行时,状态同步按配置优先级依次归并各个层级的期望配置,并将生成配置与运行配置比较。一旦存在差异就生成新的执行计划,并提交执行。在同时运行上万个任务的大规模集群中,任务出于负载均衡的考虑会在主机间迁移,上述同步操作机制可确保作业的原子性、容错性和持久性。
为提高同步操作的性能,状态同步会对基本的同步操作执行批处理,并对复杂的同步操作做并行化处理。
任务管理
任务管理主要负责任务调度、负载均衡和故障处理。Turbine 通过集成 Facebook 自研的容器管理器 Tuppperware,实现 Linux 容器的分配和编排。每个容器运行一个自身的任务管理器,负责在当前容器中运行的流处理任务。
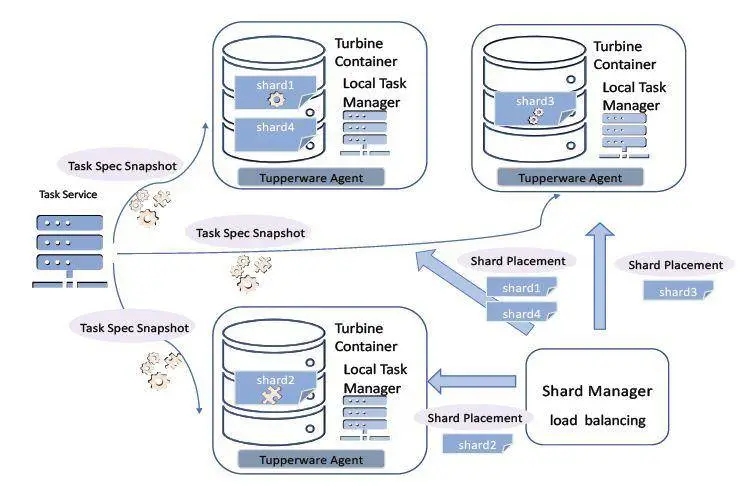
图 2 两层分布式任务调度和负载均衡
任务调度:Turbine 使用 Facebook 的分片管理器(类似于 Google Slicer),实现对容器的均衡资源分片。Turbine 设计了两层资源调度机制,如图 2 所示。资源调度将计算资源物理分配给各个容器。图中的四个分片将被指派给三个容器,每个任务管理器从任务服务(Task Service)获取任务描述的完整快照,并调度分片所指派的任务。在任务调度实现中,需考虑任务与分片的映射关系维护,以及分片的混洗和重新分配机制。
负载均衡:在任务调度完成初始的“分片 - 容器”指派后,任务管理器依据该指派启动任务。在任务运行期间,Turbine 周期性轮询分片负载情况,并根据情况由分片管理器做混洗和重新分配。具体而言,每个容器指定了内存、CPU 等资源数量,每个分片指定了可承担的负载量。分配算法根据二者匹配情况及总体资源使用情况,采用装箱类算法计算得到指派。这里的一个重要问题,是如何定义分片负载。Turbine 通过采集多种度量,综合定义多个层级的资源保障,以改进集群的整体资源使用效率。例如,对于 C/C++ 任务,系统采集固定时间窗内的平均内存使用情况;而对于使用 cgroup 管理的 JVM 任务,则采集 xmx、cgroup 限额等峰值资源需求。度量采集使用一个后台的负载聚合线程,实现对当前资源使用情况的实时估算。
故障处理:故障处理的主要目的是降低系统运行故障对任务运行的影响,确保任务失败不会对数据本身产生破坏。为此,Turbine 在分片管理器中引入了一种基于心跳的双向故障转移协议。一旦分片管理器在设定时间(默认为 60 秒)内没有接收到来自任务管理器的心跳,就认为相应的容器已经停止工作,进而为该容器中的分片重新进行指派,并启动上面介绍的分片迁移机制。需要注意的是,网络连接故障等情况也会导致心跳停止。这时如果直接迁移分片,会导致重复的分片指派,进而导致重复的数据处理。针对此类问题,Turbine 进一步设计了一种主动超时机制。一旦连接超过了设定的超时时间(通常小于心跳时间,默认为 40 秒),那么 Turbine 容器就会重启,并在重启后重新连接分片管理器,恢复故障转移前的分片状态。
综上,下列设计确保了 Turbine 实现任务高性能调度和任务的高可用性:
如图 2 所示的两层资源调度架构,实现了任务调度和资源调度的分离。
任务管理器完全掌控任务列表,这样即便在任务服务和作业管理失效的情况下,Turbine 依然可执行负载均衡和故障迁移。
定期更新的任务管理,确保任务更新情况能及时反映给任务管理。在 Facebook 大规模集群的实际运行中,状态同步延迟平均维持在 1 至 2 分钟以内。
一旦系统出现故障,可在 60 秒内完成故障迁移。任务的平均宕机时间控制在 2 分钟以内。
弹性资源管理
资源管理根据任务、作业和集群的负载情况,对资源使用做出动态调整。资源管理一方面可确保所有作业具有足够的资源以按时完成输入处理,另一方面确保有效利用整个集群中的资源。Turbine 资源管理在借鉴现有系统一些好的做法的同时,充分考虑了如何降低系统中无必要的资源消耗,例如避免重启不需要重启的任务。
最初,资源管理器采用响应式机制,即通过监测任务滞后和积压、输入不平衡、任务运行内存不足(OOM)等预设问题,并采取响应资源管理操作。这种机制虽然在流处理系统中普遍使用,但在 Fcebook 生产环境中出现了一些问题。首先,由于对作业所需资源缺乏准确预估,一些时候会导致某一作业等待特定资源而耗时过长。其次,由于缺乏对资源需求下限的判定,因此无法保证作业每次都能健康运行,进而导致作业积压问题。第三,缺乏对导致问题最根本原因的洞察,会导致问题的进一步扩大。
基于 Facebook 的运行实践,大多数固定任务所需的资源数量通常是可预测的。只要应用的逻辑和配置不变,那么任务的资源占用情况也是具有固定模式的。基于这一观察,Turbine 设计了一种主动预测机制。采用此机制的资源管理架构如图 3 所示。架构设计上由资源预估(Resource Estimator)、执行计划生成(Plan Generator)和模式分析(Pattern Analyzer)组成。
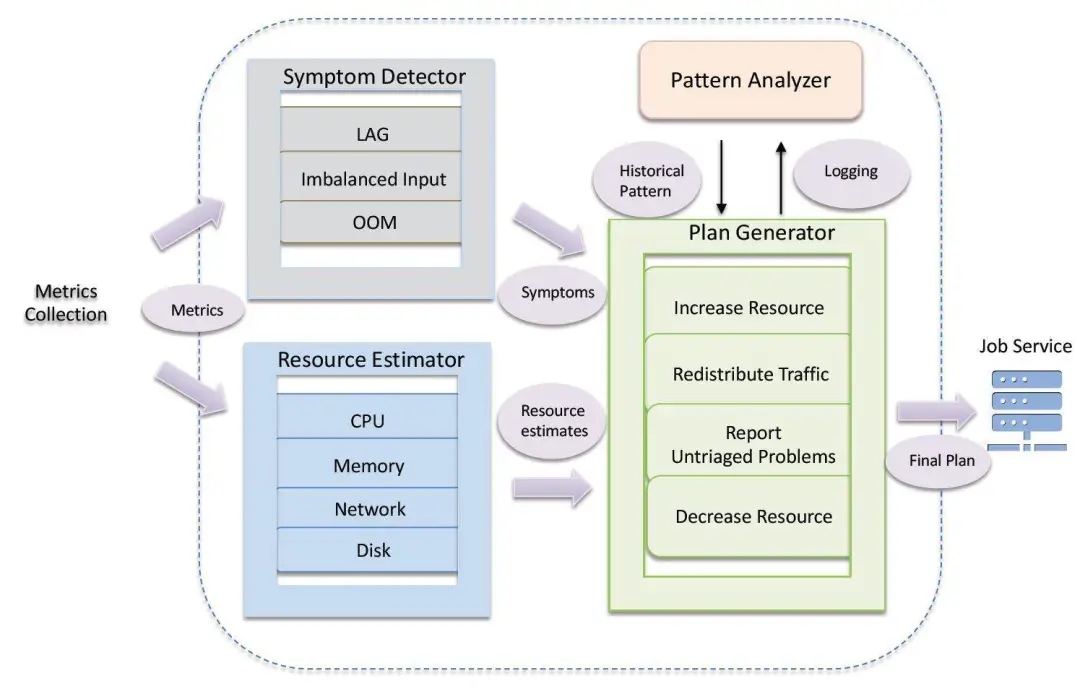
图 3 Turbine 资源管理器架构
资源预估:对给定作业的资源使用情况作出预估。作业可根据处理状态看分为两类,即过滤、投影、转换等无状态作业,以及连接和聚合等有状态作业。无状态作业一般是 CPU 密集型操作,例如输入反序列化、数据处理和输出序列化等,CPU 的消耗情况通常与数据输入输出的规模成正比。由此,可以通过对输入输出的度量,判定单个线程的较大稳定处理率,进而预估 CPU 资源。有状态作业在 CPU 资源之外,还需要预估内存和磁盘的使用情况。其中,聚合运算的内存需求与输入数据的规模成正比,而连接运算的内存和磁盘需求与输入项的笛卡尔积规模以及结果的选择率相关。
模式分析:任务在动态增加、移除或重启时,其初始化通常需要耗费大量 CPU 和 I/O 资源。资源管理器必需考虑此因素,以免初始化操作造成整个集群运行不稳定。为此,Turbine 引入了模式分析,根据现有的数据情况推测资源的占用模式,防止出现可能导致集群不稳定的潜在隐患。模式分析需要记录并分析资源调整情况和历史工作负载模式,确保在资源扩展中不会发生频繁更改资源分配的情况。
容量管理:考虑到 Facebook 数据中心分布在全球范围,容量管理可临时授权不同的数据中心集群间进行资源交换,以达到全球范围内资源的有效使用。容量管理监测集群中作业的资源使用情况,确保在集群范围内各类型的资源得到合理分配。
生产环境实测
本文以 Scuba Tailer 流处理应用为用例,展示 Turbine 生产系统的运行情况。Facebook Scuba 提供时序数据的实时即席查询,主要适用于实时性能问题诊断、处理结构改进影响分析等场景。Scuba Tailer 流处理应用从 Scribe 读取输入数据、处理并将结果返回 Scuba 后端。该应用运行在一个专用的处理集群上。集群中包括位于三个备份区域的两千多台服务器,每台服务器具有 256GB 内存,48 至 56 个 CPU 内核。每个任务的 CPU 占用与数据量近乎成正比,内存占用与消息平均大小近乎成正比。图 4 显示了近 12 万个任务的负载特性。可见约 80% 的任务占用不到一个 CPU 线程,而每个任务需占用近 400MB 存储资源,而 99% 的任务存储资源占用低于 2GB。
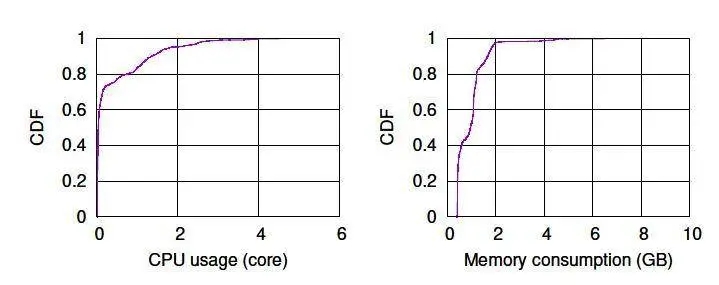
图 4 Scuba Trailer 任务的 CPU 和内存使用统计情况
负载均衡
如前所述,Turbine 监测所有运行中任务的资源占用情况,并将任务调度到所有可用的机器上。图 5(a)和(b)显示了 Tailer 集群一周时间期内的 CPU 和内存使用情况。图 5(c)显示 Turbine 很好地在机器间分发任务,每个机器的任务数变化范围控制在 150~230 小范围内。在 Turbine 上线前,每个 Scuba Tailer 使用独立的容器运行。Turbine 更好地利用了各容器中的碎片化资源,实现了整体资源占用降低约 33%。
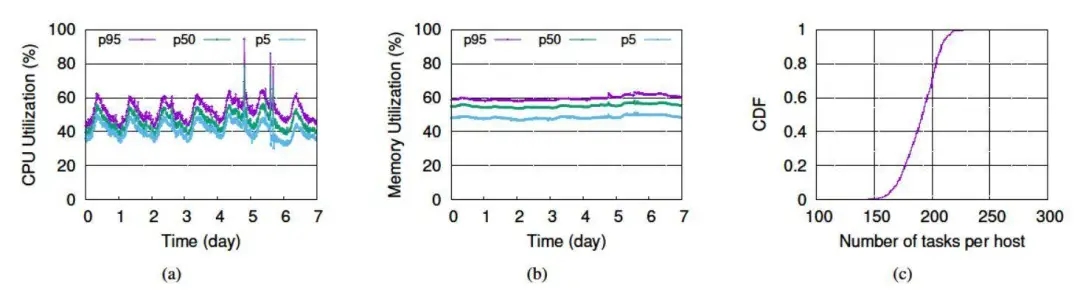
图 5 在 600 多台机器的 Tailer 集群中,各机器的 CPU 和内存使用近乎平均。每台机器维持数百量级的任务运行,其预留资源足以应对输入数据流的突发尖峰。
负载变更响应
Turbine 自动执行资源扩展,确保所有作业具有足够资源,并且整个集群的资源得到有效使用。
图 6 显示了一个任务层面的变更用例。其中,Scuba Tailer 任务由于应用问题禁用了五天,导致数据积压。在应用重新上线后,需要尽快重新处理积压数据。图中紫色曲线显示资源管理将任务扩增到任务上限 32 个,并在手工移除上限后扩增到 128 个。与之相对比,没有使用 Turbine 的 cluster2 集群在两天后才处理完所有积压任务。
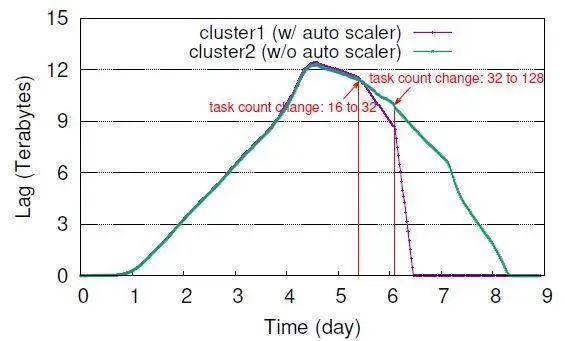
图 6 Turbine 资源自动扩展有助于积压任务的快速恢复
图 7 显示了一个集群层面的变更用例。Facebook 会定期演练灾难恢复,将某个数据中心完全断开连接,该数据中心的所有流量会重定向到另一个数据中心。Turbine 在其中起到重要作用,负责扩展健康可用数据中心的作业资源。图 7 显示了集群任务总数在演练中的变化情况,数据中心断开发生在第二天的早晨,图中紫色曲线整个集群流量相比正常情况峰值增加了约 16%,而总任务数增加了约 8%。这是由于 Turbine 优先考虑做垂直扩展,而非水平扩展。在演练期间及前后,约 99.9% 的作业能保持 SLO。
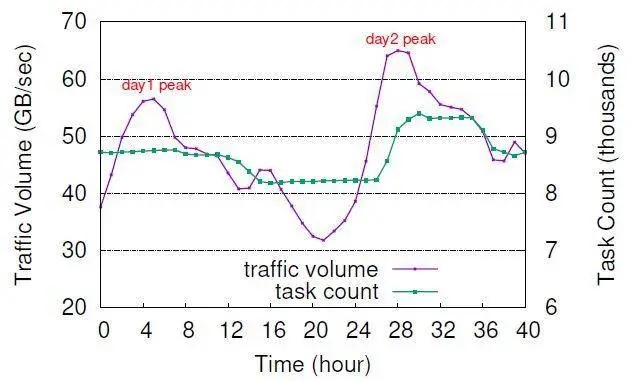
图 7 Turbine 在灾难恢复演练期间的水平扩展情况
总结
近十年间,大规模分布式流处理在多个关键行业得到广泛应用。为解决迅速增长的流处理需求所提出的挑战,需要实现高度可扩展且高度弹性的流处理架构。这也同样是 Facebook 在生产中面对的问题。Facebook 的许多用例采用分布式流处理来获取所需数据,包括推荐系统、网站内容交互分析等,这些应用的大规模实时运行需要达成严格的 SLO。
Turbine 已在生产系统中上线运行近三年,部署在由数万台机器构成的集群中,管理着数千条流水线,每秒实时处理数百 GB 的数据。在 Facebook 的生产经验证明,Turbine 很好地平衡了群集间的工作负载波动,可预测计划之外的负载峰值,持续高效地完成大规模处理。
原文链接:
https://research.fb.com/publications/turbine-facebooks-service-management-platform-for-stream-processing/
声明:文章收集于网络,版权归原作者所有,为传播信息而发,如有侵权,请联系小编删除,谢谢!
欢迎加入本站公开兴趣群
软件开发技术群
兴趣范围包括:Java,C/C++,Python,PHP,Ruby,shell等各种语言开发经验交流,各种框架使用,外包项目机会,学习、培训、跳槽等交流
QQ群:26931708
Hadoop源代码研究群
兴趣范围包括:Hadoop源代码解读,改进,优化,分布式系统场景定制,与Hadoop有关的各种开源项目,总之就是玩转Hadoop
QQ群:288410967
