Uber开源数据流分析平台AthenaX,日均处理1万亿次数据

Uber公司业务的快速增长要求一套数据分析基础设施作为配合,从而时刻收集来自世界各地的广泛分析结论,包括各个城市的特定市场状况以及全球财务流向估算。考虑到我们的 Kafka 基础设施单日实时消息传输超过 1 万亿次,因此这套平台必须:
(1)轻松为各类用户提供导航服务,而无需对其技术背景提出任何要求 ;
(2)以可扩展及高效方式分析实时事件 ;
(3)极为强大,可持续支持成百上千项关键性任务。
面对这样的需求,我们构建起 AthenaX 项目并对其进行开源——这是我们的内部流分析平台,旨在满足上述需求并为每一个人提供可访问的流分析能力。
AthenaX 同时支持着我们的技术与非技术客户,确保其能够利用结构化查询语言(简称 SQL)运行全面的生产级流分析任务。SQL 使得事件流处理变得更为简单——SQL 负责描述需要分析的数据,而 AthenaX 则确定如何分析数据(例如进行数据定位或者对其计算进行规模扩展)。
根据实践经验,我们发现 AthenaX 使得用户能够将原本需要数周方能处理完成的数据流分析工作时长显著缩短至数小时。在今天的文章中,我们将探讨我们为何构建 AthenaX、概述其基础设施,同时详细介绍我们为其开源社区作出的诸多贡献。
Uber流分析平台的演变之路
为了更好地为我们的用户提供具备可操作性的分析结论,Uber必须有能力衡量应用程序活动以及对其产生影响的各类外部因素(例如交通、天气以及各类重大活动等)。2013 年,我们在 Apache Storm 之上构建起第一代流分析管道。尽管效果可观,但这套管道只计算具体指标集 ; 从宏观层面来看,该解决方案消费实时事件,将结果聚合至多个维度当中(例如地理区域以及时间范围等),并最终将结论发布在网页之上。
随着对自身产品的不断扩展,我们发现快速有效的流分析能力变得愈发重要,相关需求亦日趋旺盛。在 UberEATS 服务当中,客户满意度与销售额等实时指标可帮助餐厅更好地了解其业务的运作状况以及客户的反馈意见,并有针对性地优化潜在收益。为了计算这些指标,我们的工程师在 Apache Storm 及 Apache Samza 之上构建起多种流分析应用程序。更具体地讲,这些应用程序负责将多个 Kafka 主题进行投射、过滤或者关联,并利用成百上千套容器提供的资源计算复合结果。
然而,这些解决方案还远远称不上理想。用户要么被迫实现、管理并监控自己的流分析应用程序,要么被限制为仅能从预定义的问题集当中提取答案。
AthenaX 致力于解决这一难题,并通过允许用户利用 SQL 构建定制化、生产就绪型流分析方案获得更理想的使用体验。为了满足Uber业务的规模化要求,AthenaX 对 SQL 查询进行了编译与优化,并将其交付至分布式流应用程序当中以确保仅利用 8 套 YARN 容器即可实现每秒数百万次的消息处理操作。AthenaX 还以端到端方式管理各应用程序,具体包括持续监控其运行状态、根据输入数据大小自动进行规模伸缩,且可顺利在节点或者整体数据中心发生故障时通过故障转移保证业务的正常恢复。
在下一章节中,我们将详尽探讨如何构建起 AthenaX 强大而灵活的整体架构。
利用 SQL 构建流分析应用程序
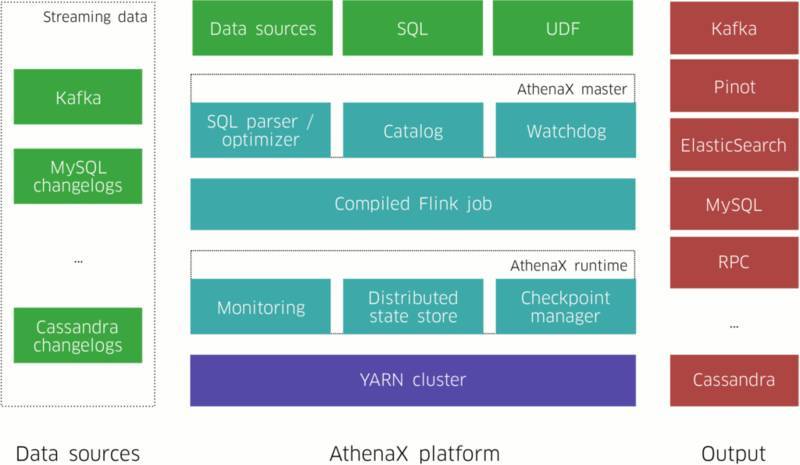
图一:AthenaX 将流数据与查询作为输入内容,计算出结果,而后将结果推送至各类输出内容当中。
在整个演变过程中,我们不断积累经验并最终促成了 AthenaX 的诞生——即Uber本世代流分析平台。AthenaX 的关键特征在于,用户仅利用 SQL 即可指定其流分析,而后 AthenaX 将负责高效加以执行。AthenaX 能够将各查询编译为可靠、高效的分布式应用,同时管理该应用的完整生命周期,这就允许用户仅专注于更为核心的业务逻辑。因此,无论具体规模如何,全部技术层面当中的用户都能够在短短数小时内立足生产环境运行自己的流分析应用程序。
如图一所示,一项 AthenaX 任务会将多个数据源作为输入内容,执行必要的处理与分析操作,而后面向多种不同类型的端点生成输出结果。AthenaX 的工作流程遵循以下步骤:
用户在 SQL 中指定一项任务,并将其提交至 AthenaX 主节点。
AthenaX 主节点验证该查询并将其编译为一项 Flink 任务。
AthenaX 主节点在 YARN 集群中对该任务进行打包、部署与执行。主节点亦负责在发生故障时对任务进行恢复。
任务开始处理数据,所生产的结果被发布至外部系统(例如 Kafka)。
根据我们的经验,SQL 在指定流应用时表现相当出色。以 Restaurant Manager 为例 ; 在这一用例当中,以下查询会计算该餐厅在之前 15 分钟当中接到的订单数量,具体如下所示:
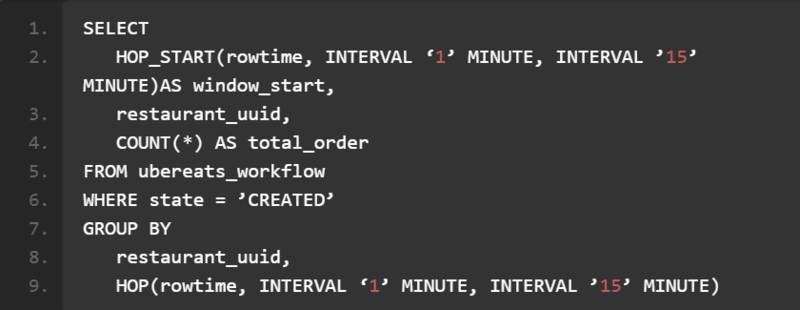
基本上,查询会对 ubereats_workflow Kafka 主题进行整体扫描,过滤出无关事件,并在 15 分钟周期的滑动窗口之内以 1 分钟为间隔进行事件数量聚合。
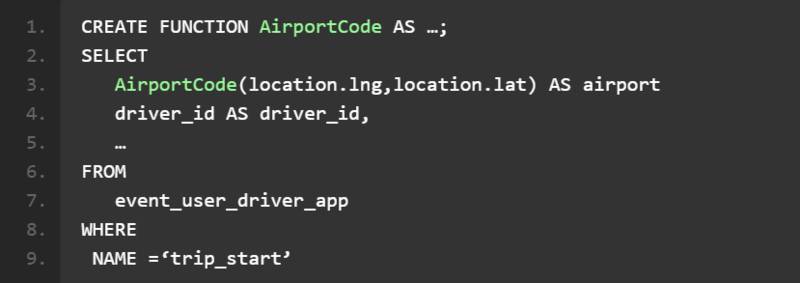
AthenaX 还支持查询内的用户定义函数(简称 UDF),因此其功能性将得到进一步丰富。举例来说,以下查询可利用 UDF 显示特定机场的航班情况,其中经度与纬度将被转换为机场 ID,具体如下所示:
再来看一个更复杂的例子——计算特定餐厅的潜在收入,Restaurant Manager 通过以下方式给出结果:
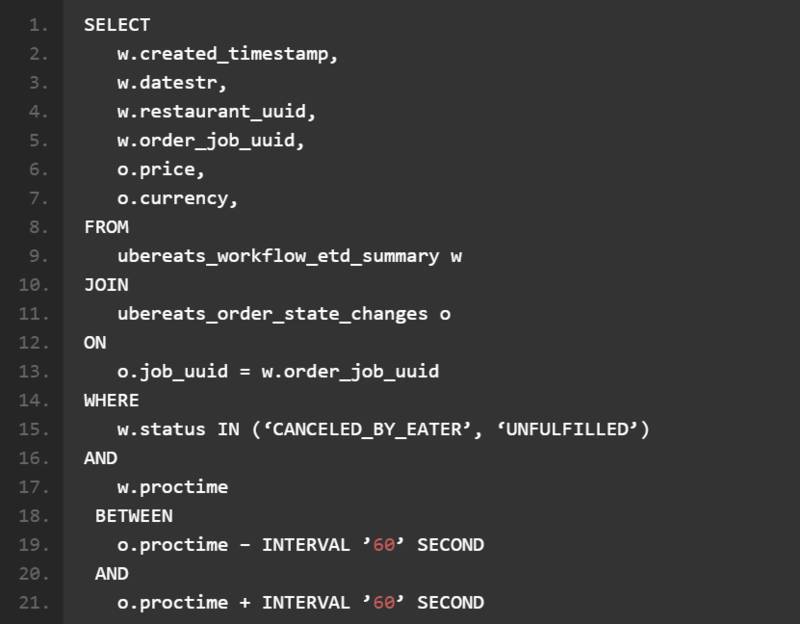
这条查询能够将实时事件及其详细信息纳入订单状态构成,从而计算出潜在收入水平。
我们的经验表明,生产环境当中超过 70% 的流媒体应用可以 SQL 的形式表达。AthenaX 应用程序亦可显示不同的数据一致性保证级别——AthenaX 任务可以采取最多一次、最少一次以及仅一次方式处理各实时事件。
接下来,我们将探讨 AthenaX 查询的编译工作流程。
面向分布式数据流程序进行查询编译
AthenaX 利用 Apache Flink 实现经典 Volcano 方法以进行查询编译,并将结果纳入分布式数据流程序。如图二所示,Restaurant Manager 的编译处理工作流具体包括:
AthenaX 解析该查询并将其转换为一项逻辑计划(图二(a))。逻辑计划属于一套直接非循环图(简称 DAG),用于描述该查询的具体语义。
AthenaX 优化该逻辑计划(图二(b))。在本示例中,此项优化将投射与过滤同流扫描任务绑定在一起。通过这种方式,其可较大程度降低所需关联的数据量。
逻辑计划被翻译为对应的物理计划。所谓物理计划,属于一套包含据位置与并行性等细节的 DAG。这些细节负责描述如何在物理设备上执行该查询。利用这些信息,物理计划可直接映射至最终分布式数据流程序当中(图二(c))。

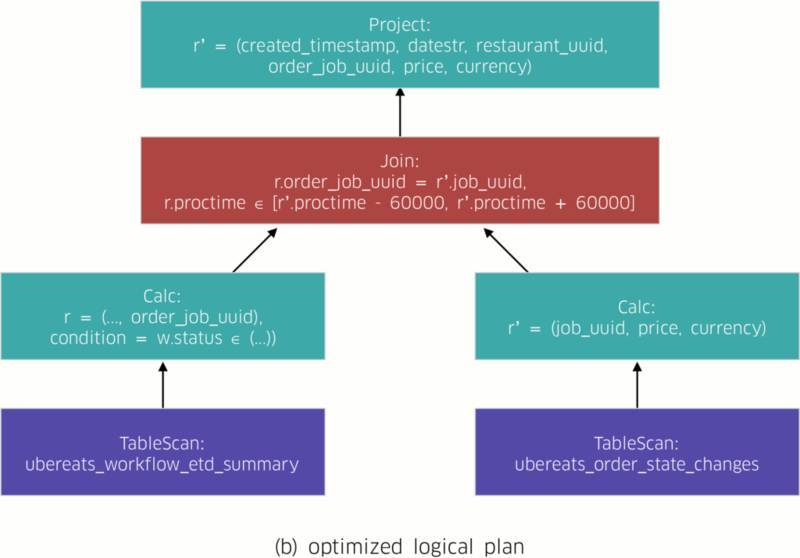
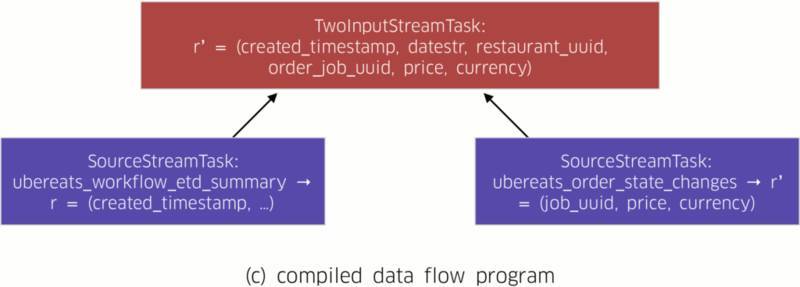
图二:AthenaX 编译流程由一系列 DAG 及节点构成。每套 DAG 负责描述所查询的数据流,每个节点则描述数据流经过时需要执行的任务。图二(a)、二(b)与二(c)显示了 Flink 当中的原始逻辑计划、优化后逻辑计划以及编译数据流程序(为简洁起见,这里省略了物理计划,因为其与图二(c)几乎完全相同)。
在编译过程完成之后,AthenaX 将在 Flink 集群之上执行编译后的数据流程序。这些应用程序能够在生产环境当中利用 8 套 YARN 容器实现每秒高达数百万条消息的处理能力。AthenaX 的处理能力拥有强大的速度与范围保证,足以实现洞察结论的交付,从而为用户提供更理想的体验。
Uber生产环境中的 AthenaX 应用
在为期 6 个月的生产过程当中,当前版本的 AthenaX 在多座数据中心之内运行了超过 220 款应用程序,每天负责处理数十亿条消息。AthenaX 提供多种平台与产品,具体包括米开朗基罗项目、UberEATS 的 Restaurant Manager 以及 UberPOOL。
我们还实现了以下功能以更好地扩展这套平台:
资源估算与自动规模伸缩
AthenaX 根据查询与输入数据的吞吐量来估算所需要的虚拟核心及内存数量。我们还观察到,工作负载在高峰期与非高峰期存在显著区别。为了较大程度提升集群利用率,AthenaX 主节点会持续监控每项任务的标记以及垃圾收集统计信息,同时在必要时加以重新启动。Flink 的容错模型则确保在此期间,各任务仍能产生正确的结果。
监控与自动化故障恢复
相当一部分 AthenaX 任务负责支持管道当中的关键性构建组块,因此要求其实现 99.99% 可用性。AthenaX 主节点会持续监控全部 AthenaX 任务的运行状况,并在发生节点故障甚至数据中心整体故障时对其进行妥善恢复。
展望未来:更简便的流分析实现方式

Uber公司流分析团队——完成了 AthenaX 辛劳的构建工作,他们在镜头前露出了甜美的笑容。后排:Bill Liu、Ning Li、Jessica Negara、Haohui Mai、Shuyi Chen、Haibo Wang、Xiang Fu 以及 Heming Shou。前排:Peter Huang、Rong Rong、Chinmay Soman、Naveen Cherukuri 以及 Jing Fan。
通过使用 SQL 作为抽象手段,AthenaX 简化了流分析任务处理方式,并使得用户能够将大规模流分析应用快速引入生产环境。
为了帮助大家轻松构建起自己的数据流平台,我们在 GitHub 上对 AthenaX 进行了开源,同时亦为 Apache Flink 以及 Apache Calcite 社区作出多项核心功能贡献。例如,作为 Flink 1.3 发行版本中的组成部分,我们贡献了组窗口并支持多种复杂的数据类型 ; 此外,我们还致力于在下一个版本当中共享一套 JDBC table sink。
原文链接:https://eng.uber.com/athenax/
欢迎加入本站公开兴趣群
软件开发技术群
兴趣范围包括:Java,C/C++,Python,PHP,Ruby,shell等各种语言开发经验交流,各种框架使用,外包项目机会,学习、培训、跳槽等交流
QQ群:26931708
Hadoop源代码研究群
兴趣范围包括:Hadoop源代码解读,改进,优化,分布式系统场景定制,与Hadoop有关的各种开源项目,总之就是玩转Hadoop
QQ群:288410967
