Apache Kylin在链家GAIA大数据平台中的实践
GAIA作为链家大数据服务的一站式平台,承接和管理集团几乎全部的数据资源,提供数据治理、数据任务、数据集群三大方向的管理能力,并且肩负着建设链家指标体系的重任,其中指标系统提供便捷自助的数据获取方式和丰富多彩的报表展示样式,很方便业务方、数据分析师挖掘并发挥链家数据的价值。
在链家GAIA大数据平台中,主要使用Kylin做数据引擎,驱动指标平台的数据呈现,本文将详细介绍Kylin在指标平台中的应用实践,也会分享使用Kylin中遇到的问题和解决方案,希望给自主研发BI系统的技术团队,带去一些思想上的火花和实践中的帮助。
GAIA大数据平台通过半年研发,已于进期上线并已内部推广使用,包含指标报表平台、元数据管理、Adhoc查询、任务调度等多个系统。其中指标报表平台负责沉淀和管理链家网的核心指标体系,并且可以快速创建多维报表,支持上卷下钻、维度对比等灵活分析的报表查询。效果如下图所示:

图1 链家GAIA大数据平台 指标平台数据呈现效果
早期数据报表之痛点
在指标报表平台上线之前,链家网在数据分析方面有三个痛点。第一,是面对公司业务的迅速增长,case by case的报表开发难以快速满足用户需求;第二,是缺乏大数据量快速查询、多维度对比分析的工具,用户获取数据后一般在线下进行深入分析,缺乏数据安全的有效管理;第三,是数据指标定义混乱,缺乏统一的管理和权威定义,导致一些数据指标计算结果不一致,让用户产生歧义。
为了解决这些问题,更好地发挥数据的价值,大数据工程团队内来自百度、微博、搜狗的同学通过交流和分享业界经验,先后调研了Impala、Drill、Presto等查询引擎,最后决定使用Apache Kylin 作为指标报表平台OLAP查询引擎。如何做此选择?首先是因为Kylin是基于Hadoop生态的开源分布式分析引擎,能够支持TB级别数据量的亚秒级响应,并在2015年12月成为Apache顶级项目,未来想象空间巨大。其次是业界内已经有京东、百度、美团等等公司在生产环境使用,从各项反馈看都还不错,并且kylin的核心开发团队是中国团队,在未来深入沟通交流时,也能更加方便与及时。
指标报表平台技术方案
通过自研的指标报表平台,用户可以自助配置报表,报表平台会将用户对报表的维度、指标操作转换成SQL发给Kylin API 进行查询,Kylin内部的查询引擎会从HBase获取数据后,返回给报表平台,然后由前端UI进行渲染展示。组成架构如下图所示:
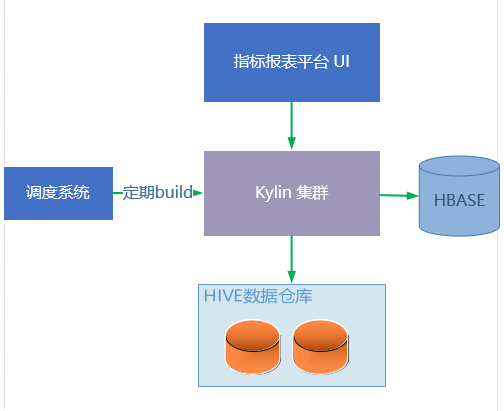
数据分析师会根据业务的需求,经过深入分析和计算,在Hive仓库中构建OLAP星型模型,然后使用Kylin来配置Model和Cube。Cube创建完成后,通过自研的任务调度系统配置定期build Cube的任务和上游的数据依赖,最终在指标平台页面的报表就可以查询到最新的数据。 整个环节流程清晰,不会有太多依赖系统,故而实现成本相对可控,OLAP的数据处理细节,都被封装在Kylin系统中,也让我们更专注精力在建设指标平台上。当然,在上线前的最后冲刺阶段,为了最求更高性能与稳定性,我们也深入到kylin引擎内部,着手调优这套OLAP引擎, 下面为大家介绍具体使用Kylin中遇到的一些问题,以及解决办法。
使用Kylin过程中遇到的问题及解决方案
我们使用的kylin版本为apache-kylin-1.6.0-hbase1.x-bin,对应的hadoop集群为apache hadoop-2.4.1,hbase 版本是1.1.2。在使用Kylin的过程中,遇到过一些问题,这里分享出来,欢迎大家一起交流探讨。
问题一:Kylin SQL查询中遇到的诡异问题,现象描述, 查询sql如下
select
cast(SUM(pv) as double) as pv,
cast( count(distinct user_id) as double) as user_id
from olap.olap_log_accs_page_di
inner join DIM.DIM_LOG_USER_LOCATION on DIM.DIM_LOG_USER_LOCATION.user_city_code=olap.olap_log_accs_page_di.location
where DIM.DIM_LOG_USER_LOCATION.user_region_name in (\&\#39\;华东\&\#39\;)
group by DIM.DIM_LOG_USER_LOCATION.user_region_name
这个sql能执行成功,但仅仅把 in (\&\#39\;华东\&\#39\;) 改成 in (\&\#39\;华东\&\#39\;,\&\#39\;华南\&\#39\;) ,则sql执行报错。错误信息如下所示:
Caused by: Java.lang.NullPointerException
at com.google.common.base.Preconditions.checkNotNull(Preconditions.java:191)
at org.apache.kylin.storage.hbase.cube.v2.HBaseReadonlyStore$1$1.next(HBaseReadonlyStore.java:131)
at org.apache.kylin.storage.hbase.cube.v2.HBaseReadonlyStore$1$1.next(HBaseReadonlyStore.java:99)
at org.apache.kylin.gridtable.GTFilterScanner$2.hasNext(GTFilterScanner.java:88)
at org.apache.kylin.gridtable.GTAggregateScanner.iterator(GTAggregateScanner.java:139)
在发现问题后,我们使用官方提供的sample数据,也能稳定复现。经过反复排查和试验,并向Kylin社区发邮件咨询,在Kyligence公司开发同学的技术支持下,最终定位是hbase 1.1.2版本的bug,该问题详细记录在https://issues.apache.org/jira/browse/HBASE-14269 。定位问题后,我们升级hbase版本后,顺利得到解决。
问题二:对于count distinct 指标,要保证在任意维度和时间范围内的统计准确性,需要配置使用global dictionary。在Kylin1.6版本及以上可以很方便地配置,具体原理参见:http://kylin.apache.org/blog/2016/08/01/count-distinct-in-kylin/,但同时也需要注意一些限制:
由于global dictionary 底层基于bitmap,其最大容量为Integer.MAX_VALUE,即21亿多,如果全局字典中,累计值超过Integer.MAX_VALUE,那么在Build时候便会报错。即使用全局字典还是有容量的限制。
Count distinct指标字段的字符串长度不能超过255,否则在build cube的第四步Build Dimension Dictionary时会报错,错误信息“at org.apache.kylin.dict.CachedTreeMap.writeValue(CachedTreeMap.java:240)”。根据社区jira上该问题相关issue,在Kylin 2.0版本已解决该问题。
如果有多个指标配置global dictionary,那么设置Reuse属性时需要慎重,只有当每次build时第一个指标列的取值都能完全覆盖其他指标列时,才能设置Reuse。否则,在build的时候会报错“ org.apache.kylin.dict.AppendTrieDictionary:Not a valid value:”。
问题三: 当Cube维度个数超过20后,数据量急剧增长,build时间也很长,需要进行优化。实际测试如下,一张用户访问日志olap事实表,原始hive表一天数据量大小 600M,选取20个维度, build cube 后数据量达到 20G,且build耗时300分钟。为了加快build速度和优化存储空间,对cube进行了一系列优化设置:把20个维度按照业务分析组合拆分成3个Aggregation Groups ,同时将cardinality 很小的维度列放在一起配置成 Joint Dimensions。
经过优化后,build速度降到200分钟,数据量也降到15G左右。在早期使用指标平台时,新用户常常会提出许多维度上的需求,这块也需要尽量沟通充分,让用户制定有效有限的维度方能让Kylin性能发挥到最佳。
在分享了上面的几点问题与解决办法后,这里也分享一下Kylin目前版本的限制,帮助刚开始使用Kylin的技术朋友,尽量避免因为这些限制导致研发的反复。
Kylin目前版本存在的一些限制
在应用kylin的过程中,逐步熟悉目前版本建立cube的规则后,需要对数据仓库中建立OLAP模型有一些限制。接下来总结目前我们遇到的问题,供大家在创建事实表与维表时加以借鉴。
1、 事实表中的不同维度字段不能关联同一张维表
在很多情况下同一张olap表中,可能会有多个相同类型的维度字段。比如用户所在地和用户访问地两个维度,需要关联同一张城市维度表。但是由于创建model时,关联的维表只会出现一次,两个同类型字段不能关联同一张维表。目前有两种解决方案,一是对该维表建立视图,两个字段分别关联维表和维表的视图。二是根据字段的业务属性,建立不同的维度表,不同的字段关联不同的维表。这两种方式同样都会增加建模时的复杂度。
2、不同维表中的字段名不能相同
在某些情况下不同维表中的字段含义可能相同,比如经纪人表和客源用户表中的名称字段可能都叫 name。在创建cube选择维度时,由于kylin用字段名进行了去重,导致其中一张维表中的name字段会被过滤掉。目前的解决方案是不同维表中的字段根据业务含义命名,譬如经纪人表的name命名为agent_name,客源用户表的name命名为cust_name。
3、修改cube 增加维度时会造成cube元数据不同步
当修改一个cube增加新的维度字段后,cube build能成功完成。但是当查询语句中包含该新增加的维度时,会报如下错误:Not a valid ID。该维度并未包含在cube的元数据中。所以在使用kylin的过程中,应尽量避免在cube上做修改,建议新建cube或者clone cube后进行修改。
4、cube并行build问题
Kylin1.6开放了并行了build的功能,但是当对某些字段设置了global dictionary后,在Build Dimension Dictionary时可能会问题。并行build时应避免同时进行这一步。
GAIA指标平台上线后效果
指标报表平台上线后至今,刚刚一周多时间,目前已构建10个Cube,配置了20多张指标报表,每天新增数据量200G,90%以上的数据查询在1s内返回,UI层面支持用户上卷下钻、多维度多指标对比分析。
目前的指标平台,有效的填充了之前公司内这块的空白,提供了全公司内统一的指标、维度的定义与管理,提供了具有在线分析能力的指标数据查看能力,并且结合GAIA大数据平台权限系统,有效控制了各项数据的查看权限,在保障了数据安全的同时,提供了数据查询的方便,是一剂推进链家进入数据时代的强心针。
GAIA指标平台与Kylin的展望
随着GAIA大数据平台在集团内的推广,使用指标报表平台的用户逐渐增多,未来有望支持到全公司所有职能部门,也有可能在未来将这套系统普及到链家十五万经纪人手中,指标系统必将会是公司内核心的数据系统,Kylin在该系统中的价值绝不一般。
Kylin在大数据量和页面响应效率上的确表现良好,虽然在构建Cube中也存在一些限制,但相信Kylin团队会继续完善,期待新的版本包含更强大的功能。近期关注到Kylin团队即将发布的2.0版本会大幅提升数据构建速度,我们也将时刻关注2.0的正式版发布。
关于指标报表平台在接下来的迭代中,会尝试支持相同纬度下的跨cube join,让用户查询数据的范围更宽广更灵活,同时也会简化cube的配置,方便分析师快速配置cube并产出报表。在最近几个月中,我们也会将历史查看数据明细的能力,集成到GAIA指标平台中,很多将要实现的功能正在项目组内开展,希望未来有机会与大家做更详细、更新一步的分享交流!
作者介绍
李世昌,链家网资深研发工程师,先后负责链家网Merlin系统、指标系统、数据权限系统等,负责大数据平台应用研发团队,对大数据BI系统、Data Streaming有一定研究。
张如松,链家网高级研发工程师,2015年加入链家网,参与大数据平台多项目研发工作,负责GAIA指标平台引擎部分工作。
欢迎加入本站公开兴趣群
软件开发技术群
兴趣范围包括:Java,C/C++,Python,PHP,Ruby,shell等各种语言开发经验交流,各种框架使用,外包项目机会,学习、培训、跳槽等交流
QQ群:26931708
Hadoop源代码研究群
兴趣范围包括:Hadoop源代码解读,改进,优化,分布式系统场景定制,与Hadoop有关的各种开源项目,总之就是玩转Hadoop
QQ群:288410967
