综述:集成染色质状态与转录组数据的调控网络建模
分子生物学的中心法则指出了从DNA编码基因到RNA再到蛋白质的遗传信息的流动方向。一个基因被转录为RNA时,我们称之为“表达”。基因调控网络,即对基因表达水平进行精准控制的蛋白与DNA间相互作用。在发育生物学中,人体不同细胞组织具有相同的 DNA 序列, 却具有迥异的基因调控网络,导致在某一特定的组织或细胞类型中,只有部分基因被转录表达,这些组织和细胞特异的基因表达调控不但塑造了细胞和组织的表型,而且包含了对环境扰动做出应答的重要机制,因此也是健康和疾病研究领域的基石。对基因表达调控网络的研究,需要对遗传信息(DNA序列所提供的信息)和表观遗传学信息(提供了何时、何地、以何种方式去应用遗传信息的指令)进行建模和集成。由美国斯坦福大学王永雄教授作为通讯作者、中国科学院数学与系统科学研究院王勇副研究员,清华大学自动化系江瑞副教授联合撰写、发表于《国家科学评论》的综述文章“Modeling the causal regulatory network by integrating chromatin accessibility and transcriptome data”介绍了这一方面的最新进展。
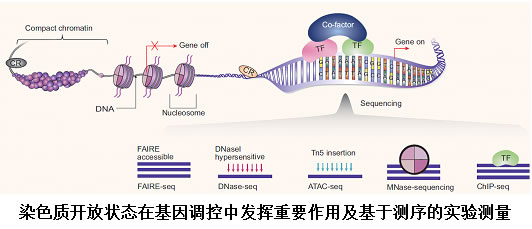
文章着重于对相对容易获取的染色质开放状态和基因表达数据的联合建模。在通常的基因调控模型中,作者用一维的ATCG四个字母(核苷酸)组成的序列来简化基因组DNA。事实上,基因组有着复杂的空间三维结构。例如人类基因组包含64亿碱基对,直线长度为2米多,是哺乳动物细胞核平均直径的200,000倍,要将它包装到细胞核内,需要致密的缠绕在核小体蛋白上形成三维结构。这是一种高效的信息压缩和编码方式,导致了染色质不同区域具有处于“开放”或“关闭”状态两种状态。处于“关闭”状态的染色质,被称为异染色质(heterochromatin),在异染色质蛋白以及修饰酶的作用下,被包装成致密,紧凑的结构,阻遏转录因子等蛋白的结合,处于一个沉默失去生物功能的阶段。而处于“开放”状态的染色质,被称为常染色质(euchromatin),具有不太紧致的结构,可招募转录因子等蛋白的结合。通常基因只有处于开放状态时才能表达,位于非编码区域的调控元件如增强子(enhancer)也只有处于“开放”状态才有可能参与对其他基因或区域的调控作用。近年来,测序技术的发展已经产生出大量实验手段(代表性的有DNase-seq, ATAC-seq, FAIRE-seq, ChIP-seq和MNase-seq)可在全基因组范围内测量染色质的开放状态,尤其是人类基因组计划之后的“DNA元件百科全书”计划 (Encyclopedia of DNA elements,简称ENCODE)和表观组学路线图计划(Roadmap Epigenomics Mapping Consortium,简称ROADMAP)的开展,极大地推动了数据的积累。
作者们特别注意到ENCODE和ROADMAP计划中部分细胞类型具有匹配的染色质状态和基因表达数据,这部分数据对于研究多层次数据集成和基因调控网络建模,提供了非常有针对性的数据资源。文章针对这些数据开展讨论,回顾了当前的主要实验手段和原理、已有的数据类型和资源,当前几个重要的计算问题,多层数据集成的数学模型,以及生物学应用,最后聚焦数据分析中新的契机,并提供了展望。
作者认为之前的基因调控的定性定量化研究和网络推断进程,主要是由基因芯片和后来的RNA-seq技术推动的,而单纯从表达水平层面的研究,受到了”维数灾难”等困难的制约。而全基因组染色质状态数据的出现,引入了表达水平的上游信息,为研究调控开辟了新的角度。特别是可以定量刻画位于非编码区域的基因的调控元件(包括启动子、增强子和绝缘子等)的状态,从而理解它们的调控功能。这些非编码区域里的调控元件对实现组织细胞特异的表达模式有重要的作用,对解释基因组突变的生物学功能具有重要意义,是精准医学和个性化医疗的重要基础。作者认为引入染色质状态数据,并与基因表达数据集成进行集成建模,将有助于提供更精确的调控因果关系的预测以及回答一系列基础性的问题:这些调控元件处于基因组中哪些位置?在哪些特定条件下调控元件开放并具有活性?哪些转录因子结合于这些元件?这些元件调控哪些下游基因?有活性的元件如何定量影响基因表达?调控元件上的变异如何影响其功能?总之,通过发展新的数学模型的计算方法,解读这些重要的数据,将极大地促进我们对后基因组时代基因调控网络的理解。(来源:科学网)
