BioInformatics:北京基因组所章张研究组开发国际基于Spark的大数据
2016年10月14日,国际学术期刊《BioInformatics》在线发表了中国科学院北京基因组研究所生命与健康大数据中心章张研究员的一篇研究论文,研究报道了首个基于Spark的大数据系统发育建树工具CloudPhylo。博士研究生徐行健为论文第一作者,章张研究员为论文通讯作者。
构建系统发育树是分子进化研究中分析物种间进化关系的基础步骤与重要环节。随着生物大数据时代的到来,传统的建树工具在使用大数据集构建系统发育树时需要消耗更多的计算资源且运行时间超长,使得科研工作者无法快速高效地进行分子进化分析。为此,生命与健康大数据中心(BIG Data Center;http://bigd.big.ac.cn)利用Spark云计算技术,于近期开发了一款适用于大数据集的系统发育树构建工具——CloudPhylo。Spark是一种新的分布式云计算框架,它实现了MapReduce分布式并行算法。基于Spark框架的程序在运算过程中可高效地将中间输出结果保存在内存中,大大降低了因为频繁读写文件造成的损耗。因此,与传统的Hadoop框架相比,Spark能更好地应用于需要反复迭代的大数据分析任务。
CloudPhylo是目前国际上首款针对大数据集开发的系统发育建树工具,同时也是国内首个使用Spark云计算技术开发的生物信息学分析软件。在应用于模拟和真实的大数据集构建系统发育树时,CloudPhylo均表现出了比传统建树软件更高的运行效率和更大的并行加速比(图1)。
工具已经部署在BIGD云平台Qomo(https://cloud.big.ac.cn/users/bigd/tools/Clouldphylo)上,无须本地安装,用户可在线提交数据并进行分析。
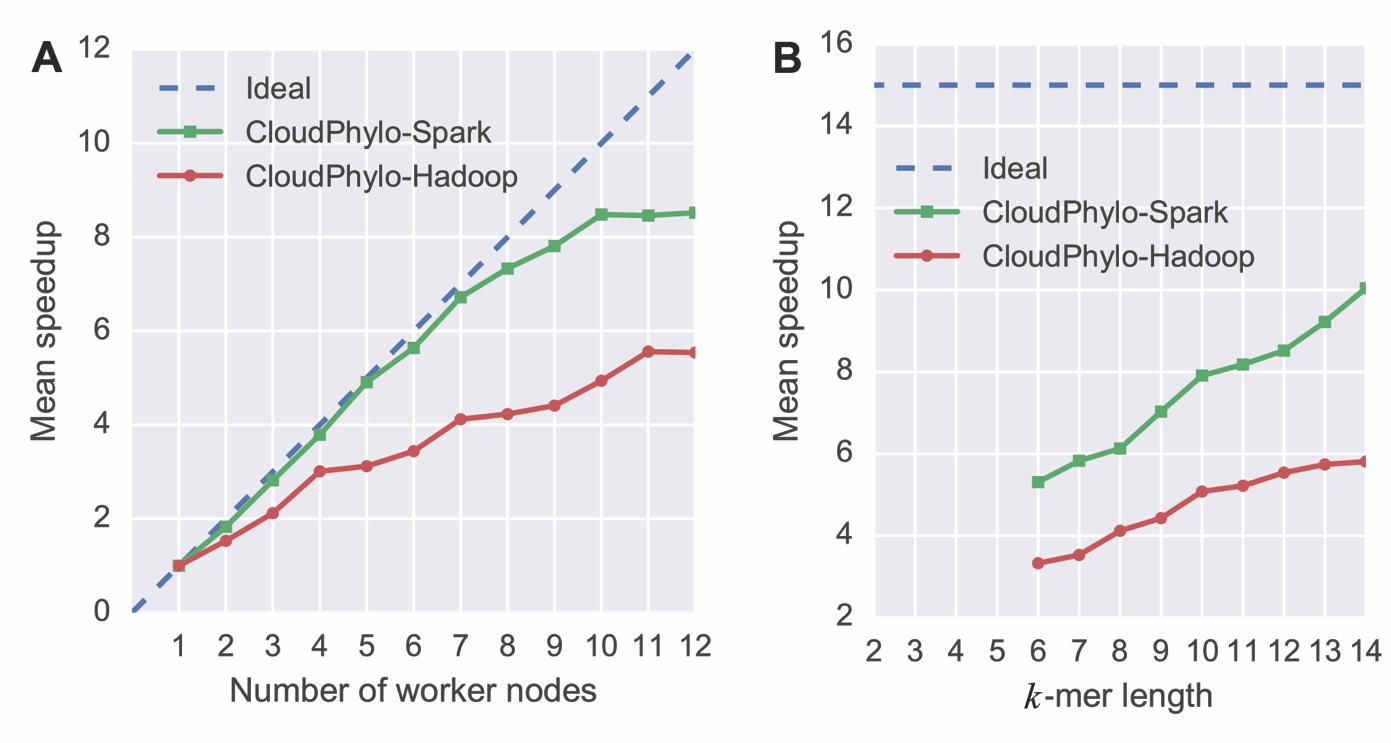
图1 CloudPhylo在不同条件下的并行加速比
原文链接:
CloudPhylo: a fast and scalable tool for phylogeny reconstruction
原文摘要:
Summary: Phylogeny reconstruction is fundamentally crucial for molecular evolutionary studies but remains computationally challenging. Here we present CloudPhylo, a tool built on Spark that is capable of processing large-scale datasets for phylogeny reconstruction. As testified on empirical data, CloudPhylo is well suited for big data analysis, achieving high efficiency and good scalability on phylogenetic tree inference.
doi:10.1093/bioinformatics/btw645
作者:章张
