大数据技术深观察:从具体场景说开去
科技的日新月异让大数据技术逐步完善,相关的行业和公司也都对这片蓝海虎视眈眈。那这项技术的应用场景到底在哪些方面,而其中的哪些技术又是走在行业前端的呢。本文将就以上内容简要分析。
这几年,随着大数据技术的日益成熟,越来越多的公司和产品引入大数据技术;同时也有越来越多的大数据技术、框架以及产品被推向市场;目前大数据产品市场已进化到V3.0,产品繁多,数不胜数。

这个现象充分说明了大数据技术的发展速度之快和大家对该技术未来发展的信心;但这也给一个企业或者产品开发决策者带来了更多的选择困境。本文试图从“用户行为分析系统”的应用场景出发,结合技术落地过程的一些经验和感受,给广大的技术决策和爱好者一些亲身的建议;当然技术本身没有好坏之分,只有适不适合之说,文中技术描述有不到位的地方,敬请指出,不胜感激。
应用场景无处不在
用户行为分析系统主要通过收集用户的行为数据(功能使用信息、操作行为信息、按钮点击事件信息等等),会话加工、业务建模、数据分析甚至数据挖掘等业务技术流程来统计分析用户的行为,形成各类统计指标和分析结果供运营决策。简要流程见下方:

技术难题催生解决之道
在不同的阶段,运用的技术和方案也不尽相同。首先来看看在实践过程中用到的一些技术和遇到的一些问题。
1、数据采集阶段
在该阶段由于涉及的数据来源方式的多样性,如前端SDK发送、日志、数据库等;各种方式的处理方法和技术不尽相同。
一般SDK技术由于客户端的不同而不同,不在此处赘述。
日志文件数据的采集可通过推送或抓取两种方向不同而方式不同,像公司的T2日志filterlog、java的log4j等均可以通过推送至数据接收端的方式进行,市面上主要的技术是由flume/flume-ng(高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统)采集至kafka来解决或ELK(elasticsearch+logstash+kibana)来解决。
但是这两种方案主要存在的问题是对前端发送数据无法保证完整性和一致性,毕竟该方案在网络闪断、服务异常、超过上限阈值等情况下容易导致数据丢失,特别是需要有完整性需求时(如提供日志中心服务、日志文件还原服务等),需要慎重考虑;由于历史遗留问题,需要建立对接产品的日志中心服务,提供日志文件的存储、还原及下载服务,我们采用的更为保守的Socket双向数据确认服务来保证日志的完整性;也可做到有效控制对客户机资源消耗的管控(当然对数据一致性要求不是特别高的应用场景,这几种方案都是可以考虑的)。Socket双向数据确认服务主要处理流程见下方:
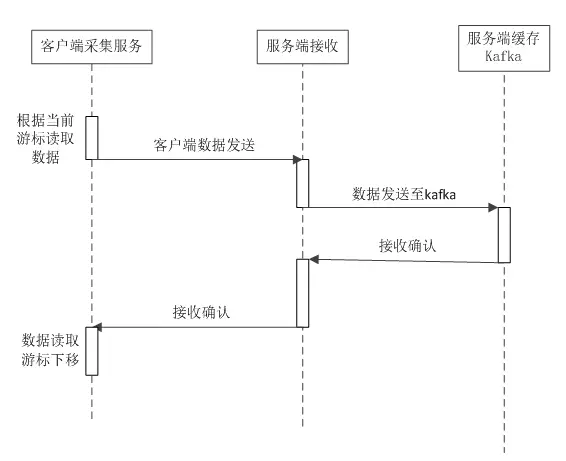
数据库数据层面的数据采集根据数据库的不同技术也不太相同,目前公司2.0业务使用较多的RDS(MYSQL)的数据采集可以考虑研发中心的斗转星移产品;当然,更为通用的解决技术如kettle也是可以考虑的技术之一,只是对于开发投入等会较前面的产品更为大一些。
2、数据接收阶段
在数据接收阶段,主要考虑的是高并发和高可用;这阶段的技术主要通过kafka集群作为缓冲来解决这两块问题。当然,前端通过SLB加后端多接收负载均衡来达到高可用;实时流式的数据应用一般通过实时流式计算框架JStorm来实现。
Kafka主要有如下特点是一种分布式的,基于发布/订阅的消息系统。主要设计目标如下:
1、以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。
2、高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
3、支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
4、同时支持离线数据处理和实时数据处理。
这里主要需要关注的点是:
1、kafka只能保证在同一个partition内的消息顺序传输,多个partition内的消息无法保证顺序传输;在需要顺序传输需求时需要保证只使用一个partition;
2、SLB的负载均衡通常判断后端服务是否存活的依据是后端端口是否存在,当后端架设nginx等此类服务时需要特别小心,经常会引发后端服务挂掉但nginx服务还存活时,SLB无法正确进行判断进而转发至有效后端服务的情况。
3、数据存储、建模、数据统计分析阶段
Hadoop大数据平台主要的存储数据格式/方式有hdfs、hbase、redis、es/solr等;hdfs主要在存储的数据不需要更改的情况下使用,如日志文件等非结构化数据等;hbase主要解决数据的可修改性和基于rowkey的快速查询的应用场景,当然通常配合es/solr来优化多字段查询;es/solr主要作为小数据量内存应用的场景。
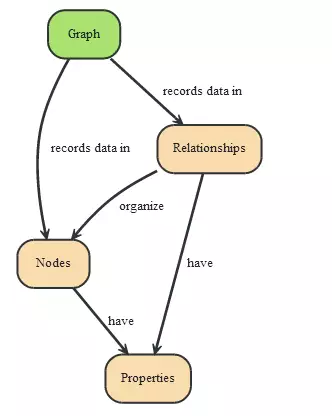
对于对象间的关系模型的存储,Neo4j图形化数据库是首选的解决方案。Neo4j是一个高性能的、NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。
程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是它们可以享受到具备完全的事务特性、企业级的数据库的所有好处。Neo4j因其嵌入式、高性能、轻量级等优势,越来越受到关注。
它主要解决图形数据结构问题;在一个图中包含两种基本的数据类型:Nodes(节点) 和 Relationships(关系)。Nodes 和 Relationships 包含key/value形式的属性。Nodes通过Relationships所定义的关系相连起来,形成关系型网络结构。
4、结果数据存储、展示阶段
这部分数据通常需要结合最后的报表等展示系统的查询特性,一般有关系型数据库或者NOsql数据来承担这样的角色。基于Mysql的RDS或者是Mongodb、cassandra等都是不错的选择。在多维度的较大结果数据的存储上,mysql需要结合分库分表方案,mongodb需要结合分区分片等技术。
用户行为系统任重道远
一套安全、高可用、高灵活性的系统涉及的周边需求和技术还有很多,比如硬件监控、业务监控、快速扩展、高效部署、灰度升级等方面的需求结合SEE平台、Azkaban、docker技术等不再扩展描述。
上述的一些技术和应用案例也只是基于用户行为分析系统的实践过程中的一些积累,就像文首描述的一样,目前的技术更新和演进越来越快,我们的用户行为系统的实践也仅仅只涵盖了一小部分技术和内容;在建设过程中踩过很多坑,填过很多坑;欢迎同行能够提一些建设性的意见和建议,让我们一起成长。
欢迎加入本站公开兴趣群
软件开发技术群
兴趣范围包括:Java,C/C++,Python,PHP,Ruby,shell等各种语言开发经验交流,各种框架使用,外包项目机会,学习、培训、跳槽等交流
QQ群:26931708
Hadoop源代码研究群
兴趣范围包括:Hadoop源代码解读,改进,优化,分布式系统场景定制,与Hadoop有关的各种开源项目,总之就是玩转Hadoop
QQ群:288410967
