大数据 - R语言数据可视化 1
发表日期:2016-06-28 09:45AM 阅览次数:
一.学习目标
数据科学及需要具备的知识和技能 了解数据的特征 数据可视化: R的绘图系统 制作并发布报告 (markdown, 制作数据报表)二.环境安装与R Stdio
R for windows 环境: https://cran.r-project.org/bin/windows/base/R-3.3.1-win.exe
三.数据科学家需要具备的技能
Hacking Skills 计算机知识 Math & Statistics 数学统计知识 Substantive Expertise 生物方面知识(可选) 医学方向| 职位 | 包含 | ||
|---|---|---|---|
| 数据开发者 | 开发者 | 工程师 | |
| 数据研究者 | 研究人员 | 科学家 | 统计学家 |
| 数据创造者 | 什么都要会一点 | 艺术技能 | 黑客技能 |
| 商业职位 | 领导者 | 企业家 |
四.数据分析流程
初步流程 st=>start: 流程开始 e=>end: 结束 op=>operation: 定义研究问题 op2=>operation: 定义理想的数据集 op3=>operation: 确定能够获取什么数据(与资金相干) op4=>operation: 获取数据(开始行动) op5=>operation: 清理数据(只选取关心变量) ed=>end: 结束 st->op->op2->op3->op4->op5->ed 实际操作 st=>start: 操作 e=>end: 结束 op=>operation: 探索性分析(数据可视化) op2=>operation: 统计分析, 建模, 机器学习等 ed=>end: 结束 st->op->op2->ed 尾声 st=>start: 流程 e=>end: 结束 op=>operation: 解释, 交流结果(以可视化为前提) op2=>operation: 挑战结果(是否遗漏?) op3=>operation: 书写报告(Reproducible原则) ed=>end: 结束 st->op->op2->op3->ed 驱动方式 : 假设驱动 (Hypothesis Driven) 学术界较多 驱动方式: 数据驱动(Data Driven) 商业工业界较多 推荐假设驱动五.数据基础
观测, 变量, 数据矩阵
变量: 数值 -> 连续, 离散.(可进行计算, 加减乘除求平均等) 分类 -> 取值空间有限, 不能计算(加减乘除) > 有序, 无序六.数值变量的特征和可视化1
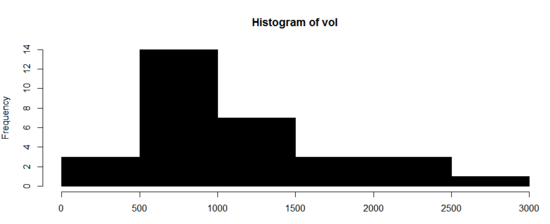
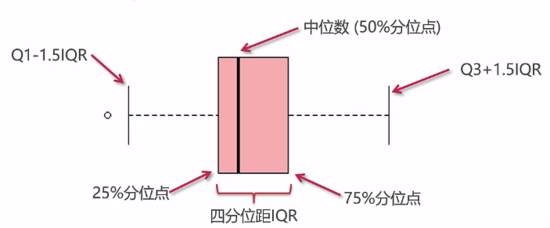
数据集中趋势的测量: 均值, 中位数, 众数分散趋势: 值域, 方差, 标准差, 四分位距
操作实践: 打开 R stdio, 新建R script 输入 x <- c(1,9,2,8,3,9,4,5,7,6) 点击 run
有:

六.数值变量的特征和可视化2
稳健统计量 是: 中位数, 四分位差(受极端值影响小)否: 均值, 标准差, 值域(受极端值影响大)
一个变量的可视化 柱状图(正太分布),点图(分布) 一般统计分析需要满足正太分布 其他: 左偏分布, 右偏分布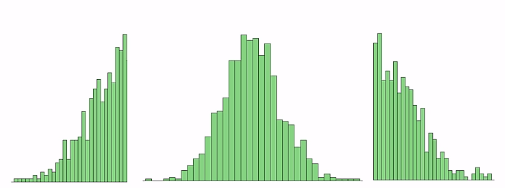
七.分类变量的特征和可视化
一个分类变量的可视化
频率表 条形图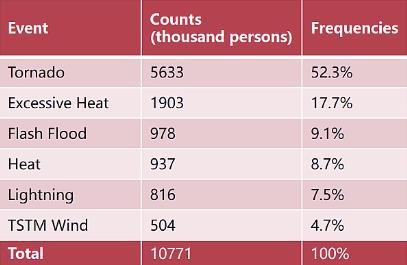
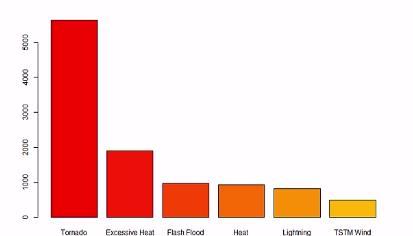
两个分类变量的关系
关联表, 相对频率表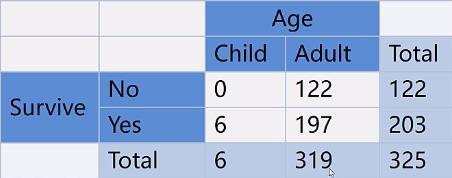
注意: 相关不代表因果

