认知应用:大数据的下个转折点
这篇文章是一个投资者对数据分析在过去25年的回顾。作者西蒙迪斯从投资者的角度讨论了数据分析的变革,认知应用的价值,以及最受风投关注的大数据核心领域。
在我的之前的一些博客中,我提到了生成认知的必要性和重要性,并提供了一个认知应用的例子。我始终认为认知应用是对于希望通过挖掘大数据从而改进决策和解决重要问题的公司的关键所在。为了更好的理解和领会开发这类应用的必要性,考虑在大数据领域正在发生什么,并且评估我们在商业智能系统上的经验,及它应该如何驱动我们理解认知应用是十分重要的。
由于我认为认知应用是大数据发展的下一个转折(参见最近使用IBM Watson平台建立的这类应用举例),我将要在一系列博客中进一步探讨这个话题。在这篇博客中,我对于数据分析在过去25年的演变进行了观察。,特别是当我们来到大数据时代,开发认知应用是必然之举。在第二篇博客中,我将更为详细地描述这类应用,并且提供一些例子。在第最后的第三篇博客中,我将讨论投资者对认知应用的兴趣,并描述我最近对这一领域的创业公司的投资。在这些博客中,我的分析和理解均基于本人作为三十多年的企业家、量两分析应用创业公司的创始人以及在这一领域进行了15年投资的风险投资人的经验。
数据分析在过去25年
随着过去25年中数据量的大幅增加,针对决策制定的数据理解都由两个步骤组成:创建数据仓库以及理解数据仓库的内容。
数据仓库以及它的前身—企业数据仓库、数据市场等,是构造专业数据库所必须的基础架构。这些数据可能来自于一个单独的数据源(例如客户关系管理应用的数据库)或者来自整合过的一系列不同的数据源(例如将一个客户关系管理应用的数据库和一个包含每个客户的社交媒体交互数据的数据库整合起来)。这些数据可能是结构化的(例如货币被描述为每个用户支付的数量)、非结构化的(例如一个客户和一个服务专员之间以文本形式的交互内容)。专业化数据是那些一旦被抓取,就是干净的、有标签的、并且自动地或被(比人们认为更频繁地进行)人工描述的。
在过去几年里,我们已经通过大量使用开源软件、云计算、商用硬件等来降低数据仓库的开销,并进一步改进我们管理更多样、大量和高速产生的数据的能力。我们已经从只有诸如金融服务的花旗银行以及零售业的沃尔玛之类的大公司才能负担的、千万美元开销的数据仓库转向对于中小型企业可以负担得起的数据仓库。最近,低开销的服务提供方,诸如亚马逊的Redshift,谷歌的BigQuery,甚至是微软的Azure,已经把数据仓库移到云上。最终,数据仓库对于普通企业来说都是可用的。
随着数据仓库的崛起,数据分析报告的交付已从打印转向数据化
数据理解的第二步涉及到通过数据分析来理解数据仓库的内容。在商业环境中,这往往是通过报告和关联的可视化来完成,有时候也会使用更加定制化的可视化和诸如神经网络的机器学习算法(机器学习虽然并不是新概念,但几乎从数据仓库作为数据存储和管理工具出现开始就被使用)。
随着数据仓库被更多的各行各业的公司所采用,我们见证了可以创建的报告的形式的逐渐改变,报告被展现给分析师和决策者,以及准备报告的人。在早期(80年代末90年代早期),商务智能报告由技术专员创建,他们也是通过向数据仓库提供函数和查询来得到报告。这些报告被封装(例如,它们可以被修改,但是有很大难度,且只能被同一个创建报告的技术专员所修改),并在计算机打印纸上呈现。后来,尽管这些报告仍然被封装,它们可以在电脑上通过专门的报告程序来呈现,再后来,可以呈现在包括智能电话和手持终端运行的网络浏览器上。近年来,查询创建和报告撰写的任务从技术专员转交给了商业用户。然而,尽管查询和关联的报告变得更快、更灵活、被更广泛的使用,这些报告的主要用户——商业分析师们,仍然困扰于在大量信息中发现在报告中存在的最简单的模式。最重要的是,这些用户纠结于基于报告所包含的信息应该决定采取什么行动(参见图1的例子)。

图1关于复杂的数据模式和可视化的一些常见的例子,图片由Evangelos Simoudis提供
随着更多数据的产生,我们已经可以更有效地管理数据所带来的开销,但是仍然挣扎于进行有效的数据分析
受到全球因特网的普及,它所带来的网络连通性的驱动,物联网之类的新领域产生的前所未见的海量数据,以及基于这些所创建的大量应用,使得我们被数据所淹没。快速数据和慢数据,简单数据和复杂数据,所有这些数据都是前所未有的大量。数据的量变的多大了呢?我们已经从在2014年产生大约5泽字节的非结构化数据到2020年将增加到大约40泽字节的非结构化(参见图2)。
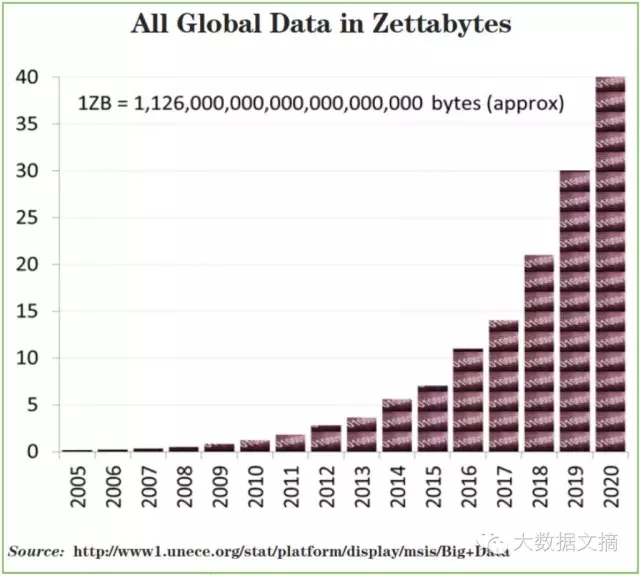
图2 非结构化数据在2005至2020年的实际和预期增长对比,图片由Evangelos Simoudis提供
特别是在上一个十年间,随着数据量变得更大,企业的IT策略核心变为用很少的资源做更多的事。公司的数据仓库开始面临两大问题。第一,其中的一些系统不能有效地管理所获取的海量数据,因而数据不能被应用有效的利用。第二,开销变得不能承受的高,成为数据管理方面另一大挑战。
与此同时,当新一代的数据管理软件(例如Hadoop)被谷歌、雅虎等重量级科技公司开发出来,一些“部分”解决方案开始出现。一开始,这些软件在商用硬件上运行,并且很快开源,从而使得企业可以以较低的开销来解决它们的大数据问题。Cloudera, Hortonworks以及一些其他提供开源软件服务的公司在大数据基础设施领域扮演了重要角色。我将这些解决方案称为“部分”是因为在管理数据的同时,这些系统并不包含企业所使用数据仓库系统的那些复杂的、专用的功能。但是这些新系统擅于构建数据湖泊,适用于多样化的大数据环境,并旨在通过更低的开销替代或增强某些类型的数据仓库。
尽管我们有效管理大数据开销的能力得到了改进,但是我们分析数据的能力,不计开销的情况下,仍然没有提升。尽管大众媒体宣称从数据中得来的认知结果将是新的石油(或金子,挑选你喜欢的隐喻),但市场研究公司IDC预测,到2020只有很少一部分采集的数据会被分析。我们需要分析更多抓取的数据,并从中提取更多的信息。
我们正在致力于改进我们分析数据的能力,但是面临着数据专业人员的短缺
为了收集和分析更多的数据,同时不放弃报告的生成,我们开始广泛采用机器学习和其他基于人工智能数据分析技术的自动化的信息抽取方法。然而,这些方法要求使用一类新的专业人员——数据科学家。尽管我们看到数据科学家的数量潮涌般增加,但是我们需要更多,并且,与正在产生的数据相比我们永远不能提供足够的数据科学家。麦肯锡(http://synapsepartners.co/ideas/)曾估计,到2018年,美国将面临(大约14万至19万缺口)人才缺口,这些人拥有可以从收集的数据中提取认知结果的深度分析技能。我们还将缺少大约150万拥有量化分析技能的、可以基于数据科学家生成的大数据分析来做出重要商业决策的经理。
机器学习改进了我们发现数据中关联性的能力,但做出决策的要求的时间变短了,而数据产生的速度增加了
商业智能是一个出现了近40年的领域。统计分析和机器学习技术被使用的时间则更长。在这一时期,我们已经提升了我们从数据集中识别关联性的能力,但是做出决策的时间要求正在变短,而数据产生的速度不断增加。举例来说,公司的首席金融官们可能有一个月的时间来创建金融预报,然而一个自动的在线广告平台只有仅仅10毫秒的时间来决定把哪一个数字广告展现给特定的用户(参见图3)。此外,一个首席金融官仅需要参考几十亿字节的数据就可以得出决策,而在线广告系统不得不分析万亿兆字节的数据,大部分的数据还是近实时生成的。
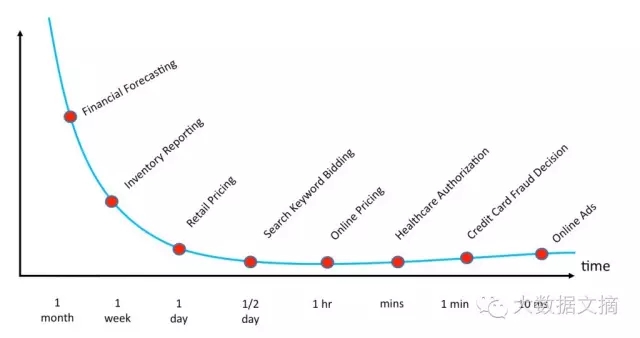
图3 各行业做出决策需要的平均时间示意,图片由Evangelos Simoudis提供
在一些应用领域,简单地识别出数据集中的关联性对做出决策来说已经足够。在其中一些高价值高投资回报的领域,通过数据科学家和其他专业人员来从大量数据中抽取信息是合理且必要的。计算机安全威胁检测以及信用卡欺诈检测就是两个这样的领域。在这些领域里,作出决策的时间是非常短的,做出错误决定(过度保守)的代价,至少最初并不是非常高。将一个交易视作欺诈或者将一个行为视为安全入侵的代价也很低(例如持卡人的不便或是对于系统管理员的一些网络取证)。但是,没有检测到在已建立的行为模式中的异常的代价将会更高。
为了跟上大数据的节奏和改善我们对信息的使用,我们需要能快速而廉价地抽取相关性并将其与行动关联起来的应用
考虑到预期的数据科学家和具有量化分析能力的商业用户的短缺,以及我们迫切的继续挖掘已经收集到的海量数据的需求,我们要能更好地开发分析应用,使其能够生成认知并关联到行动上。这类应用,被我称为认知应用,将超远胜于从数据中抽取相关性。
我们已经在数据理解上取得了很大进展。我们已经降低了管理大数据的开销,与此同时改进了我们分析和提取关键信息的能力。但是,大数据的增量过快以至于我们不能通过更快或者更灵活的查询以及报告来紧跟步伐。我们需要能够创建廉价快速的可执行认知能力,特别是通过使用认知应用。我将在下一篇博客中更加完整地讨论这一主题。
来源:O\&\#39\;Reilly Data
作者简介
Evangelos Simoudis

Evangelos Simoudis是一位经验丰富的风险投资家和国际化企业的高级顾问。他的投资生涯开始于15年前在Apax Partners,随后在Trident Capital。最近Evangelos与他人共同创立了Synapse Partners,一家风险资本和企业咨询公司,并担当总经理。Synapse投资尚处于起步阶段的为企业开发大数据应用的公司。他是一个公认的在企业创新、大数据、云计算和数字营销平台的先驱,他经常在这些主题的发表演讲、做出贡献。在2014年,他被称为数字媒体领域的“强力玩家”,并在2012年被认为是一个顶级的在线广告投资者。在投资和咨询生涯之前,Evangelos有超过20年的高科技行业的决策管理经验,负责运营、市场营销、销售和研发。他是两家初创公司的首席执行官。Evangelos是加州理工学院信息科学与技术顾问委员会成员,布兰迪斯大学科学委员会成员,布兰迪斯大学国际商业学院的咨询委员会成员,纽约城市科学中心和规划咨询委员会成员。Evangelos在布兰迪斯大学获得计算机科学博士学位以及在加州理工学院获得电子工程硕士学位。Evangelos的博客:synapsepartners.co/ideas/
欢迎加入本站公开兴趣群
软件开发技术群
兴趣范围包括:Java,C/C++,Python,PHP,Ruby,shell等各种语言开发经验交流,各种框架使用,外包项目机会,学习、培训、跳槽等交流
QQ群:26931708
Hadoop源代码研究群
兴趣范围包括:Hadoop源代码解读,改进,优化,分布式系统场景定制,与Hadoop有关的各种开源项目,总之就是玩转Hadoop
QQ群:288410967
